-
-
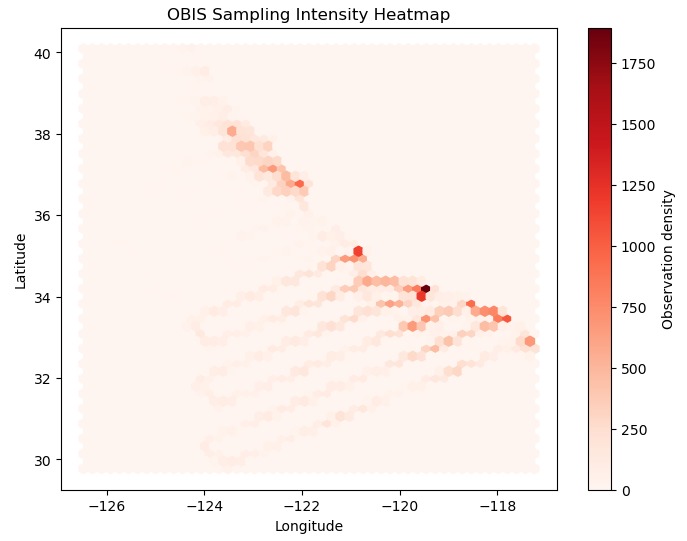
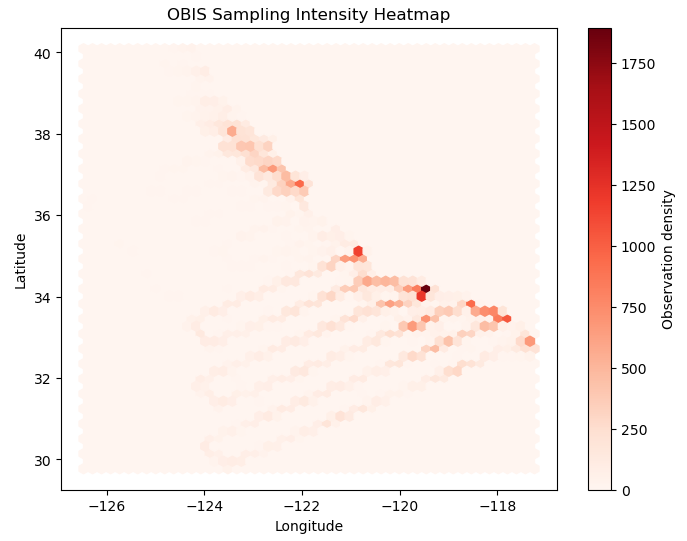
Visual 1
-
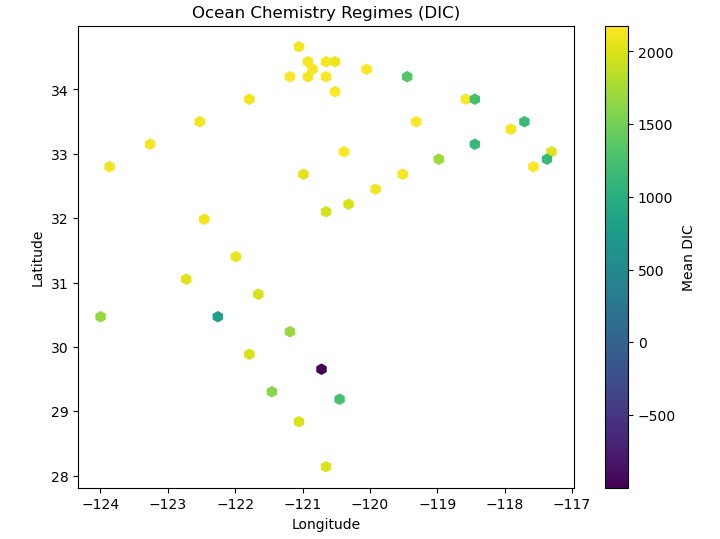
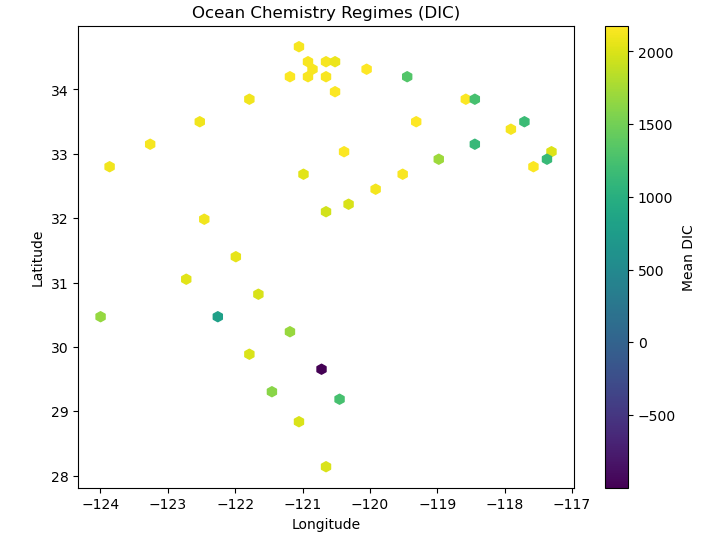
Visual 2
-
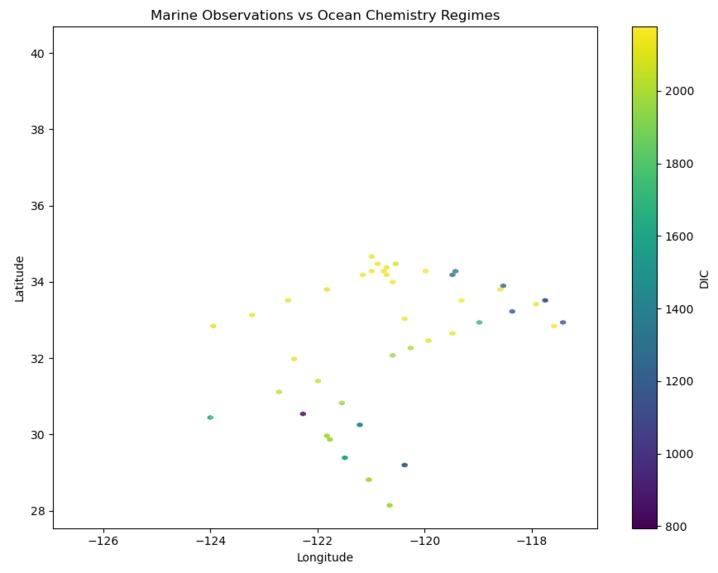
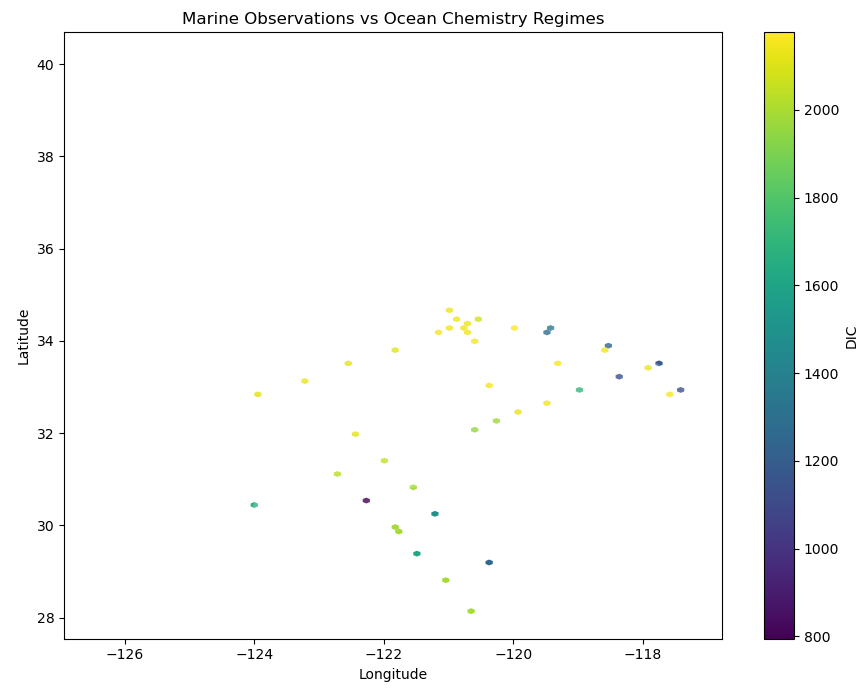
Visual 3
-
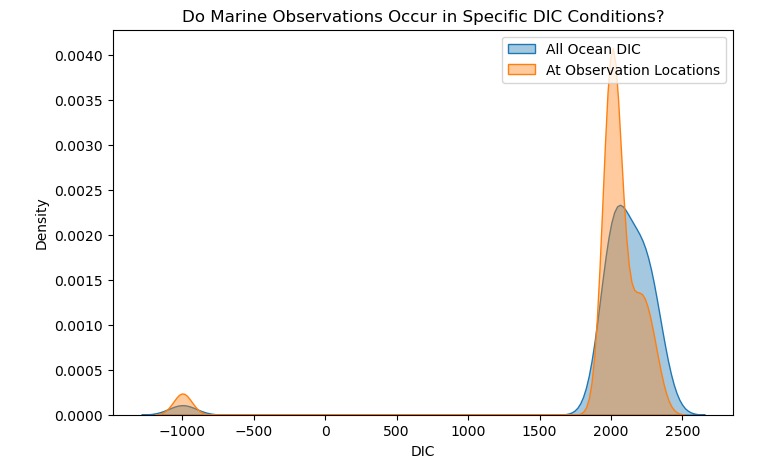
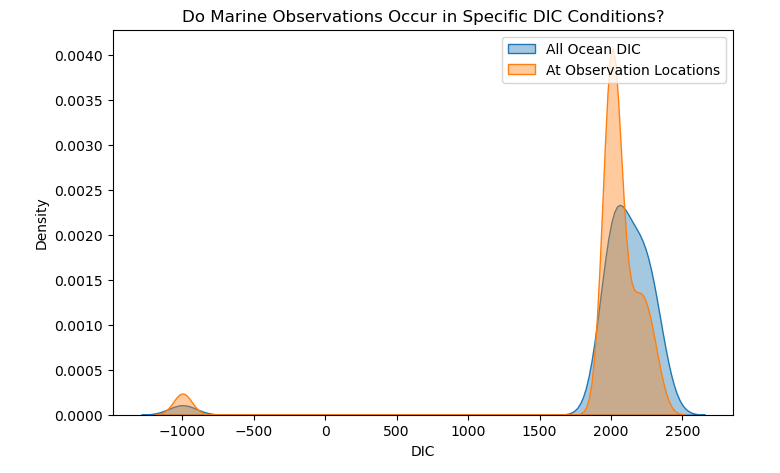
Visual 4
Inspiration
What inspired me about this project is how there's so much data to collect and analyze specifically in the oceans. Luckily, we have a great institution in Scripps Institution of Oceanography (SIO) to collect all this data, but is all this data necessarily "accurate?" That's what I set out to discover.
What it does
The file reads the data, cleans the data, and creates 4 different models recreating the models the original creators of the dataset already made, and demonstrating some hidden relationships between the datasets.
How I built it
I initially built all the code through a basic python file, then started converting it into a Jupyter notebook for better readability and step-by-step through my project.
Challenges I ran into
A challenge I ran into was how to clean and filter the dataset, in order to mostly keep what I needed and how I should use it. I first tried to do some cross-dataset analysis with a confusion matrix, but it ended up showing almost nothing in correlation, which was good to find out, but also a challenge that I had to run into.
Accomplishments that I'm proud of
An accomplishment I'm proud of is being able to have something to submit, and feeling good about what I've learned in the end, with all the new python code I've had to learn and all the information I've looked at about the oceans and the data SIO collected.
What I learned
I learned about how there was bias in the data collected, whether it was intentional or unintentional it exists in the data, even if it's about something that has nothing to do with any opinions.
What's next for Uncovering bias in the marine observational data
Future work that could be done in this project is to dive deeper into more specific marine life and how the data collected for them can potentially differ across species.

Log in or sign up for Devpost to join the conversation.