-
-
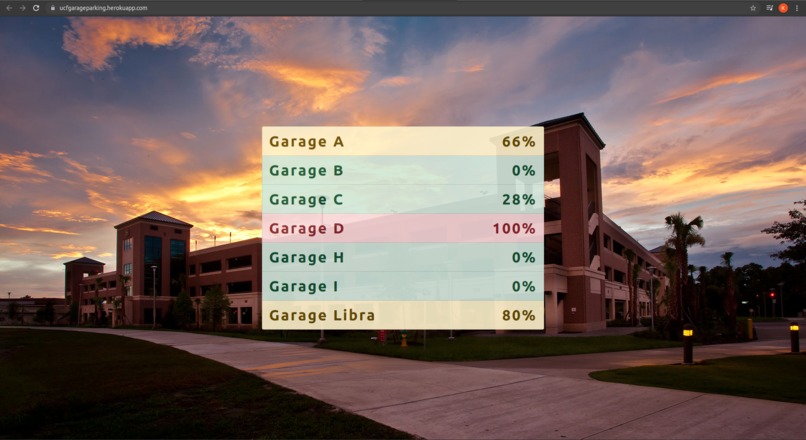
App screenshot

Inspiration
Two main factors inspired this project: I've always wanted to know how to write a web scraper, and parking at UCF (does it even exist?) is a notorious problem. While the parking information exists, I scraped from somewhere after all, it's not in a very readable form at a glance. I aimed to tackle both of these fronts.
What it does
First my web scraper scrapes the information off UCF's parking garage count site, plops this data into a JSON file, then the JSON file is passed into the app and utilized to display the data in a nice, readable format.
How I built it
I used node.js for the web scraper and the app, for web scraping I utilized the puppeteer node.js library, and for the application I used Express.js.
Challenges I ran into
Building the web scraper and learning how to parse the information from a web page was the biggest challenge that I was able to overcome. I originally was going to scrape the data into a mongodb database, but ran into issues getting mongodb running on my machine; I didn't spend a lot of time troubleshooting because of the time constraint of the hackathon. I also was hoping to deploy the project, but I wasn't sure how to go about doing so while generating the JSON file each time the application is run.
Accomplishments that I'm proud of
I'm super proud of myself for participating in my first hackathon, and busting my ass to see a project through to its end (mostly)!
What I learned
How to make a web scraper!
What's next for UCF Parking
I am absolutely going to get this application deployed correctly, ideally running the web scraper on a periodic timer so it stays current.

Log in or sign up for Devpost to join the conversation.