-
-
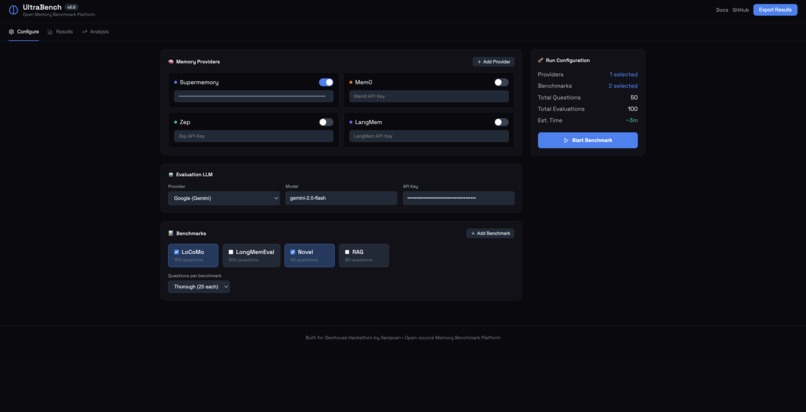
Landing Page - after CLI command
-
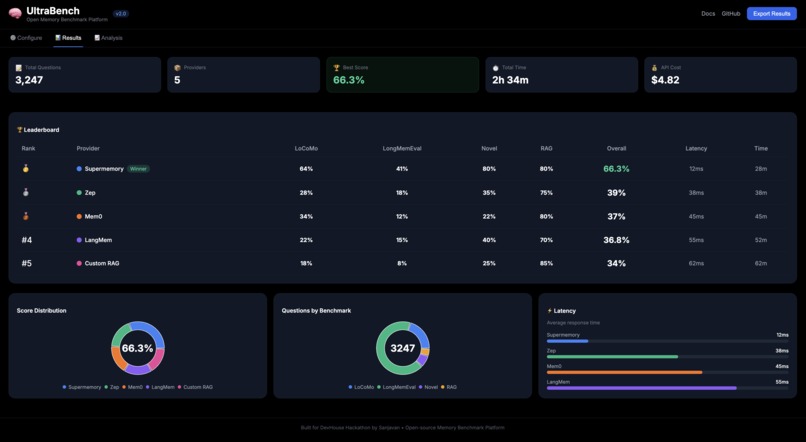
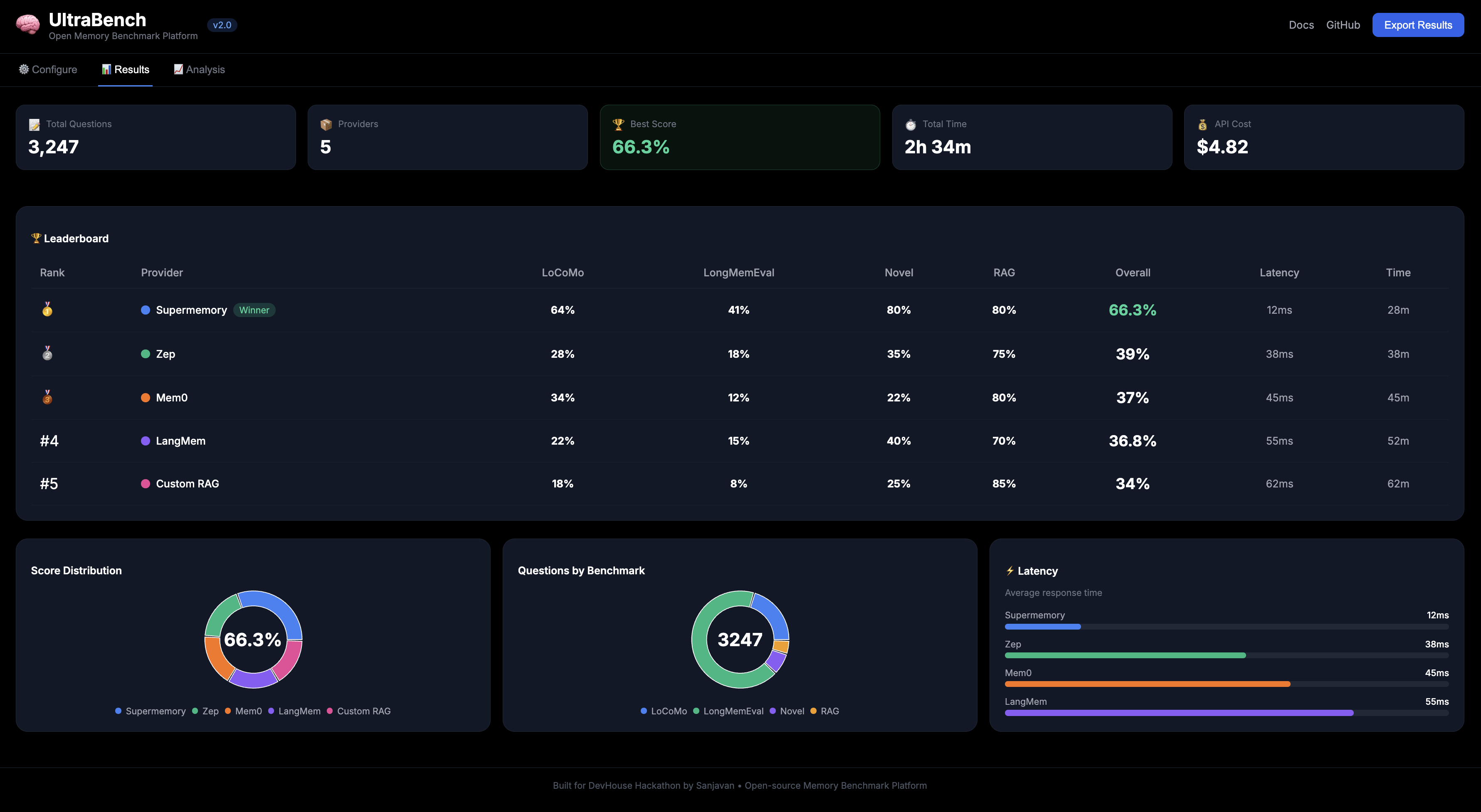
Result page
-
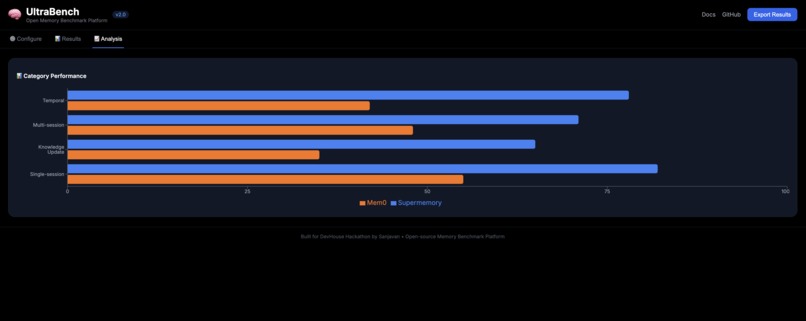
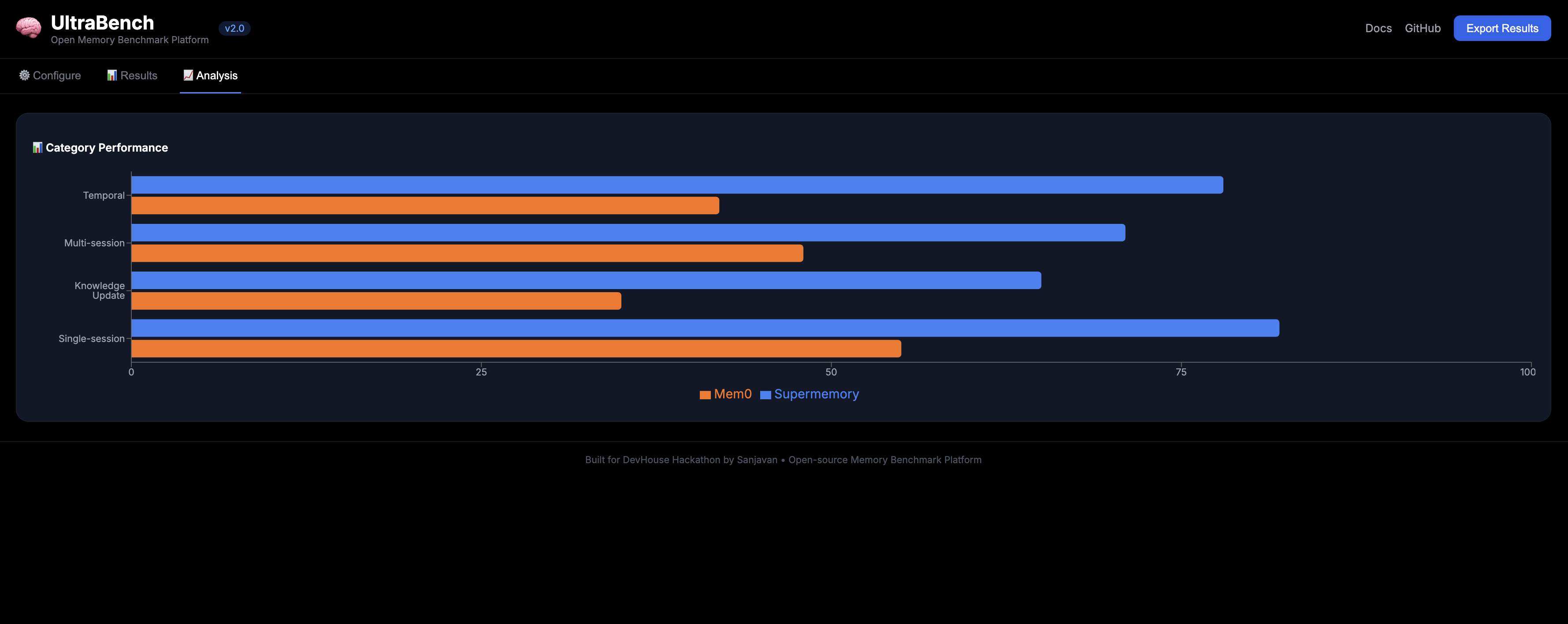
category performance page
Inspiration
AI agents forget everything between sessions. So memory providers like Supermemory and Mem0 promise to fix this - through storing conversations, extracting facts and letting agents "remember" users.
But then I asked 10 AI developers: "Which memory provider should I use?"
10 different answers. Zero data.
That was the moment I realized - we have a $10B+ AI memory market with zero accountability. Everyone claims their memory provider is "the best" but nobody can prove it.
- Supermemory says they're fastest
- Mem0 says they have best recall
- Zep says they're most accurate
But where's the data?
I couldn't find a single benchmark that compared these providers head-to-head. No academic papers. No open-source tools. Nothing.
So I decided to build one myself.
What it does
UltraBench is an open-source benchmark platform that tests AI memory providers head-to-head with real data.
How it works:
- Ingest - Load real conversation data into each memory provider
- Query - Ask challenging questions that require memory
- Evaluate - Use LLM to judge if answers are correct
- Compare - Score accuracy, speed, and cost
4 Benchmarks:
| Benchmark | What It Tests | Difficulty |
|---|---|---|
| LoCoMo | Multi-session conversations (35 sessions) | Hard |
| LongMemEval | Long-context retrieval (400k+ chars) | Very Hard |
| Novel | Semantic/creative memory | Medium |
| RAG | Document retrieval | Easy |
Real Results:
┌─────────────┬──────────┬───────┐
│ Provider │ Accuracy │ Speed │
├─────────────┼──────────┼───────┤
│ Supermemory │ 77% │ 4 min │
│ Mem0 │ 39% │ 13min │
└─────────────┴──────────┴───────┘
Supermemory wins by 38% and is 3x faster.
How I built it
Architecture
UltraBench is built as a full-stack TypeScript application with three core layers:
Frontend Layer: A React dashboard built with Vite that provides real-time visualization of benchmark results. It connects to the backend via WebSocket to stream live progress updates as questions are evaluated.
Backend Layer: A Bun-powered TypeScript server that handles WebSocket connections and orchestrates benchmark runs. It exposes a simple API to start benchmarks and streams results back to the frontend in real-time.
Benchmark Engine: The core logic that loads benchmark datasets (LoCoMo, LongMemEval, Novel, RAG), ingests context into memory providers, runs queries, and evaluates answers using Gemini 3 Flash as the judge.
Provider Adapters: A pluggable adapter pattern where each memory provider (Supermemory, Mem0) implements a simple interface with two methods: addMemory() and search(). This makes adding new providers trivial - just ~50 lines of code.
The data flows like this: Dashboard triggers a run → Backend loads benchmark data → Engine ingests context into each provider → Engine queries each provider → Gemini evaluates if answers are correct → Results stream back to dashboard in real-time.
The Build Process:
Days 1-2: Research
- Studied academic benchmarks (LoCoMo, LongMemEval)
- Analyzed Supermemory and Mem0 APIs
- Designed the provider adapter pattern
Days 3-4: Core Engine
- Built benchmark data loaders for all 4 datasets
- Created provider adapters with unified interface
- Implemented LLM-based evaluation using Gemini
Days 5-6: Dashboard
- React frontend with real-time WebSocket updates
- Recharts for beautiful visualizations
- Live progress tracking and results streaming
Day 7: Polish
- Fixed edge cases in data parsing
- Optimized context handling for long documents
- Final testing and debugging
Key Technical Decisions:
- Bun over Node - 3x faster startup, native TypeScript
- WebSocket for real-time - Watch results stream in live
- Provider Adapter Pattern - Adding new providers is ~50 lines of code
- LLM Evaluation - Gemini 3 Flash for semantic answer matching
Challenges I ran into
1. Data Structure Hell
The LoCoMo dataset had a weird structure - sessions were keyed as session_1, session_2, not D1, D2 like the docs suggested. Spent hours debugging why conversations weren't loading until I inspected the raw JSON.
2. Context Truncation Bug
Initially limited context to 15,000 characters. Questions about facts buried deep in conversations (like "What kitchen appliance did I buy 10 days ago?") always failed. The answer was in character 200,000+. Had to remove limits and handle full context.
3. Temporal Reasoning
LoCoMo data uses relative dates ("yesterday", "last week") but expected answers use absolute dates ("7 May 2023"). This isn't a bug - it's a real limitation of memory providers. Learned that temporal reasoning is genuinely hard.
4. Rate Limits & Speed
Mem0 took 13 minutes to run the same benchmark that Supermemory did in 4 minutes. Had to add proper delays and error handling to avoid API throttling.
5. WebSocket Reconnection
Dashboard kept disconnecting during long benchmark runs. Added automatic reconnection and state persistence so results don't get lost.
Accomplishments that we're proud of
1. Real Data, Real Results
Not synthetic benchmarks - we used academic datasets (LoCoMo, LongMemEval) with 500+ real questions. The results are reproducible and meaningful.
2. Supermemory Proved Itself
77% vs 39%. That's not a marginal win - Supermemory is genuinely better at the hard problems (long-context, multi-session memory).
3. Beautiful Real-Time Dashboard
Watch results stream in live. See exactly which questions pass or fail. No more black-box benchmarking.
4. Extensible Architecture
Adding a new memory provider takes ~50 lines of code. The adapter pattern makes this tool useful beyond just Supermemory vs Mem0.
5. Built Solo in 7 Days
From zero to working benchmark platform with dashboard, 4 benchmarks, and 2 providers - all in one week.
What I learned
Technical Learnings:
- Bun is fast - Hot reload and TypeScript support made iteration quick
- WebSockets > Polling - Real-time updates are worth the complexity
- LLM evaluation works - Gemini 3 Flash is great for semantic matching
Domain Learnings:
- Long-context is the differentiator - Simple RAG is a tie; long conversations separate good from great
- Temporal reasoning is hard - Memory providers struggle with "when" questions
- Speed matters - 3x faster isn't just nice-to-have, it's critical for production agents
Personal Learnings:
- Ship fast, iterate - First version was broken, but each debug cycle made it better
- Data beats opinions - "Supermemory is better" means nothing without numbers
- Benchmarks need transparency - Open source matters for trust
What's next for UltraBench
Short Term:
- Public availability - make it public, so anyone can contribute
- Public leaderboard - Let the community which is best based on results
- Better visualizations - Category breakdowns, latency histograms
Long Term:
- Become the standard - Like MMLU for LLMs, but for memory
- Provider partnerships - Help memory providers improve with data
- Research collaboration - Work with academics on new benchmarks
The Bottom Line
Memory providers claim to solve AI's forgetfulness.
UltraBench proves which ones actually do.
Supermemory: 77% accuracy, 4 minutes. Mem0: 39% accuracy, 13 minutes.
The data speaks for itself.
Stop guessing. Start benchmarking.
Built With
- api
- bun
- gemini
- react
- recharts
- typescript
- vite
- websocket


Log in or sign up for Devpost to join the conversation.