-
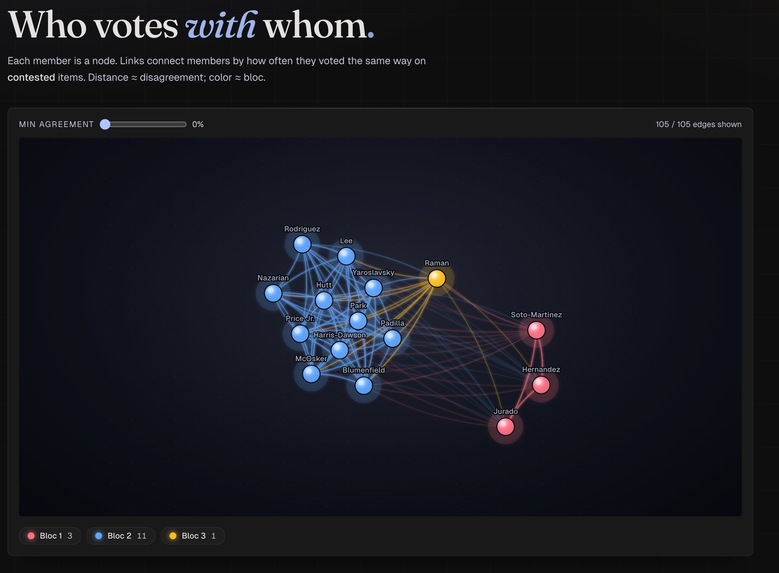
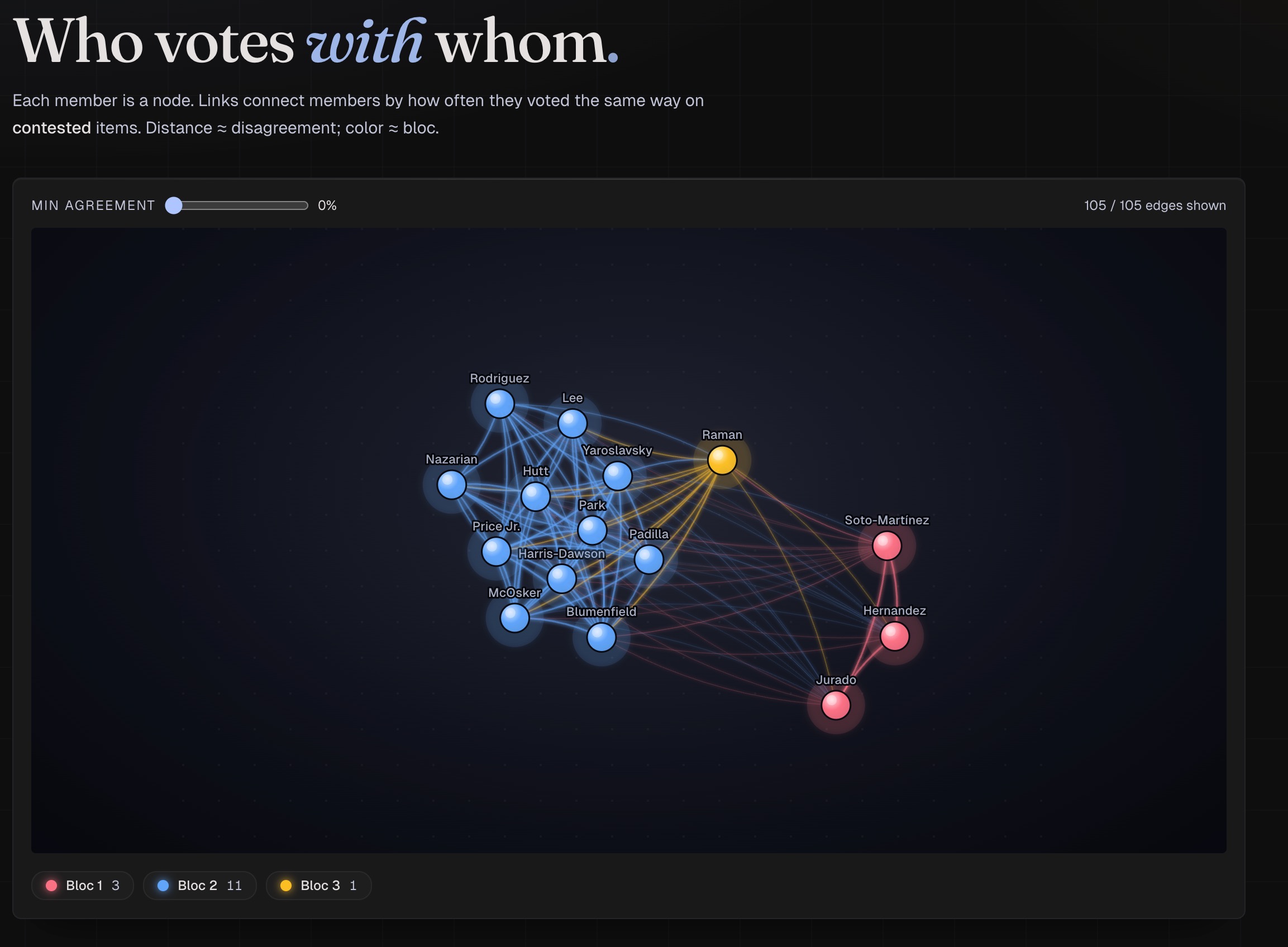
network graph of local council members
-
-
-
Inspiration
Every Tuesday, Wednesday, and Friday at 10am, 15 elected officials vote on decisions that shape daily life for four million Angelenos: zoning approvals that determine where housing gets built, budget allocations that fund or defund public services, and permit votes that define what neighborhoods look like for decades. These decisions happen in public. But for the vast majority of residents, they are functionally invisible.
The barrier is not access. Meetings are streamed live on YouTube with under 50 views. The barrier is time and legibility. A working parent in Boyle Heights cannot spend four hours watching a council session to find the two minutes that directly affect their block. A tenant facing displacement cannot sift through 80-page PDF transcripts to find out whether their councilmember voted for or against emergency rental protections. A local journalist cannot manually cross-reference five years of voting records to surface a pattern of broken promises.
These are the people unbAIs is built for: residents who are already civically motivated but lack the time and tools to make their participation count. The gap is not apathy, it is friction. We built unbAIs to close that gap by turning years of raw council proceedings into a structured, auditable record of what every elected official has actually done and said.
What it does
unbAIs is a dark-mode data analytics web application that decodes the DNA of local politics. It takes raw transcripts of local government meetings and transforms them into an interactive network graph.
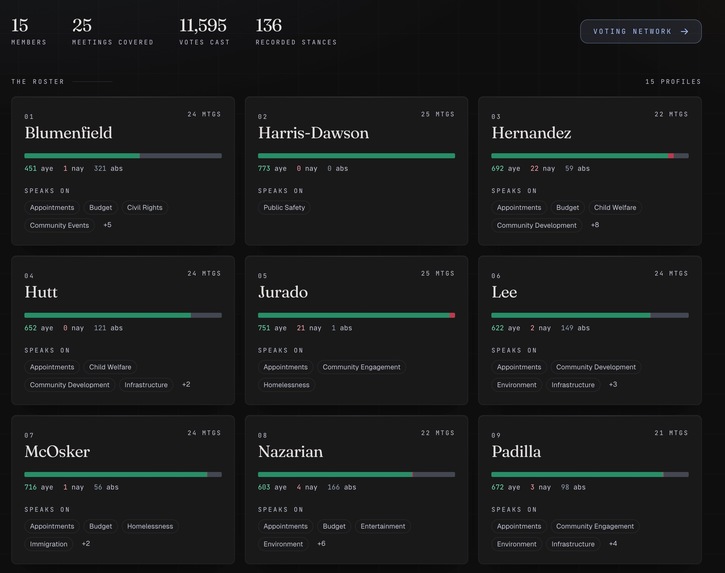
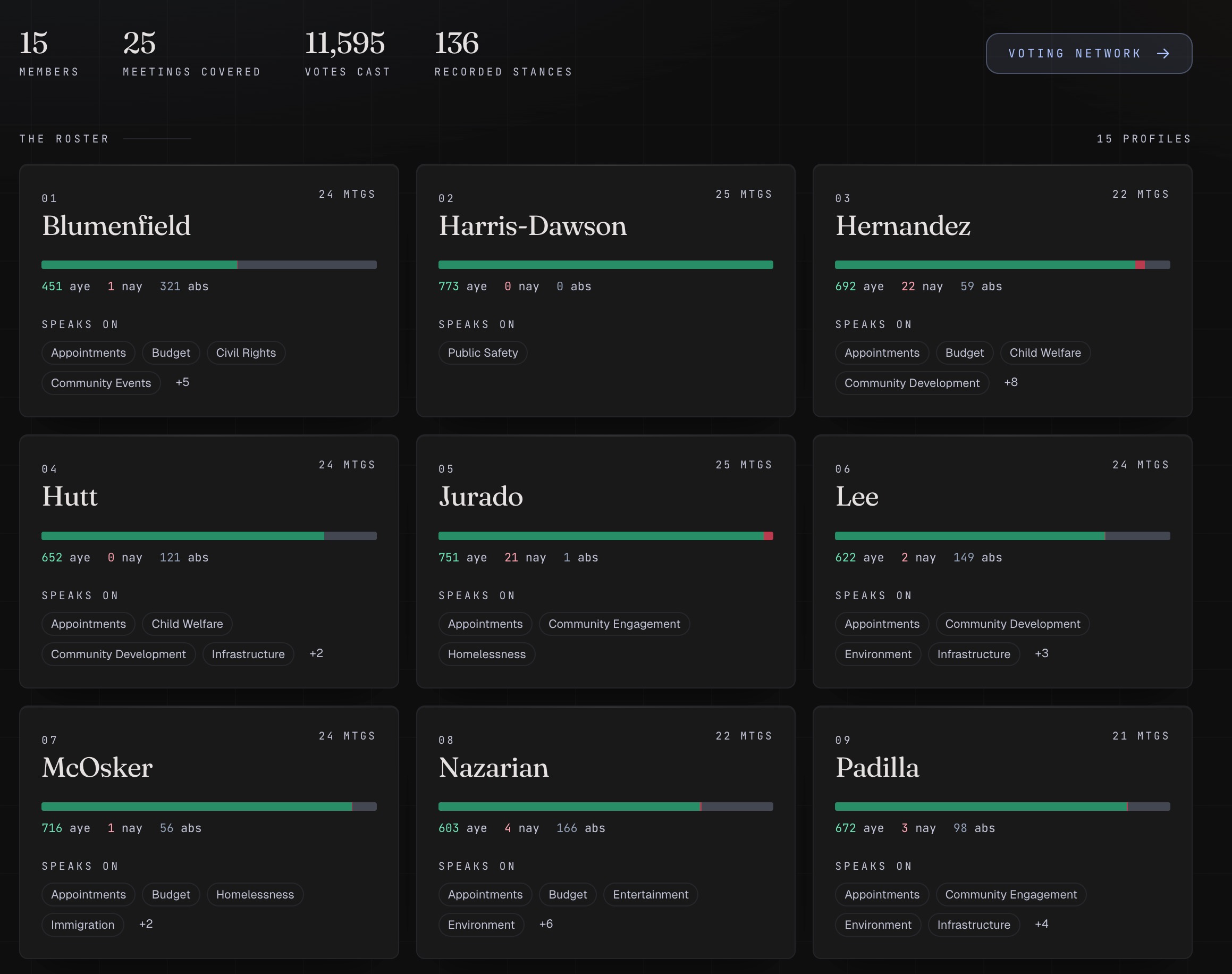
Enter a city name. Within minutes, unbAIs produces a complete political dossier for every councilmember, built entirely from the public record, with every claim traceable to its source. For each member, the dashboard shows:
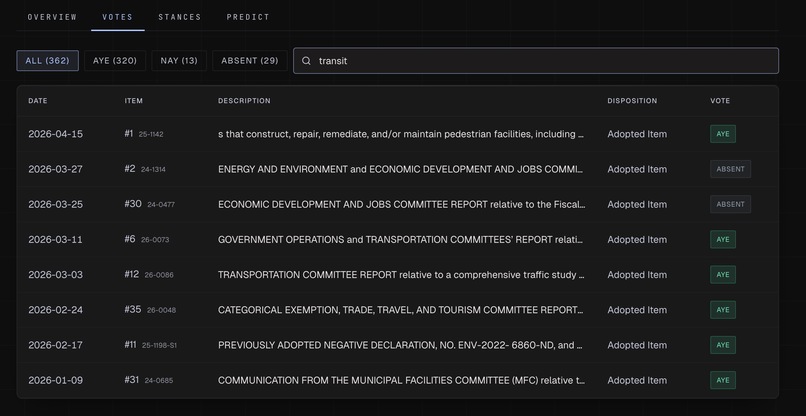
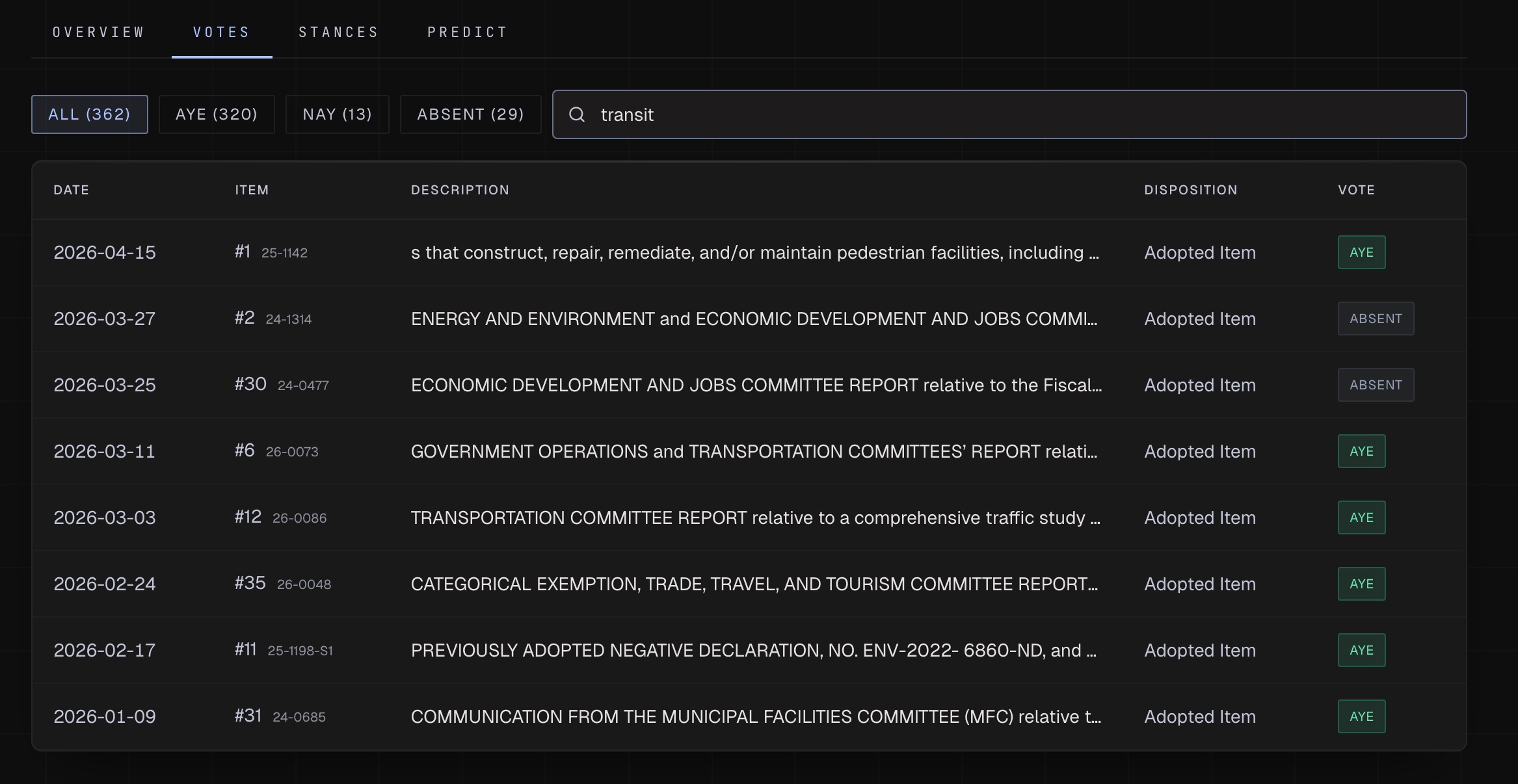
- Full voting record: participation rate, dissent rate, kingmaker rank (how often their vote was the deciding one), and alignment scores with every other member on contested items
- Coalition structure: who they vote with, who they vote against, and which de facto faction they cluster into, surfaced by hierarchical clustering rather than hand-labeling
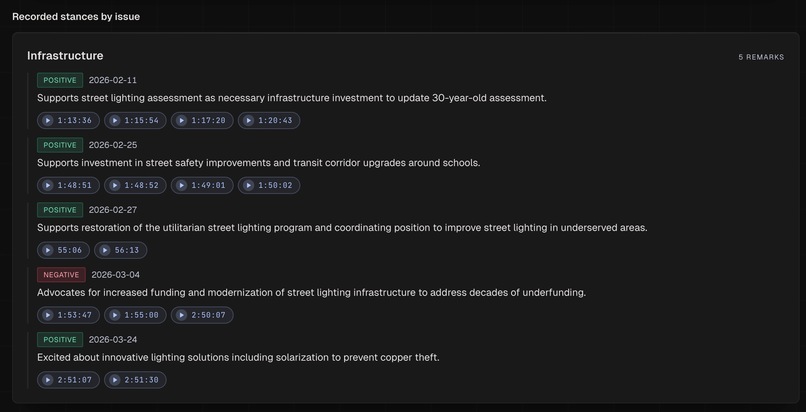
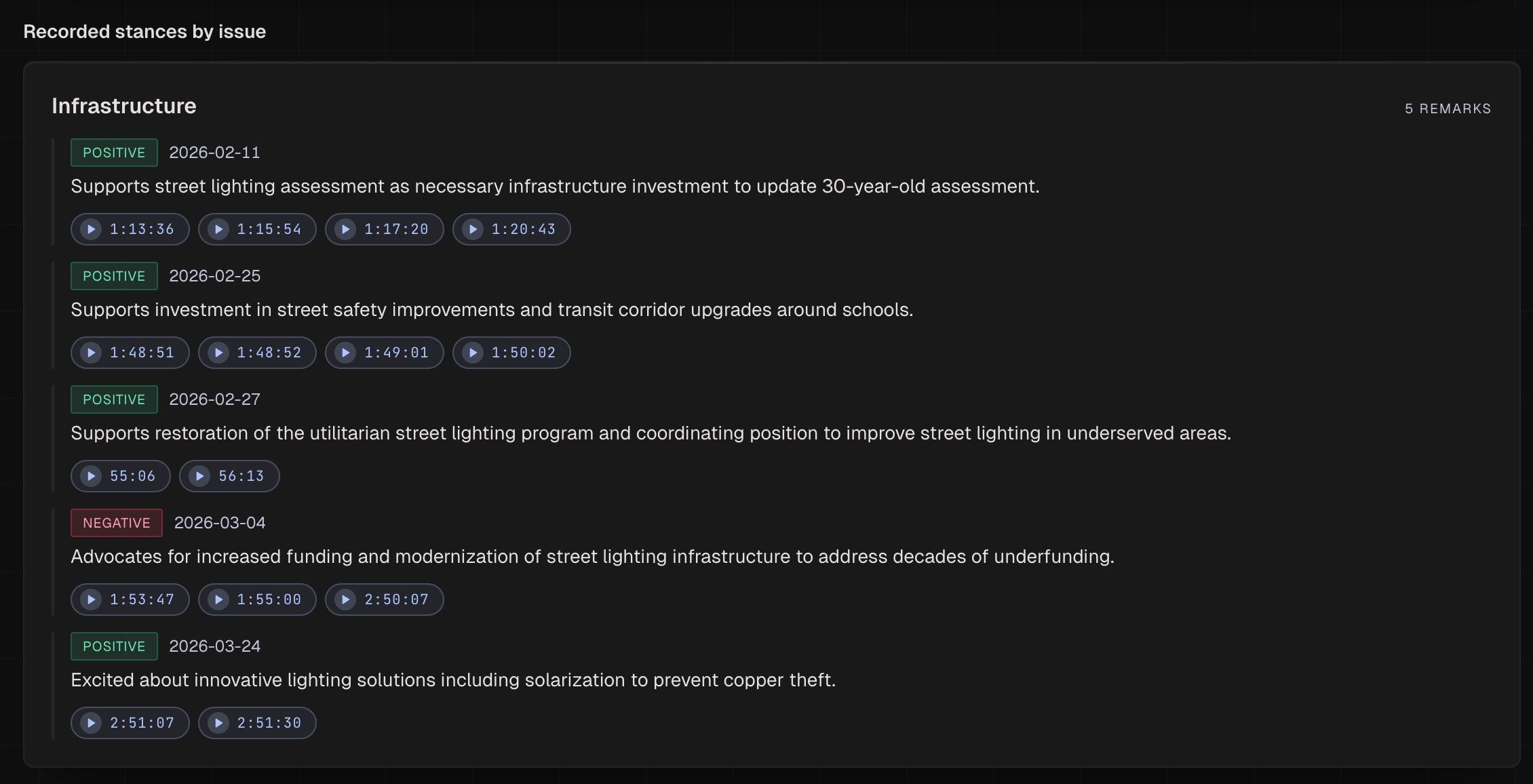
- Stated positions: recurring issues they speak on, their stance on each, with clickable timestamps into the source video
- Commitment tracker: every time a member said "I'll bring this back" or "I commit to opposing X," the system flagged it and checked whether they followed through. Unfulfilled commitments are listed publicly.
Every number on the dashboard links to the rows it was computed from. Every stated position links to the video of the member making it. Nothing is generated. Everything is derived.
How we built it
The pipeline has four stages, each a separate Python module with a single job:
extract_votes.pyparses council proceeding PDFs into a relational schema. Meetings contain items; items contain individual member votes. Output goes to a SQLite database.extract_attendance.pyparses the opening roll-call block into a separate attendance table, distinct from per-item absences. A member present at gavel who misses a vote an hour later is a different signal than one who never showed up.extract_transcript.pypulls YouTube auto-captions and trims to actual meeting start using regex triggers over a sliding window, handling phrases split across caption boundaries and Spanish-first captioning common in LA council recordings.roster.pynormalizes member names across documents using NFKD-normalized fingerprinting. "Soto-Martinez" and "Soto-Martínez" fold into one canonical record, committed to git and human-reviewable.
On top sits analyze_votes.py, where the politics lives: pairwise agreement and co-dissent matrices, asymmetric agreement scoring (a power-dynamic signal), kingmaker computation, and hierarchical clustering to surface factions without predefining them. The frontend is TypeScript. Every aggregate is reproducible from the CLI.
Challenges we ran into
The 6-hour limit forced hard architectural choices. Processing full MP4 video through Claude's vision API was the first approach. It was too slow and too expensive to be viable for a live demo. Pivoting to text-first (auto-captions plus PDF transcripts) gave us the same structured signal at a fraction of the cost and latency.
The harder problem was constraining the model to behave like a strict API endpoint. Getting Claude to produce consistently valid JSON for graph rendering, without hallucinating nodes, breaking physics, or inventing relationships, required defensive prompt engineering: explicit output schemas, failure modes described in the prompt, and validation layers that reject malformed responses rather than passing them downstream.
Accomplishments that we're proud of
Bridging the local LLM gap: we successfully proved that Claude can be used to democratize local political transparency, taking a domain where LLMs traditionally fail and making it legible.
Complex data visualization: translating unstructured, multi-hour meeting dialogue into a clean, mathematically weighted visual graph that makes intuitive sense at a glance.
Design velocity: spinning up a fully cohesive, 3-panel dark-mode dashboard with interactive filtering and source-text evidence blocks in a matter of hours.
What we learned
Context is king, but speed is queen. Having a 1M token context window is a superpower, but optimizing the input format (shifting from raw video to text) is the actual secret to building a viable application.
Strict output formatting: we deepened our understanding of how to constrain Claude's generative tendencies so it behaves like a strict API endpoint returning structured graph data rather than conversational text.
Algorithmic weighting: mapping human ideology requires robust mathematical weighting on the backend. It is not enough to draw a line between two people. You have to calculate the multi-variable strength of that line.
Ethical alignment
We thought carefully about what could go wrong and designed the system around those failure modes, not the optimistic case.
The core risk of any AI civic tool is narrative invention: a model that generates plausible-sounding political characterizations not grounded in the actual record. We designed against this directly. Claude is constrained to act as a structured parser, not an analyst. It extracts fields from documents (speaker, vote, timestamp, verbatim quote). It does not generate summaries, assign ideological labels, or infer what a politician "really believes." Every output reduces to a vote record, an attendance mark, or a transcript span.
Three failure modes we specifically addressed:
- Hallucinated political opinions: prevented by restricting model output to structured JSON extraction with no generative fields
- Unauditable aggregates: prevented by linking every statistic one click to its source rows
- Silent data gaps: prevented by designing the ingestion loop to fail loudly. A meeting we miss does not quietly disappear. The roster tool surfaces unknown-name warnings and missing dates are flagged in the index.
Omission is the subtler risk. A tool that silently drops meetings can produce a skewed record that looks complete. unbAIs is engineered to make its own gaps visible.
What's next for unbAIs
We plan to expand into a fully open-source data ingestion pipeline for local journalists and civic watchdogs, covering any city, not just LA. Next steps include direct integration with municipal public APIs so new agendas ingest automatically as they are posted, and a public unfulfilled-commitments feed updated after every meeting, designed to be embeddable in local news sites. The goal is to make unbAIs infrastructure, not a product: a layer that anyone can build civic accountability tools on top of.
Built With
- claude
- flask
- postgresql
- python
- rag
- react
- rest
- scraping
- sqlalchemy
- sqlite
- tailwind

Log in or sign up for Devpost to join the conversation.