Links
Introduction
Text-based CAPTCHA, Completely Automated Public Turing tests to tell Computers and Humans Apart, are meant to be a defense mechanism against bots. However, as we seek to prove, it no longer serves that function with the capabilities of deep learning. We seek to create a model that can consistently beat text-based CAPTCHAs, at a rate similar to or higher than humans to prove that text-based CAPTCHAs no longer serve their purpose and should be replaced with better alternatives such as ReCAPTCHA. Our first paper focuses on attempting to beat text-based CAPTCHAs using supervised learning and a classification task. We hope to do so without having to use a segmentation algorithm, which is considered one of the noisiest and most complex parts of solving text-based CAPTCHA. A segmentation algorithm breaks a CAPTCHA into its individual characters because it is much easier to identify individual characters than to classify into all possible strings of characters. This paper uses an alternative called tagging where each training image is “tagged” with a barcode of sorts that is prepended to each image to denote what letter it is looking for (1st, 2nd, 3rd, etc.). This means that the model has to both learn segmentation and learn to identify each letter. While our main goal is to consistently beat text-based CAPTCHAs with our deep learning model, we found this paper interesting and found it logical to try to use deep learning to tackle the segmentation problem too. If that does not work however, our second paper takes a standard approach to solving text-based CAPTCHAs, in which the image is segmented character-by-character prior to training.
Related Work
There have been multiple papers dedicated to various techniques for passing CAPTCHAs. The first one that we came across was “An optimized system to solve text-based CAPTCHA” by Ye Wang and Mi Lu. This paper utilizes a custom segmentation algorithm to split each CAPTCHA by character; it then trains over the corpus of characters. There are also numerous public implementations for the related task of using segmentation to solve CAPTCHA, listed under the ‘Code’ section of each Kaggle dataset. However, we have not found any code that uses binary tags instead of segmentation, as our reference paper does not have an attached code base.
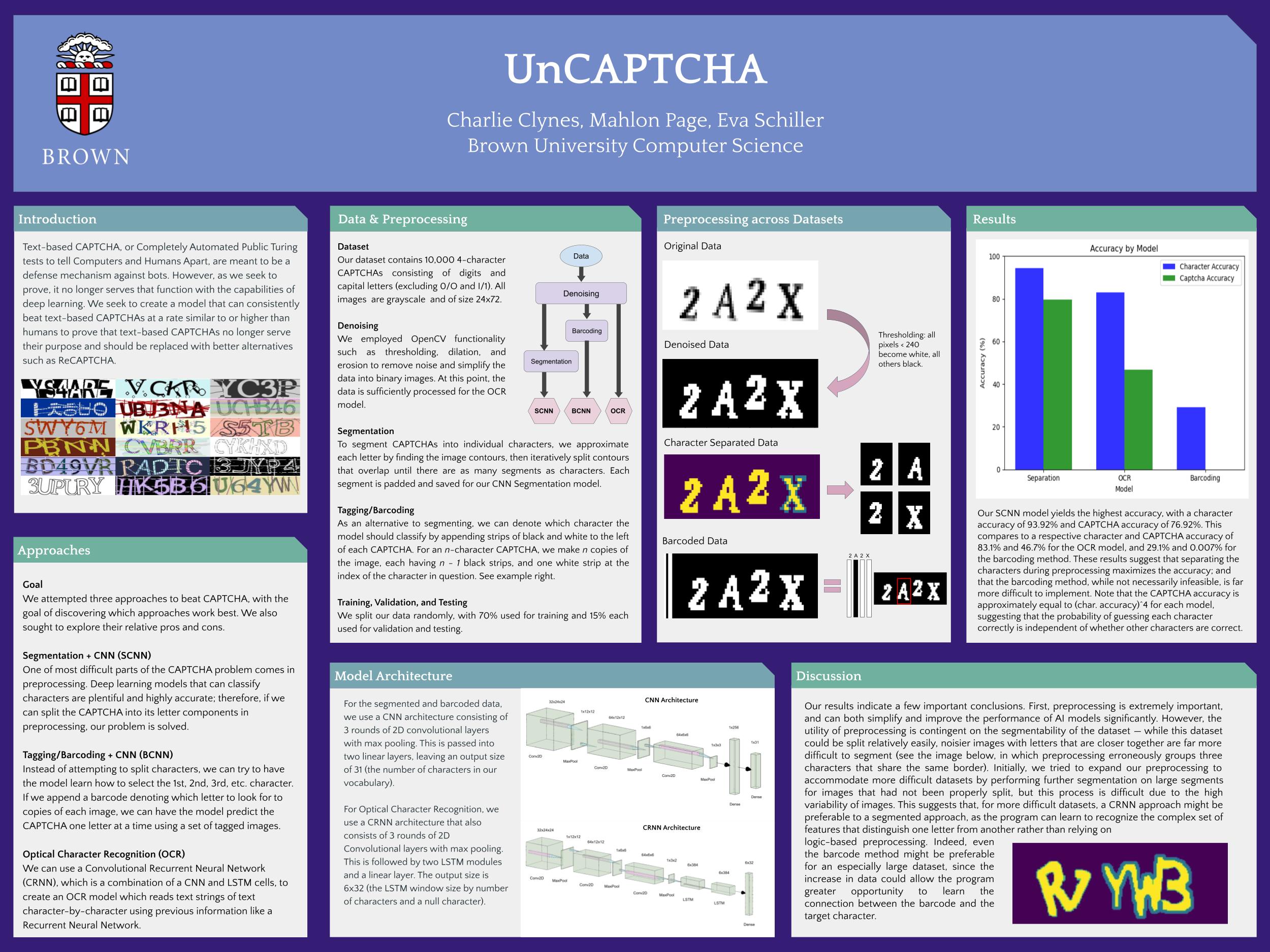
Data
Like the paper we are emulating, we are considering two Kaggle datasets of different complexity. The first is called Captcha Images, which contains 9955 images. Each image contains a four-letter CAPTCHA sequence, which can be any random combination of the digits 2-9 and capital letters A-Z. This dataset has more images and is not case-sensitive, so we anticipate it will be easier to defeat. The second dataset is called CAPTCHA Images, which contains 1070 images. Each image contains a five-letter CAPTCHA sequence, which can be any random combination of the digits 2-9 and letters a-z, A-Z. Each image has had noise introduced through blur and a line across the letters. Since this dataset has case sensitivity, noise, more letters per image, and overall less training data, we anticipate it will be much harder to defeat.
To convert text detection into a classification task, we will only attempt to learn one individual character from a given image. To make this possible, we can employ one of two pre-processing methods: either segmenting the image into individual characters, or using an Attached Binary Image (ABI) to indicate which character the model should classify. We would like to attempt the latter, since it is more efficient for pre-processing, and will not introduce additional inaccuracy to more noisy CAPTCHA images like segmentation will. Loosely, we will make n copies of each image, where n is the number of letters in the image. On each copy, we will attach to the far-right a vertically striped black-and-white section indicating which character to learn (the white stripe will represent the position of the letter), and we will set the character label of the copy accordingly.
Since we have significantly less data than the paper that uses ABI– we have 10000 and 1000 images while they have 70000 and 50000– we anticipate the possibility that it is impossible to successfully train our model to both learn which character to identify and identify it correctly. In this case, we will default to a character segmentation process using functionality from the OpenCV library. This would involve thresholding and other noise reduction, followed by image segmentation using either pre-defined splitting locations or OpenCV’s contour-finding algorithm.
Methodology
Once our data has been preprocessed, we will train a CNN to classify each image as one of up to 62 possible characters. We intend to copy the architecture of our chosen paper, with 17 convolutional layers, 5 max pooling layers, 1 flatten layer, 1 dropout layer, and 1 output softmax layer, and implement these layers using the Tensorflow-Keras package. The hardest part about implementing this architecture will likely be modifying it in the case that we obtain low accuracy with the ABI method: if so, we will have to change our parameters to either reach higher accuracy, or accommodate different input data for pre-segmented images.
Metrics
We plan to separate the data in train, test, and validation splits and run tests on the test and validation splits. The same notion of accuracy follows in our example. However, we will run tests measuring both the accuracy on a character-by-character basis and an overall accuracy for the given CAPTCHA. For example, if the model correctly classifies 4 of 5 letters, we would add 4 successes and 1 fail to its character accuracy while adding only 1 failure to its overall CAPTCHA accuracy. The overarching goal is to have a model that can successfully beat text based CAPTCHAs a realistic, or human-comparable percentage of the time. According to this Baymard article, users fail around 8% of the time and up to 29% when the CAPTCHA is case-sensitive. So we are aiming for these accuracy rates respectively with our case-sensitive and non-case-sensitive data. However, our non-case-sensitive data also has more noise and we may expect a lower relative accuracy compared to our non-case-sensitive data.
The paper that we are referencing has two very similar although different datasets in that they have one case-sensitive dataset with higher noise and obstruction, and one non-case-sensitive dataset that is more visible. In the easier case they achieve a character accuracy of 97.89% and a CAPTCHA accuracy of 92.68%. In the more difficult case they achieve a character accuracy of 85.28% and a CAPTCHA accuracy 54.20%.
With all of this data in mind, we want to set the follow goals for our datasets:
Non-Case-Sensitive (CAPTCHA): Base 75%, Target 85%, Stretch 92%
Case-Sensitive & Noisy (CAPTCHA): Base 35%, Target 55%, Stretch 71%
Non-Case-Sensitive (character): Base 85%, Target 92%, Stretch 98%
Case-Sensitive & Noisy (character): Base 60%, Target 70%, Stretch 80%
Notably, our Case-Sensitive & Noisy goal is very high when compared with the paper given, but our goal is to compete with human success levels and therefore, we are still striving for it. However, it seems unlikely we will actually be able to achieve that goal. All in all, if we can hit all of our base goals for the Case-Sensitive & Noisy data while hitting the target goals for the Non-Case-Sensitive data, we can consider this project a success.
Ethics
CAPTCHAs are used frequently to detect and exclude bots on potentially high-traffic websites. If given the opportunity, bots can wreak havoc — for instance, clickbots can be deployed to fraudulently click ads on websites, costing companies money for each click. Thus, the techniques in this project could be abused to compromise website performance, firm profit, and the integrity of analytics (e.g. number of visitors to a website). On the other hand, building a system that can pass the CAPTCHAs allows for a better understanding of the potential weaknesses of these tests, which in turn could point the way toward improvements. Major stakeholders in this problem include anyone who operates a high-traffic website, including governments, news publications, and large corporations. Preventing fraud and obtaining accurate data are important for all of these organizations, so keeping bots out is critical.
Division of Labor
We plan to split labor evenly and work collaboratively on each part of the project.
Reflection
Challenges The most significant challenge we have faced so far was implementing the barcode method of text recognition. Rather than relying on preprocessing to segment the image into four separate images that each contain one letter and can be fed separately into the model to simplify training, the barcode method gives each image a tag representing which letter it should look for. The model is thus trained both on its ability to recognize letters and its ability to recognize the order in which each letter occurs. While this avoids segmentation in theory, we were only able to achieve a per-character accuracy of about 30%, and our full CAPTCHA accuracy was approximately zero, even after tweaking the model architecture and a number of parameters. This, we think, is because it’s difficult for the model to draw connections between the barcode on the side of the image and the letter that it’s meant to find. While a larger dataset or a model architecture more conducive to drawing these connections might help, we were unable to implement either.
Insights At this point, our current simple model achieves a 91.18% accuracy for individual characters and a 70.19% accuracy for a four-character CAPTCHA tested on the non-noisy dataset. We will probably be able to improve this model with tuning, which we will perform after addressing issues with our CRNN model. Ultimately, we would expect a somewhat higher accuracy given the relative simplicity of the images in our dataset. We are still waiting on concrete results for the noisier dataset and the CRNN models.
Plan We are on track with our project! We have mostly finished the implementation phase — the only remaining steps are to debug and assess the performance of the CRNN (non-segmented, non-barcoded) model, which now trains but returns results that are extremely low-accuracy and formatted incorrectly, and to tune each working model. We also have to complete the write-up and poster once we have our results; these tasks and the former represent the remainder of the project. One change we may make is employing a larger dataset for our CRNN model in particular (which would then likely require department machines to train), as this will hopefully lead to a higher accuracy.
Built With
- python
- tensorflow

Log in or sign up for Devpost to join the conversation.