-
-
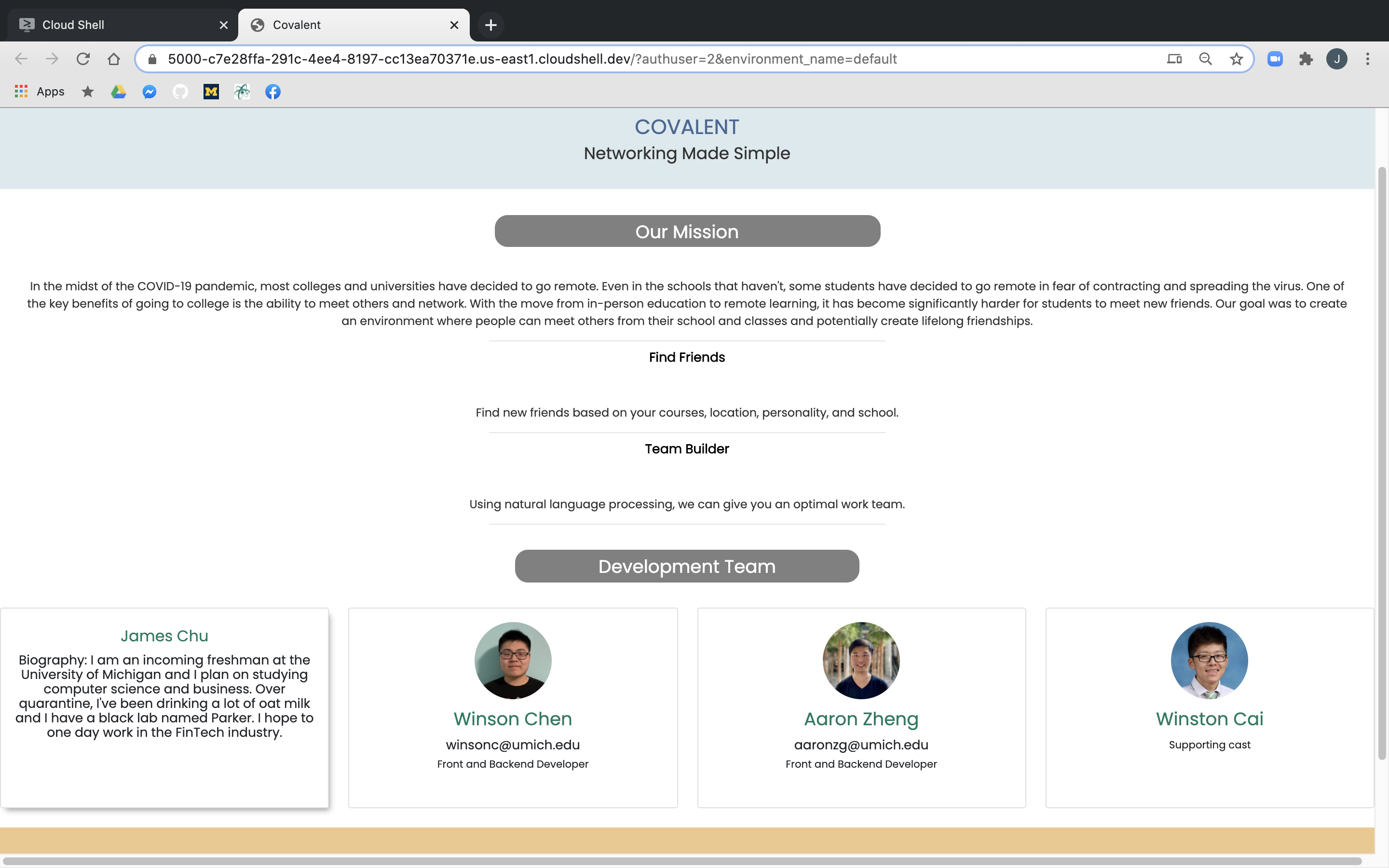
Our welcome page! We are proud of adding flipping to our team cards!
-
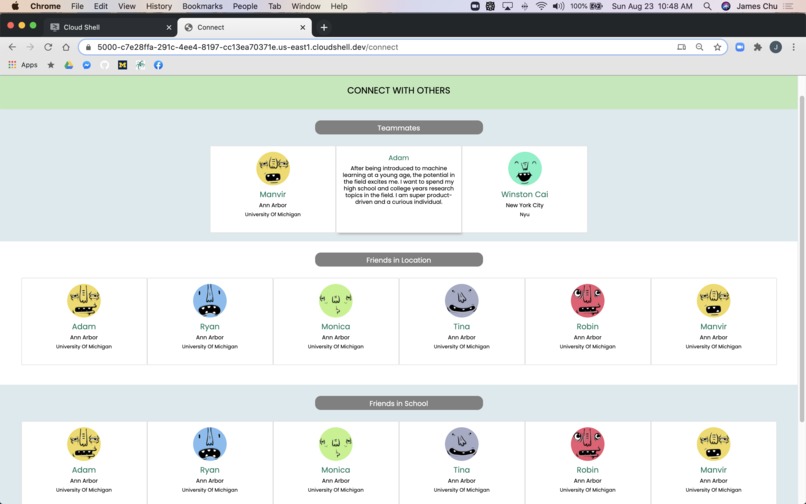
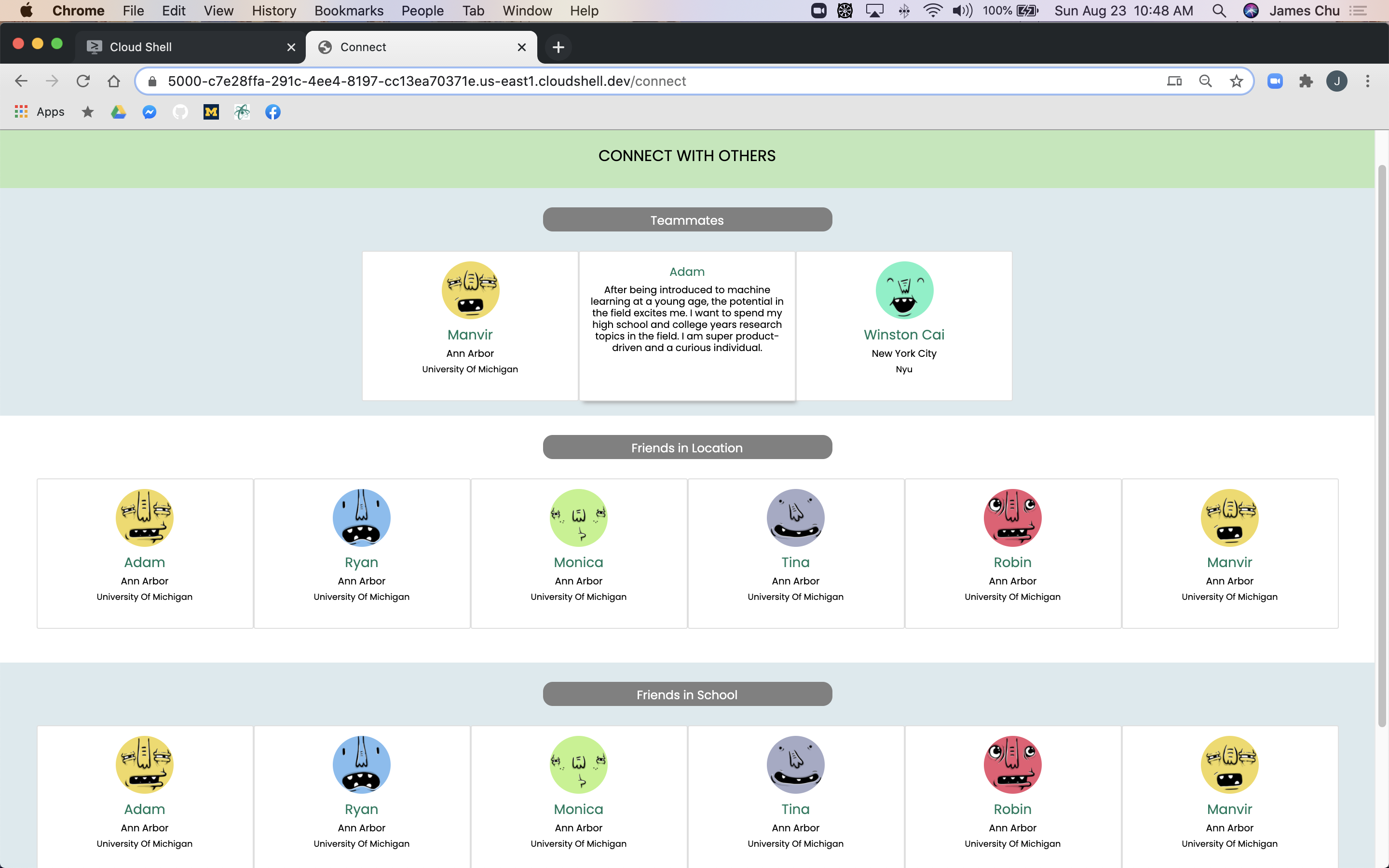
Our connect page! This page shows off your ideal teammates that we paired by using NLP. It also displays users in your school and location!
-
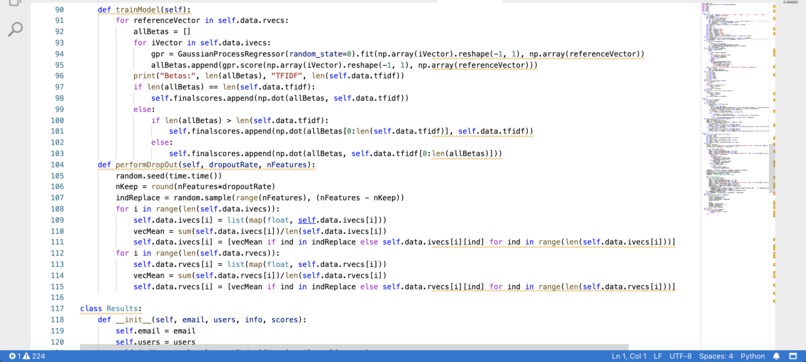
We leveraged NLP and ML to create our team building algorithm.
-
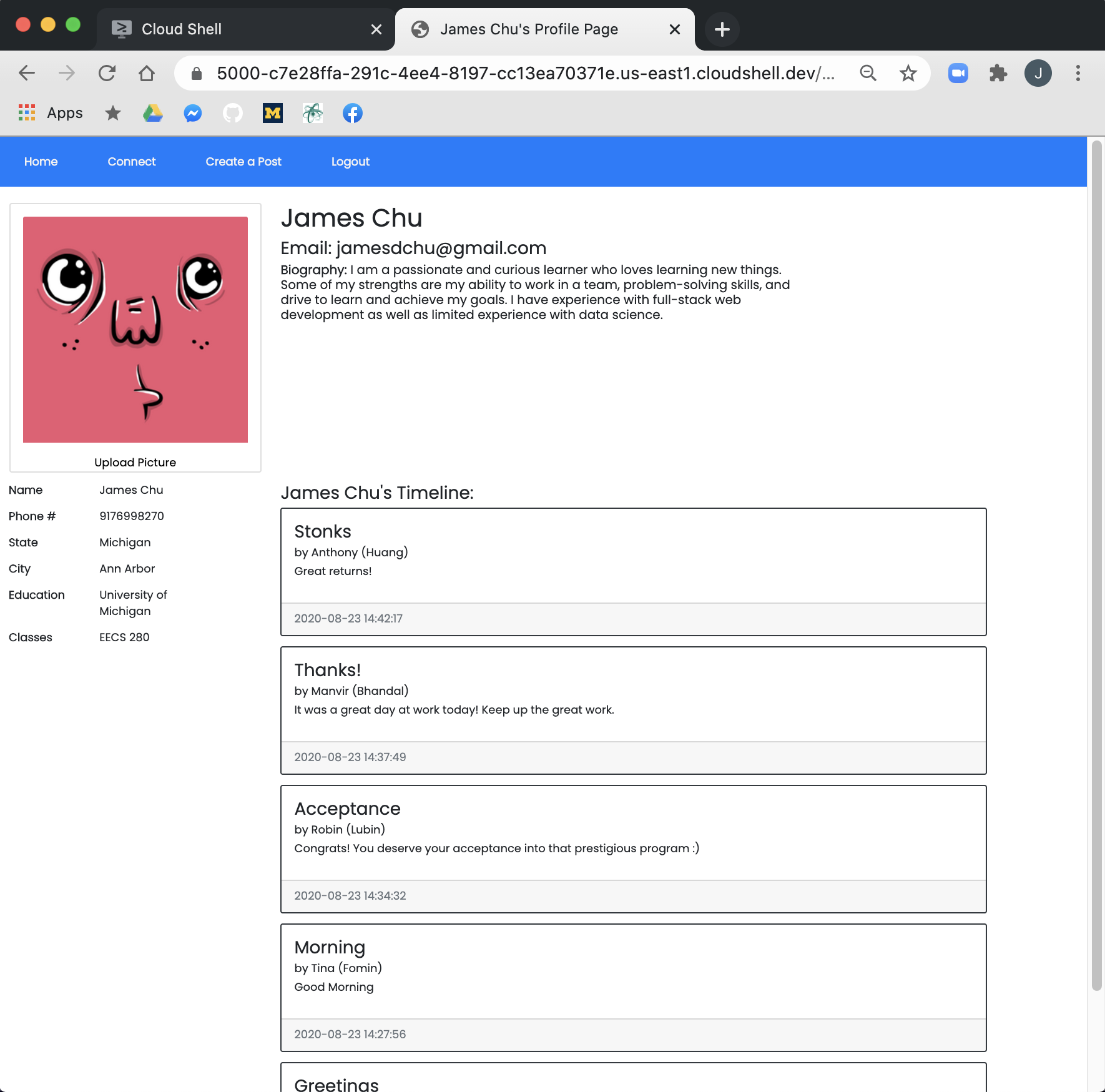
Our profile page template! We are proud of our timeline that gets automatically updated! We added functionality to post on other timelines
-

We generated random avatars using an API instead of uploading images to make the process of signing up quicker.
-
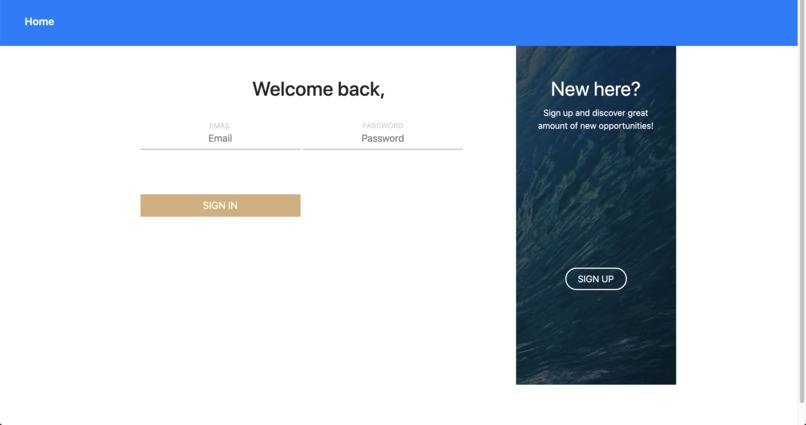
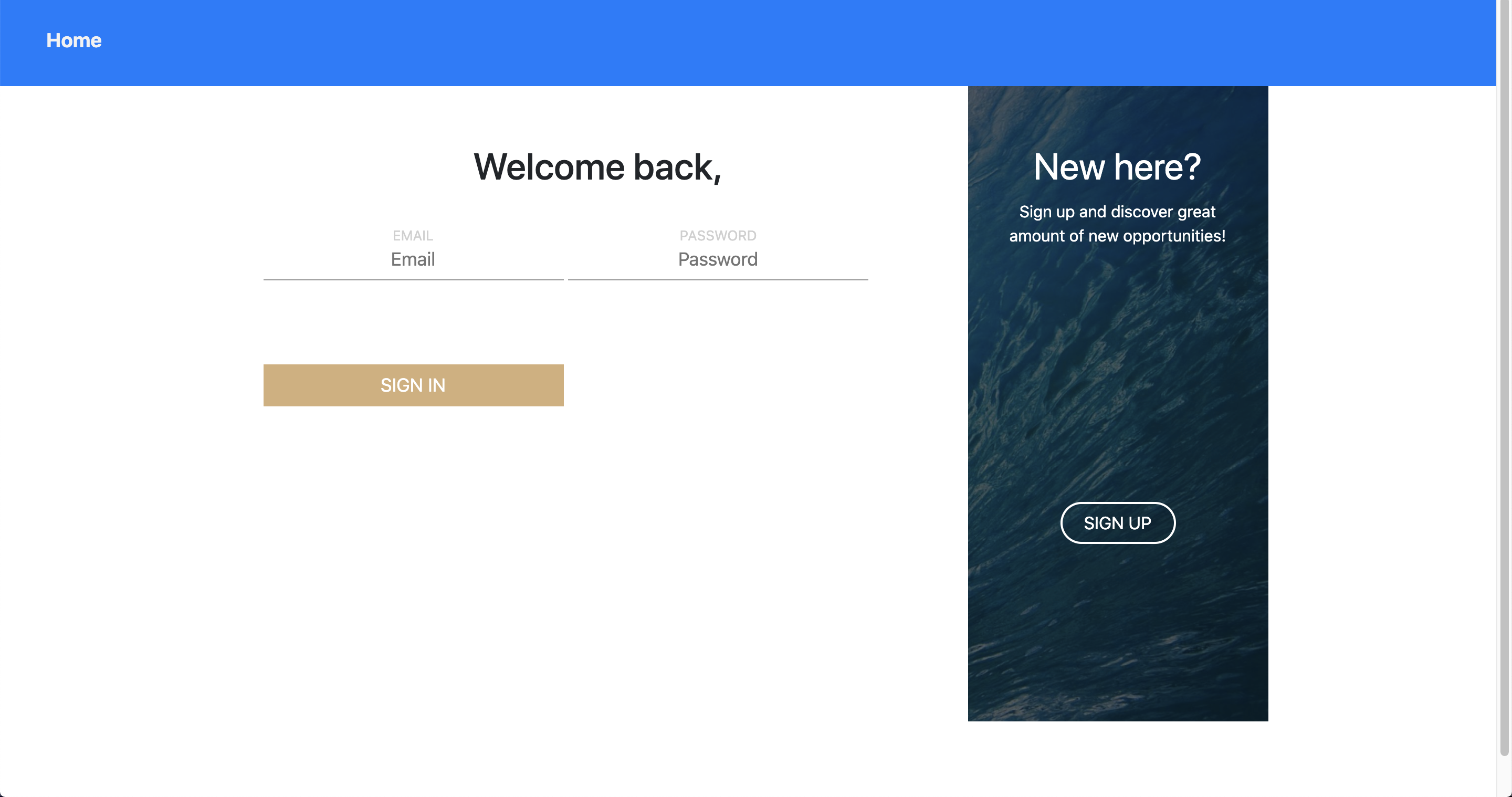
Our log in page! We are proud that we managed to animate the image on the sides to slide over, changing it from sign up to log in.
-

We spent a lot of our front end developing time on the sign up and log in pages. It was also rewarding to get the backend to work here.



Inspiration
2020 has brought upon us an unprecedented global situation. Workplaces have been disbanded, schools have gone remote, and almost all social activities have dramatically decreased. Many students and workers have been forced to work remotely. Despite all the technologies at our disposal, there are still many drawbacks to our current systems. We aim to address a critical issue: team-building among students and people in the workforce and connecting people based on their interests and attributes. To this, we present Covalent: a full-stack web application that leverages natural language process with the word2vec neural network technique and machine learning in Gaussian process regression.
What it does
In the limited 36 hours, with less than 6 hours of sleep per person T-T, we managed to give Covalent a multitude of different applications. Covalent can effectively assign users a set of teammates (up to 4) to work with. It can also connect people based on their information like school, location, and classes to name a few. Users are also given the opportunity to update their information to get better suggestions for teams and connections. On top of that, we built profile pages for each user consisting of basic information, a profile picture, and a timeline that users can post on.
How we built it
From the get-go, we had a general outline of our website and that outline solidified into various pages as we moved along. To build the web application, we first brainstormed our name, goals and how we were going to accomplish our goals. After setting up the GitHub repository and linking GitHub to Vscode and cloning the repository we started working. We also had to set up our MongoDB database and download the required extension on VScode. We created HTML pages for the main functionalities that we wanted to put in our project. This included the home page, login/signup page, profile page, and feed page. For connecting to the backend, we used flask and MongoDB to store our users information. We had 4 main collections to store our data in an organized manner. As for the algorithm, we split it into several layered steps. We used the Big 5 (Openness, Conscientiousness, Neuroticism, Extraversion, Agreeableness) and Myers-Briggs to generate the optimal team. To do this, we first loaded in the embeddings for the web and selected the words that appeared in our users’ inputs. For each unique word, we calculated the term frequency-inverse document frequency to give us the first weight for determining the importance of each word for the user. We then regressed every integrated vector (word2vec embedding) for each unique word against the integrated vector of our main team building traits. The result of this would be 2 sets of weights for each user in each team category. We performed the dot product of these two sets of weights to obtain a user score for each team building category. Finally, the highest category score was used to optimally match the user with the other users in our entire Database.
Challenges we ran into
As beginners in programming, we ran into errors that provided us with valuable learning experiences. We ran into several merge conflicts with GitHub which allowed us to boost our understanding of the terminal command line and git itself. Additionally, our multi-step algorithm took us significant time to perfect. We used trained embeddings from the Common Crawl and Google Web Archive that were contained in huge files. We had to improvise to improve our runtime since extracting these vectors for the words took some time itself. We also had to adjust our model in the event our data or user input was noisy and messy. We solved this problem by utilizing the ever useful method of dropout training. Dropout training would help improve our results and reduce overfitting. We randomly sampled 70% of our features and replaced them by the population mean to ensure an optimal model.
Accomplishments that we're proud of
Given that we are beginners and new to ML and developing web applications, we were especially proud of our ability to grasp important concepts in machine learning, python, and front-end development. We also valued our performance working as a team and effectively distributing our tasks. Some more specific accomplishments that we’re proud of are our user timelines, our encryption methods that we used to protect user info information, some of our front end features (our log in/sign up page!), and our team building algorithm that leveraged NLP and ML.
What we learned
As leading scientists of the future, we are able to think about creative solutions to global issues and are motivated to explore new fields of interest in any way possible. For most of our team, this was our first forays into web development and programming in general. We started off learning how to navigate through terminal and connect our code through GitHub, so all our teammates were connected. In the limited time that was offered, we grinded the HTML and CSS courses on Codecademy and dove into a bit of Javascript as well. We split the learning tasks evenly to maximize our time. Two of our group members focused on front-end with HTML, CSS, SCSS, and Javascript. The other two members of our group focused on learning how to connect the frontend to the backend with various technologies, frameworks, and databases including flask, MongoDB, Google Cloud Shell, Firebase, and bcrypt and use various machine learning methods with TensorFlow, Keras, and Scikit Learn. Under the pressure of a deadline, we worked diligently on Zoom calls and successfully divided the tasks among our team members.
What's next for Covalent
Despite being new to the scene of computer science, we are heavily goal-oriented. We believe that we can further enhance our web application by pushing our web application past language barriers, helping teams effectively tackle problems by adding a logging system for issues, and giving team members and friends clear directions for better overall communication. Given more time and deep thinking on our web application, we firmly believe our product has the potential to be something big.


Log in or sign up for Devpost to join the conversation.