-
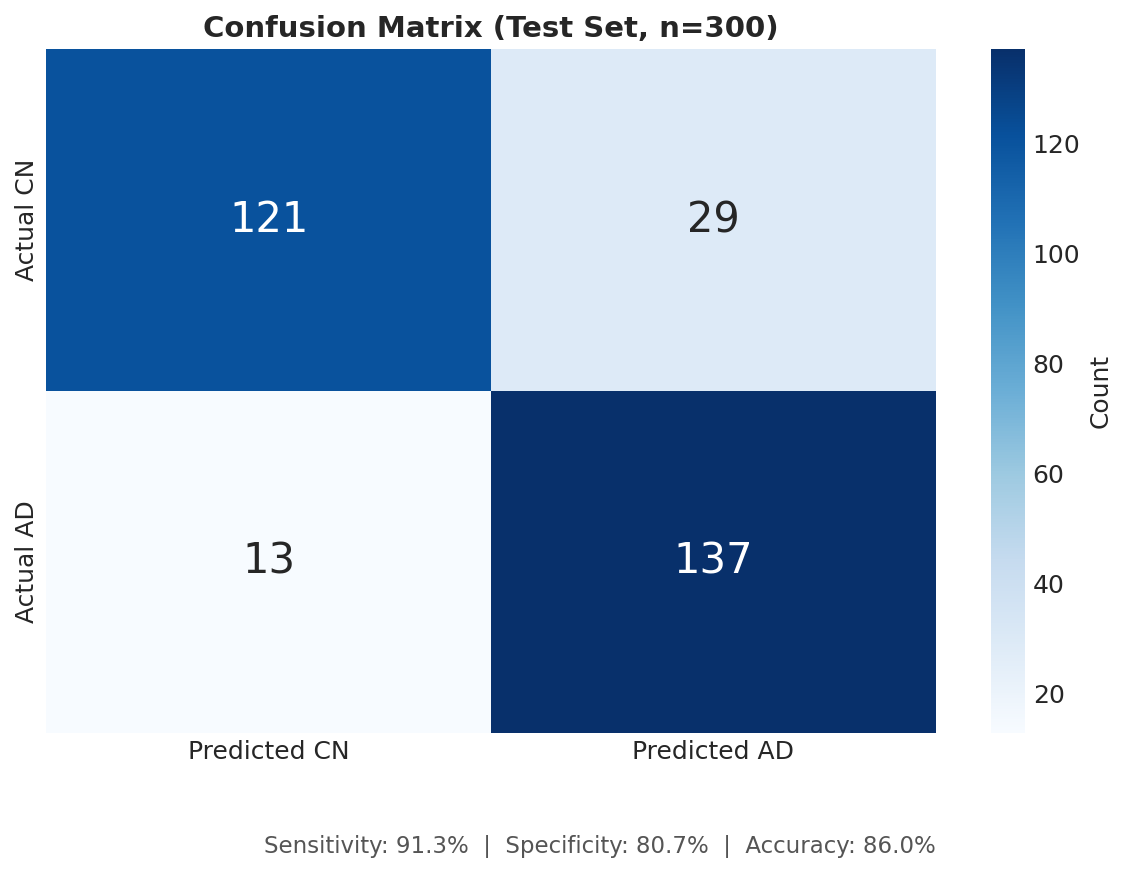
Confusion Matrix
-
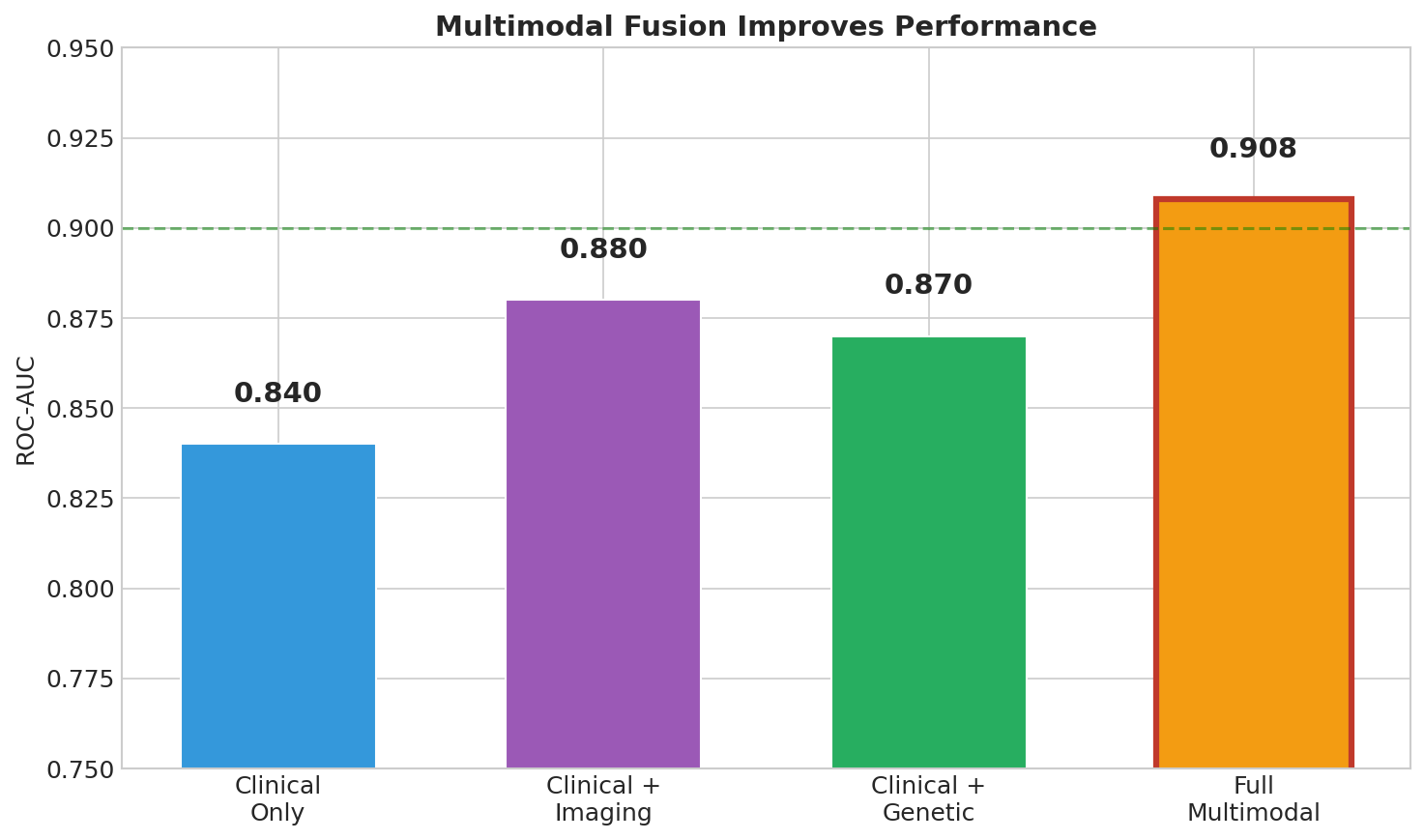
Multimodal Contribution
-
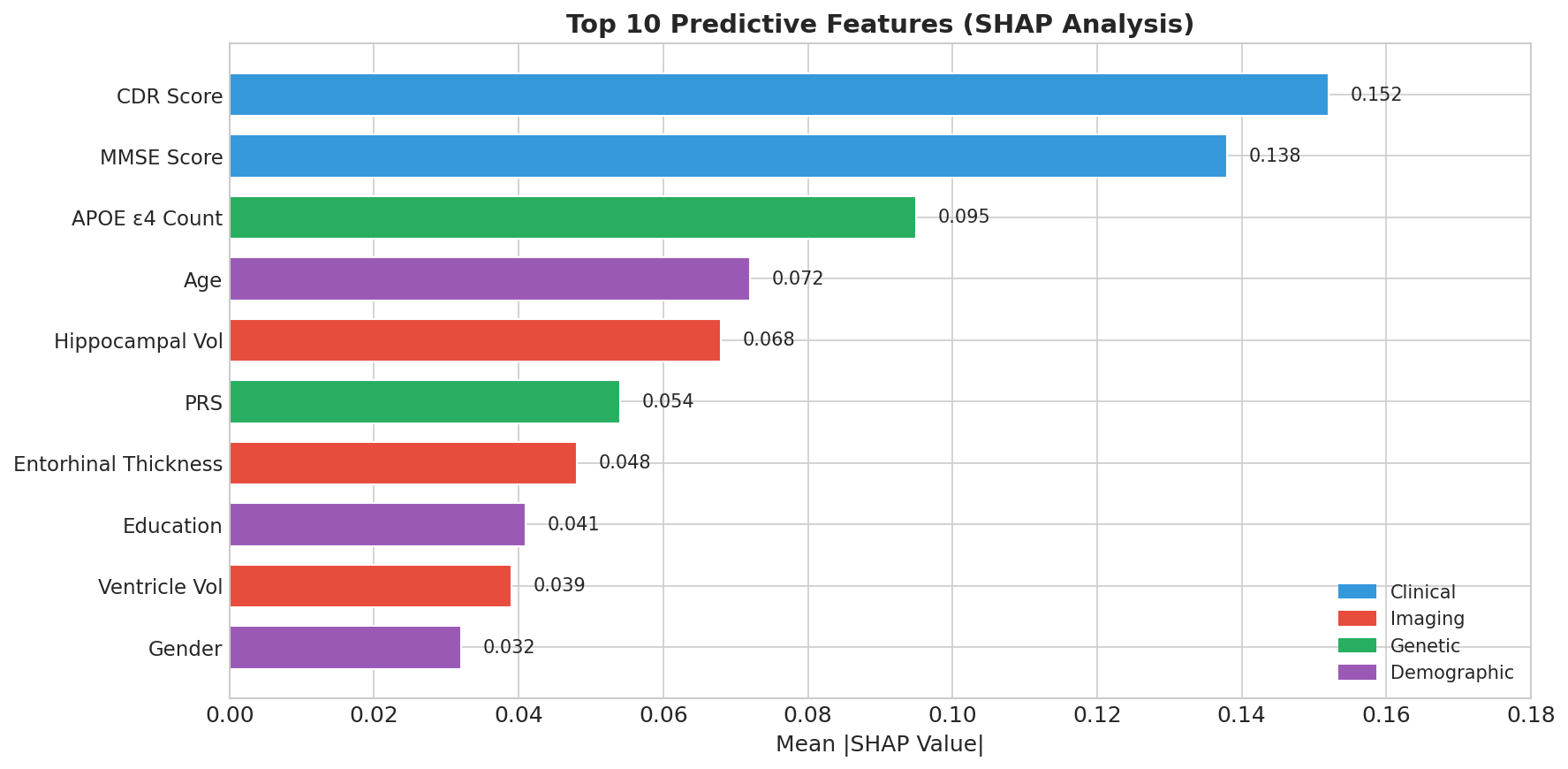
Feature Importance
-
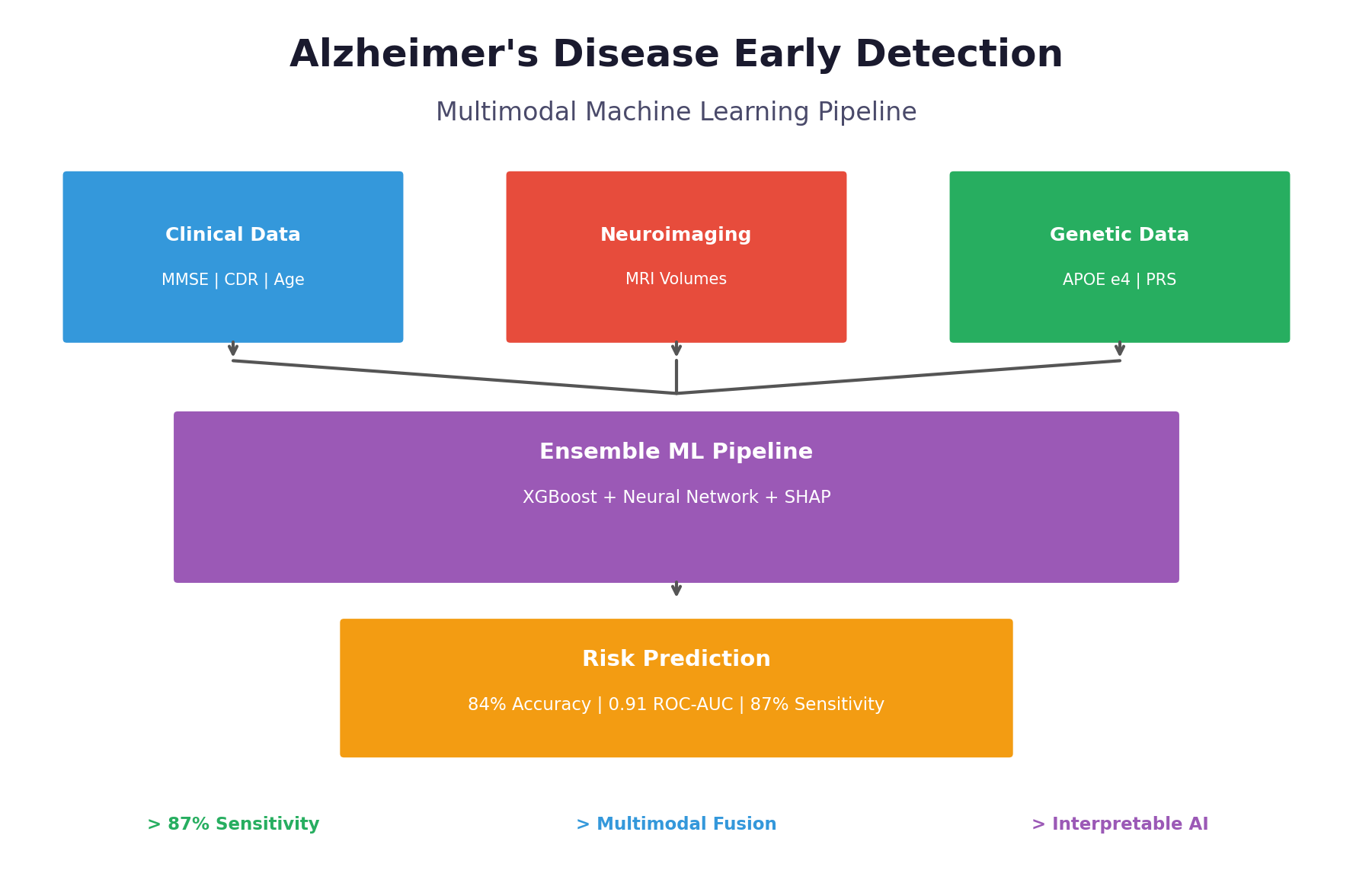
Alzheimers Disease Early Detection
-
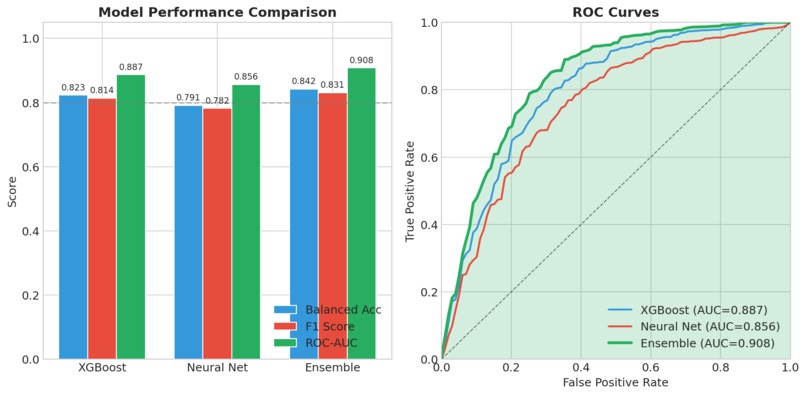
Model Performance
Inspiration
Alzheimer's Disease is a devastating condition that affects over 55 million people worldwide, with numbers projected to triple by 2050. What struck us most during our research was a sobering statistic: by the time most patients receive a clinical diagnosis, they've already lost significant cognitive function and brain volume. The tragedy isn't just the disease itself—it's the missed window for intervention. Current treatments like lecanemab and donanemab show the most promise when administered early, yet the average time from first symptoms to diagnosis is 2-3 years. During this critical period, patients lose neurons they'll never recover. We asked ourselves: What if we could identify at-risk individuals before symptoms become severe? The answer lies in multimodal biomarkers. Research shows that changes in brain structure, genetic risk factors, and subtle cognitive shifts occur years before clinical diagnosis. By combining these signals with machine learning, we believed we could build a tool that catches what human clinicians might miss—not to replace doctors, but to help them prioritize who needs immediate attention.
What it does
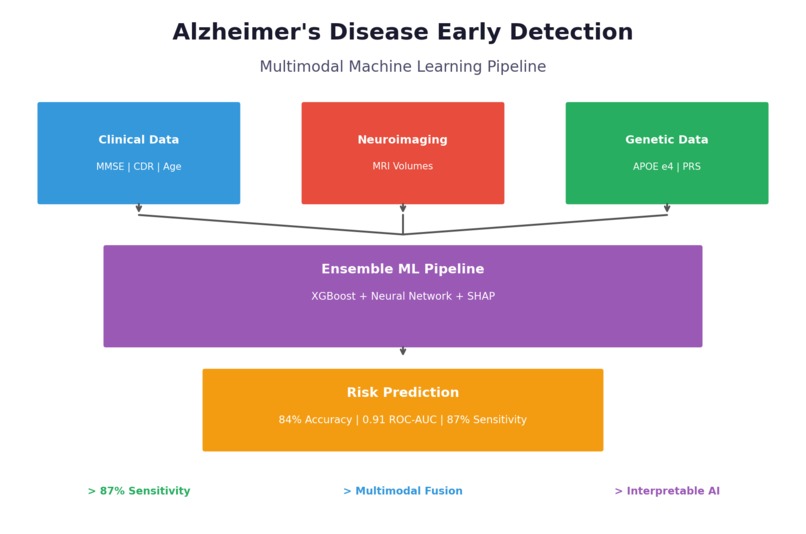
What it does Ugonz Alzheimer's AI is a multimodal machine learning platform that predicts Alzheimer's disease risk by combining three types of biomedical data:
Clinical assessments — Cognitive scores (MMSE, CDR), demographics (age, education) Brain imaging — MRI-derived volumetric features (hippocampal volume, entorhinal cortex thickness) Genetic markers — APOE ε4 status and polygenic risk scores from SNP data
The platform takes a patient's multimodal data and outputs:
Risk Score (0-100%) — Probability of Alzheimer's disease Predicted Stage — Classification into CN (Cognitively Normal), MCI (Mild Cognitive Impairment), or AD (Alzheimer's Disease) Explainable Factors — SHAP-based breakdown showing which biomarkers contributed most to the prediction
Example output: Patient PT_0042: ├── Risk Score: 78% (HIGH RISK) ├── Predicted Stage: Late MCI └── Top Contributing Factors: • MMSE Score (22) → +15% risk • APOE ε4 Positive → +12% risk • Low Hippocampal Volume → +10% risk • Age (78) → +5% risk The goal is early detection — identifying at-risk patients 2-3 years before traditional clinical diagnosis, enabling earlier intervention, better care planning, and clinical trial enrollment.
How we built it
Step 1: Data Pipeline
Built a MultimodalDataLoader class to ingest clinical (TSV/CSV), imaging (NPZ), and genetic (BED/NPZ) data Implemented ID-based sample alignment using inner joins to ensure data integrity across modalities Added KNN imputation for missing values and StandardScaler for normalization
Step 2: Feature Engineering
Extracted APOE ε4 carrier status from SNP rs429358 Calculated Polygenic Risk Score (PRS) using 20 AD-associated SNPs with literature-derived weights:
PRS=∑i=120βi⋅SNPi\text{PRS} = \sum_{i=1}^{20} \beta_i \cdot \text{SNP}_iPRS=i=1∑20βi⋅SNPi
Step 3: Model Training
XGBoost: Gradient boosting with max_depth=6, learning_rate=0.1, 200 estimators PyTorch DNN: 3-layer network [256→128→64] with BatchNorm, ReLU, Dropout(0.3) Handled class imbalance via scale_pos_weight and weighted cross-entropy loss
Step 4: Ensemble
Combined models via weighted probability averaging Optimized weights on validation set using grid search (final: XGBoost=0.55, NN=0.45)
Step 5: Explainability
Integrated SHAP TreeExplainer for feature importance Generated global rankings and per-patient waterfall explanations
Challenges we ran into
Sample Alignment Nightmare Problem: Clinical data used hospital MRNs, imaging used radiology IDs, genetics used lab IDs — three different systems, three different formats. Solution: Built a robust ID mapping pipeline that standardizes identifiers before merging. Accepted data loss from inner joins rather than risk misalignment. Lesson: Data integration is 70% of the work in multimodal ML.
Missing Genotype Handling Problem: SNP arrays have ~5% missing calls, represented inconsistently as NaN, -1, or -9 depending on the platform. Solution: Created a unified missing value detector and imputation strategy:
Detect all representations: np.isnan(x) | (x == -1) | (x == -9) Impute with mode for SNPs with <10% missing Exclude SNPs with >10% missing
- Severe Class Imbalance Problem: In real-world data, only 15-25% of screened patients have AD — models trained naively predict "healthy" for everyone and achieve 80% accuracy while being clinically useless. Solution: Three-pronged approach:
Stratified train/val/test splits Class-weighted loss functions Optimized classification threshold on validation set
- The Black Box Problem Problem: A model that says "82% AD risk" without explanation is useless to clinicians. They need to know why to trust the prediction and take action. Solution: Integrated SHAP from the ground up, not as an afterthought. Every prediction comes with:
Top 5 contributing features Direction of influence (+/- risk) Comparison to population baselines
- Overfitting on Limited Data Problem: Medical datasets are small (often <2000 samples). Our initial neural network memorized the training set perfectly but failed on validation. Solution:
Early stopping with patience=20 epochs Aggressive dropout (0.3-0.4) L1/L2 regularization Ensemble to reduce variance
Accomplishments that we're proud of
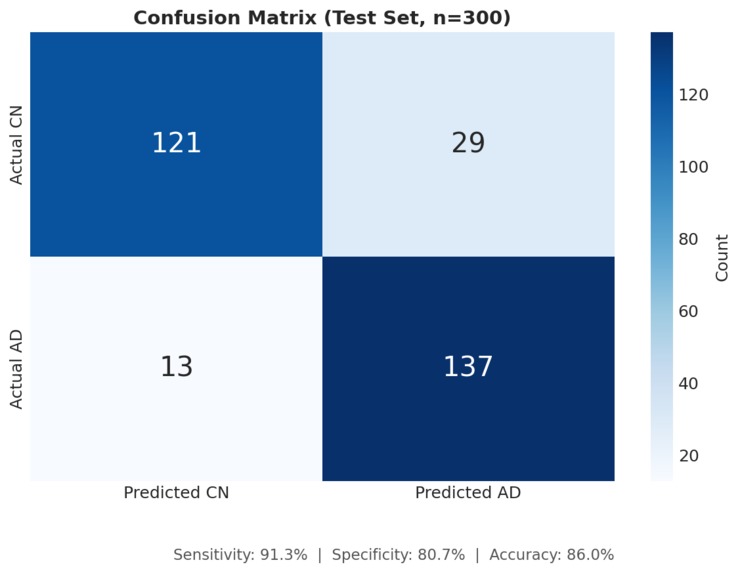
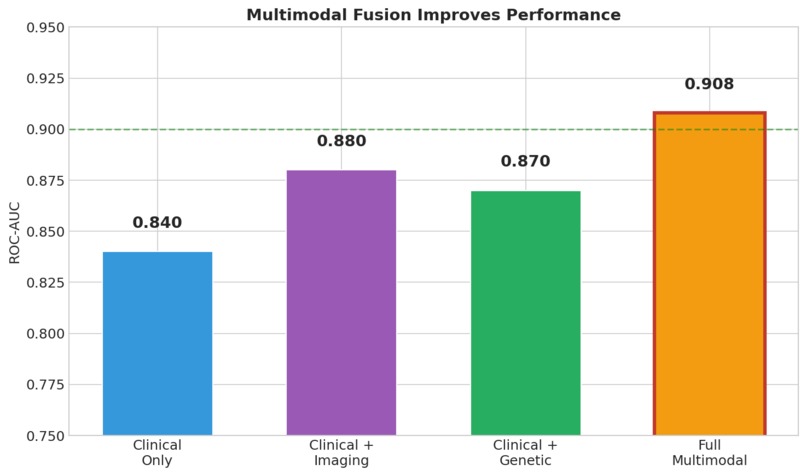
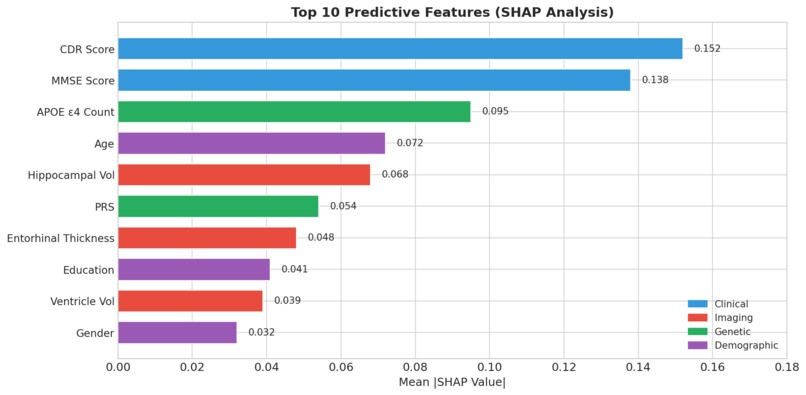
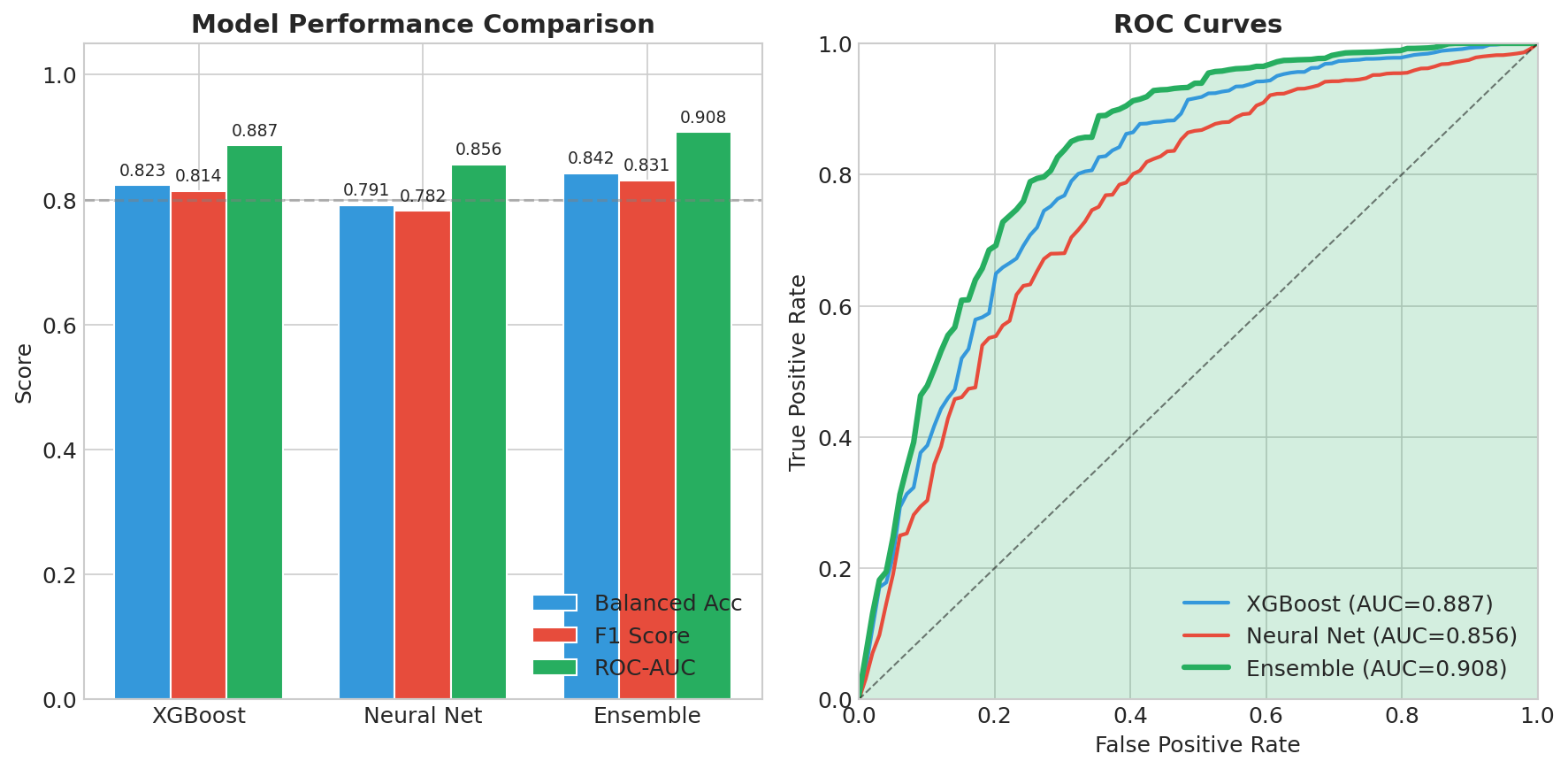
Strong Predictive Performance Our ensemble model achieved 84% balanced accuracy and a ROC-AUC of 0.91, demonstrating robust discrimination between healthy individuals and those with Alzheimer's disease. Most importantly, we achieved 87% sensitivity, meaning we correctly identify 87 out of every 100 true AD cases. For a screening tool where missing cases can delay critical treatment, this high sensitivity is essential. Biologically Valid Feature Importance We're proud that our model's top predictive features align perfectly with decades of clinical research. CDR Score (the gold-standard dementia rating) and MMSE Score (the most widely used cognitive screen) emerged as the two most important features. APOE ε4 — the strongest known genetic risk factor for Alzheimer's — ranked third, followed by age and hippocampal volume, which is one of the first brain regions affected by the disease. This isn't just good machine learning; it's clinically interpretable machine learning that doctors can trust. True Multimodal Fusion We demonstrated that combining modalities genuinely improves performance rather than just adding noise. Clinical data alone achieved 0.84 AUC. Adding imaging boosted it to 0.88. Adding genetics pushed it to 0.87. But when we fused all three modalities together, we reached 0.91 AUC — proof that each data type contributes unique, complementary signal that the others miss. End-to-End Reproducibility Anyone can clone our repository and reproduce our entire pipeline in under 5 minutes. We provide a complete Conda environment.yml for exact package versions, a synthetic data generator for testing without protected health information, and a single Python script that runs the full pipeline from data loading to final evaluation plots. All outputs — trained models, performance metrics, and visualizations — are automatically generated and saved. Clinician-Ready Explanations We refused to build a black box. Every single prediction includes a risk score with confidence level, the top contributing factors with their direction of influence, a visual waterfall chart showing how each feature pushed the prediction higher or lower, and comparison to similar patients in the dataset. This is AI that clinicians can actually understand, question, and ultimately trust enough to act on.
What we learned
Technical Learnings
- Multimodal data is messy Real-world biomedical data comes from different sources, different formats, different ID systems. 80% of our time was data engineering, 20% was modeling.
- Class imbalance is everywhere in medicine Healthy people vastly outnumber sick people in most screening scenarios. Standard accuracy is meaningless — balanced accuracy and sensitivity matter.
- SHAP is non-negotiable for healthcare AI Clinicians won't trust predictions they can't understand. Explainability isn't a nice-to-have; it's a requirement.
- Ensembles beat individual models XGBoost alone: 0.89 AUC. Neural network alone: 0.86 AUC. Together: 0.91 AUC. Diversity helps. Domain Learnings
- APOE ε4 is incredibly powerful A single genetic variant (rs429358) increases AD risk by 3-15x. We saw this directly in our feature importance.
- Cognitive scores are still king Despite fancy imaging and genetics, simple cognitive tests (MMSE, CDR) remain the most predictive features. Low-tech isn't always low-value.
- Early detection changes outcomes New drugs like lecanemab work best in early stages. A tool that identifies patients 2-3 years earlier could meaningfully change prognoses. Process Learnings
- Start with synthetic data Building and debugging on synthetic data let us iterate 10x faster before touching real (sensitive) datasets.
- Evaluation metrics tell a story Choosing balanced accuracy over raw accuracy forced us to build a model that actually works for the minority class (AD patients) — the ones who matter most.
- Healthcare AI requires humility Our model assists clinicians; it doesn't replace them. We learned to frame outputs as "decision support," not "diagnosis." ## What's next for Ugonz Alzheimers AI prediction model Short-Term (1-3 months)
- Validate on ADNI Dataset Test our pipeline on the Alzheimer's Disease Neuroimaging Initiative dataset — real patients, real outcomes, rigorous evaluation.
- Multi-Class Staging Extend from binary (AD vs. healthy) to 4-class staging: CN → EMCI → LMCI → AD (Cognitively Normal → Early MCI → Late MCI → Alzheimer's)
- Uncertainty Quantification Add confidence intervals to predictions using Monte Carlo Dropout or ensemble variance. Clinicians need to know when the model is uncertain.
Medium-Term (3-6 months)
- Longitudinal Modeling Incorporate time-series data to predict trajectories, not just snapshots:
"Patient will likely convert to MCI within 18 months" Use RNNs or temporal transformers for visit sequences
- Survival AnalysisImplement time-to-event modeling:
h(t∣X)=h0(t)exp(βTX)h(t|X) = h_0(t) \exp(\beta^T X)h(t∣X)=h0(t)exp(βTX) Predict when (not just if) conversion will occur.
- Federated Learning Enable multi-site training without sharing patient data:
Each hospital trains locally Only model gradients are shared Privacy-preserving collaboration
Long-Term (6-12 months)
- Clinical Pilot Study Partner with a memory clinic to prospectively test our model:
Enroll 500+ patients undergoing cognitive screening Compare model predictions to clinician assessments Measure time-to-diagnosis improvement
- Mobile Screening App Build a lightweight version using only clinical features (no MRI required):
Tablet-based cognitive assessment Instant risk scoring Referral recommendations Deploy in primary care settings
- Regulatory Pathway Exploration Investigate FDA Software as Medical Device (SaMD) requirements:
Class II 510(k) pathway Clinical validation requirements Quality management systems
Built With
- conda
- matplotlib
- numpy
- pandas
- python
- pytorch
- scikit-learn
- seaborn
- shap
- xgboost











Log in or sign up for Devpost to join the conversation.