
unbiasMe
An AI based search engine capable of identifying bias in news articles and promoting sources that are unbiased.
Story Behind the Project
University student environments are filled with passionate discussion and debates of controversial topics. The recent Canadian federal election was the first election that many current university students, including ourselves, were eligible to vote in. We both found it very difficult to learn about each party's platform objectively; it seems like every Google search result is trying to persuade you to think one way or another. It's extremely difficult for someone trying to learn about politics for the first, or any contraversial topic for that matter, time to comb through Google and find unbiased articles. The current media landscape does not allow for individuals to easily access unbiased information and form their own opinions. This limits meaningful conversation and causes people to be easily offended without first being thoroughly informed.
What is unbiasMe?
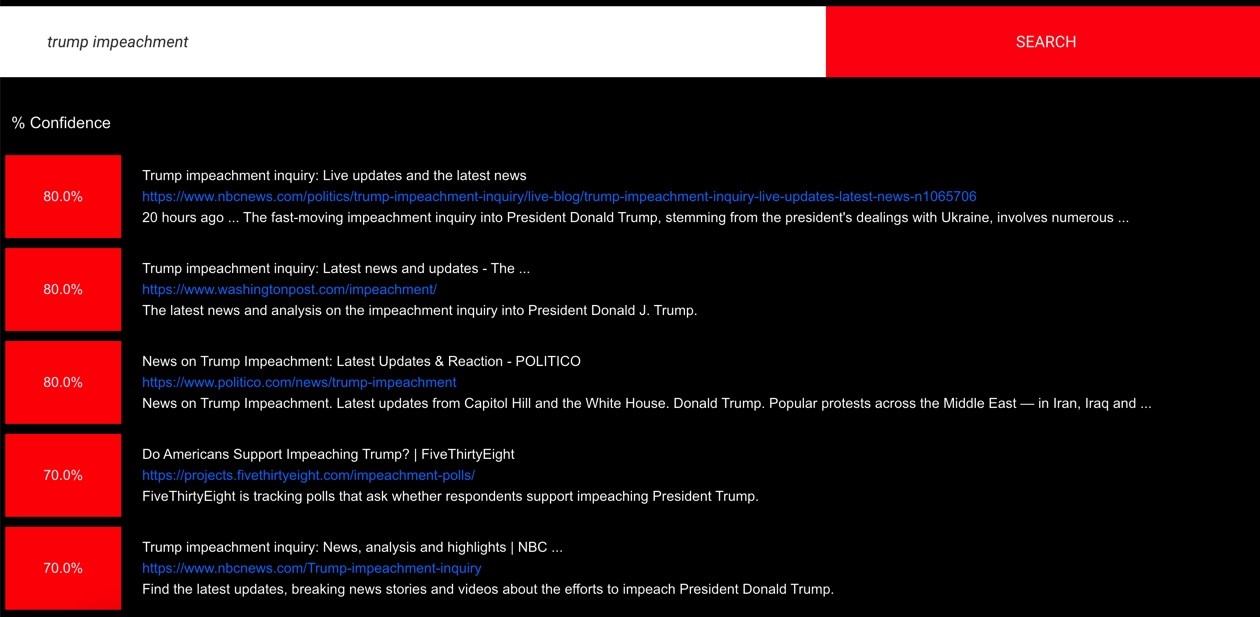
unbiasMe aims to target the above problem; it is a search engine that uses machine learning to determine which articles in a Google search contain the least amount of bias. It then displays those articles to the user first. It also displays a percent confidence for each article, which is simply how confident our machine learning model is that the article is unbiased.
When you enter a query into unbiasMe, a number of the results returned by Google are scraped to retrieve the text data in the article. For each result we convert this text data into numerical features that can be used by a machine learning algorithm. Intensive research was done to determine important features that can be extracted from the text data 1.
Implementation
The back-end is written in Python using Flask, and the front-end in HTML and CSS with a tiny bit of JavaScript. We use Google Custom Search API to Google the users query and extract URLs for our scraper. It was deployed using Google App Engine.
Challenges Encountered
- Front-end development
- That's it, we suck at HTML and CSS (don't even get us started on JavaScript).
Proud Accomplishments
- Implementing Google Cloud APIs and deploying a website for the first time for both of us
- Development of a web-app that actually runs and almost as good as we could have hoped
- Development of a service that impacts many like-minded individuals
- Networking with hackers from all around the world
What We Learned
- That we suck at front-end web development.
- How to deploy a website
- It was some of our first times using sklearn and pandas instead of MatLab for machine learning
- Sleep is important
What's next for unbiasMe?
Our hope is to continue to develop the application by implementing more features to provide users with the best experience. One thing we'd really like to include is a recent news tab where users could go to get stories on current events that are unbiased. Also, the machine learning pipeline could probably be improved to provide users with more accurate results (though we are pretty happy with our 78% test accuracy). The code is not exactly the cleanest, and could probably be cleaned up to increase the speed of the search engine significantly.
Meet the Team
| Member | Position |
|---|---|
| Miriam Naim Ibrahim | Biomedical Engineer |
| Rylee Thompson | Electrical Engineer |
[1] Horne, Benjamin D., Sara Khedr, and Sibel Adali. "Sampling the news producers: A large news and feature data set for the study of the complex media landscape." Twelfth International AAAI Conference on Web and Social Media. 2018.





Log in or sign up for Devpost to join the conversation.