-
-
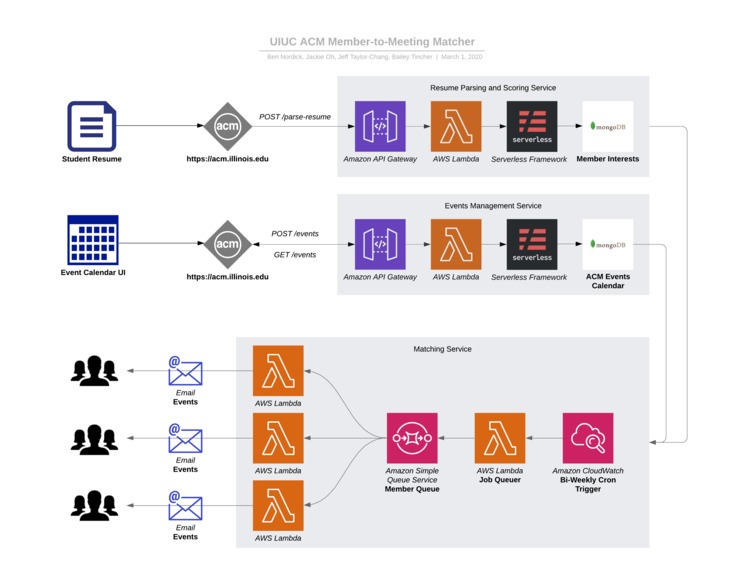
Our architecture


Inspiration
One of the biggest pain points of ACM is the decentralized nature of SIG information, especially meetings. With over 20 SIGs and 1000s of members in ACM, it is impossible to keep up to date on each SIG’s events and focuses on a regular basis. By consolidating some of this information, SIG’s can gain better visibility and traction from the broader ACM student population. By maintaining a centralized database of relevant keywords or topics for each SIG, as well as an up to date schedule of meetings and topics, we can make a significant step towards achieving this goal. More generically, it represents a way to use the empirical interests and passions in your resume and find relevant events to you. While its integration with ACM is an actual use-case, the technology and the idea are far reaching.
What it does
There are two features to our project:
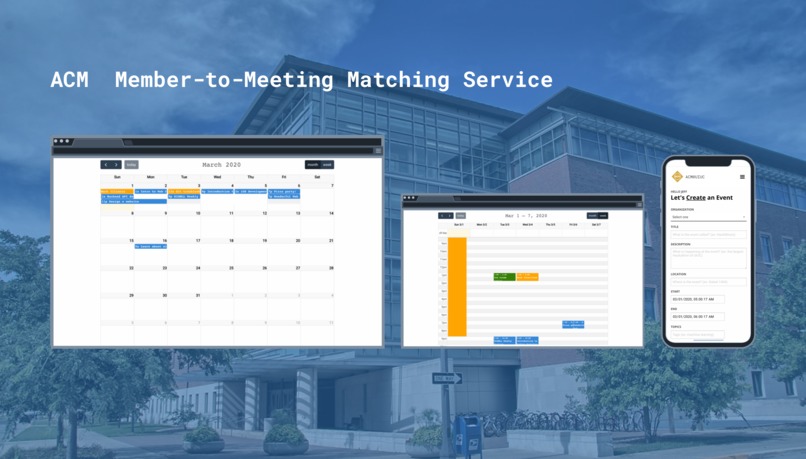
Create, view, and manage events on the ACM website
Our project gives members of ACM at UIUC the capability to log into their ACM account and create events on the ACM calendar. Upon the creation of an event, they also specify the tags they would like to be associated with the event which are then fed to the matching service. Logged in users can also see live previews of their events before creating them and see exactly what everyone else can. Users do not need an account to view events. The event management features will simply not appear on the page if they do not have permission. The event management and calendar are fully responsive and mobile friendly, supporting different layouts for desktop and mobile.
Automated emails to members on recommended events
When a user submits their resume to the resume book on the ACM website, we parse their submission for keywords and keep track of event tags they may be interested in. Then, on a scheduled basis, we send automated emails to users containing events recommended to them based on the keywords in their resume and the events that have been created on the ACM website.
How we built it
The frontend <JavaScript, React, EJS, Express>
The frontend is built as a fork to the Open Source groot-desktop-frontend developed and managed by ACM here at Illinois. We have created a feature ready for PR that hooks into their existing user authentication and seession data from the various groot services. The project uses server-side rendering with Express managing routes and EJS for templating. To give a more modern flair and push the project in a new direction, we have mixed EJS and React as a proposal to progressively replace older templating with React components. To minimize footprint on other areas of the groot project outside of our scope, we have managed to incorporate React and EJS without webpack or babel configs and zero bundling. The Express server handles all the templating and building pages with EJS and the client assembles the React containing the event management project. Clocking in at just under 1,000 lines of code, the frontend is clean, built to fit ACM's overall design aesthetic, and intuitive for the user. There are subtle queues to the user to minimize any pain points, little things like the subtle example placeholders or when a user starts typing a tag, an indicator appears to tell them to hit enter to add it.
For more details and code, see this repo.
Storing events, topics, and user interests <JavaScript, Serverless, MongoDB>
For more details and code, see this repo.
Parsing resumes <Python, Tika, Serverless>
We have hooked directly into ACM's groot services to piggyback the resume upload process. When the user submits a resume though the ACM website, the user's information and resume data are posted to our API where the resume's text is parsed using the Tika Python library. Then, we assign weights to each event tag based on keywords parsed from the user's resume (more on that below) and store that information in a database to be used for later.
For more details and code, see this repo.
Determining user interests <Python>
Given a list of the user's skills (ex: Python, React Native, iOS development, etc), and an event tag (ex: Machine Learning) we want to determine how likely the user would be to attend an event of that focus. We decided to use a similarity measurement between keywords based on the number of times they occur together in the same document. The keywords we used were the StackoverFlow tags that had been assigned to 10,000 or more tags, which we found using the StackExchange DataExplorer. The documents we used were articles scraped from Wikipedia.
For more details and code, see this repo.
Challenges we faced
Groot
Trying to work with a framework that has little support for local development was frustrating at times. Because it's such a tightly integrated ecosystem, we often had to find workarounds to create our own local development setups.
Resume parsing
Because of file size limits in serverless, we were not able to use any of the open source resume parsing libraries we had planned for. So, we implemented our own parser that used Tika to parse text from the resume PDF uploaded by the user, then found keywords and phrases within the text.
Built With
- amazon-web-services
- ejs
- express.js
- groot
- javascript
- mongodb
- mongoose
- python
- react
- serverless
- tika





Log in or sign up for Devpost to join the conversation.