-
-
Search in action. Add a few terms (simple or composite) and you will find them in specific pages of specific pdf papers of the corpus.
Inspiration
Universidad Politécnica de Madrid (UPM) and Accenture Spain have joined efforts to face current challenges that can be solved using Artificial Intelligence. Both created the AInnovation Space in Montegancedo's campus. There, UPM researchers and students work with Accenture developers to create the next generation of tools that will cope these challenges.
What it does
We have technologies to create a fast, reliable and intuitive web application to query and browse huge document repositories. This web app is suitable for mobile devices (tablets, cell phones) as well as desktop computers. In this case we will focus on the covid19 dataset, with more than 70K pdf documents (and growing).
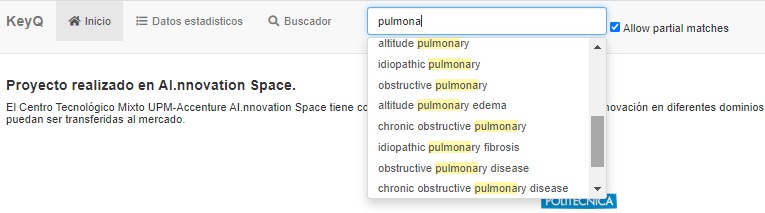
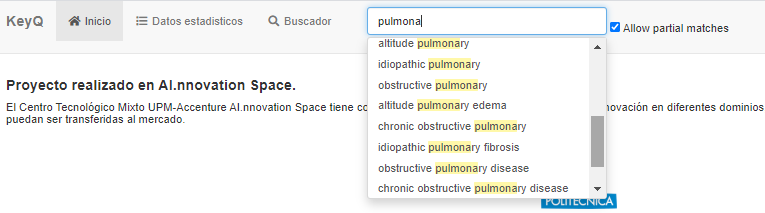
The distinctive fact of this technology is the terminology-based way of specifying what you look for. Instead of the classical set of keywords (one word terms), our approach uses "terms" (simple or composite) that appear in the corpus (text and images). These search-terms are created in advance (automatically) for each corpus. For instance, when a user types "pulmona" the system proposes a list of terms including "pulmona", such as:
- pulmonary edema
- pulmonary disease
But also longer terms like:
- obstructive pulmonary
- chronic obstructive pulmonary disease
The longer the term the better, because it is more specific and this results in fewer occurrences in the corpus. That is, less pages to be read by the user.
How I built it
In the back end we use the KeyQ technology, R packages and solr. The front end is created with Shiny (Bootstrap themes).
Challenges I ran into
We want responses in a blink. Our limit is 0.5 sec but we want 0.1 sec. We all know that response time in that range provides users a control feeling and a satisfying experience.
Accomplishments that I'm proud of
Successful preliminary results with corpora from technological domain (technical manuals), legal domain (Spanish legislation) and bio domain (covid19 scientific papers).
The term-extractor (KeyQ) was created by me and it is "registered software" by my research group (OEG-UPM). This research topic is still an active research and development area to me.
What I learned
The combination of in-memory corpus data with in-disc search is a powerful strategy.
What's next for our tool
We have lots of improvements in mind, but we will show them up only to some privileged eyes ;-)
Acknowledgements
I would like to thank Accenture Spain its support and confidence with us through the AInnoSpace initiative. Also to UPM for their support in entrepreneurship (ActúaUPM and Innovatech programs). And last but not least a huge hug to the UPM Artificial Intelligence master students (Álvaro, Pedro, Lucía, JJ) who pushed all our ideas and prototypes to professional levels.










Log in or sign up for Devpost to join the conversation.