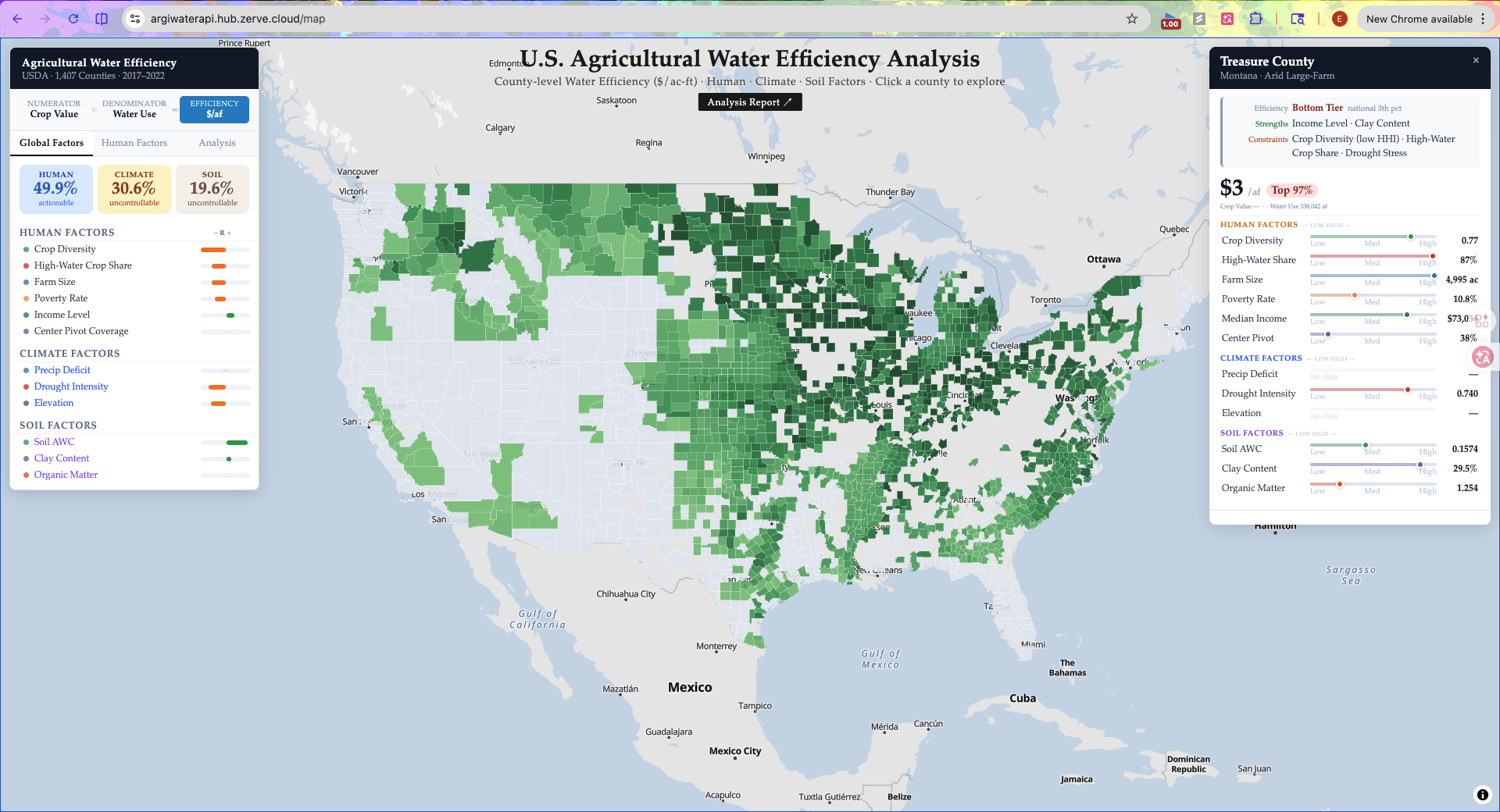
U.S. Agricultural Water Efficiency Analysis
▎ Turn every drop into data. Turn data into decisions.
Inspiration
Agriculture accounts for roughly 80% of consumptive water use in the United States, yet the efficiency of that water varies enormously from county to county — even between neighbors with identical climates. During the early 2025 California wildfire season, the tension between drought stress, groundwater depletion, and irrigation demand became viscerally clear. We kept asking: which counties are wasting the most water, and what can actually be done about it?
The question sounded simple. The answer turned out to require stitching together a dozen federal datasets that had never been analyzed together at county scale.
What It Does
The platform answers three questions for every U.S. agricultural county:
- How efficiently is water being converted to crop value?
We define the core metric as:
$$\text{Efficiency} = \frac{\text{Crop Value}}{\hat{W}}$$
where estimated water applied is:
$$\hat{W} = A_{\text{irr}} \times \frac{\text{ET}_0}{12}$$
where A_irr = irrigated acres (NASS Census) and ET₀ = reference evapotranspiration (gridMET)
- Why is efficiency low — climate, soil, or human choices?
A Random Forest decomposes variance into three buckets using Mean Decrease in Impurity (MDI), then a Doubly Robust causal learner isolates the Average Treatment Effect (ATE) of adopting center-pivot irrigation:
$$\hat{\tau}_{\text{DR}} = \mathbb{E}\left[\hat{\mu}_1(X) - \hat{\mu}_0(X) + \frac{T(Y - \hat{\mu}_1(X))}{\hat{e}(X)} - \frac{(1-T)(Y - \hat{\mu}_0(X))}{1 - \hat{e}(X)}\right]$$
- Which counties are the best intervention targets?
Three policy insight layers — Low-Hanging Fruit, Virtual Water Export, and Dual Exposure — surface the highest-ROI counties on an interactive map with Gemini-powered natural language explanations.
How We Built It
Data Pipeline
We built a parallel ingestion layer that pulls from nine federal data sources into Google Cloud Storage, then constructs a county-level wide table (~2,600 counties × 30+ features):
- USDA NASS: Crop production, irrigated acres, farm size, operator tenure
- gridMET: ET₀, precipitation, precipitation deficit
- SSURGO: Soil AWC, clay %, organic matter
- FEMA NRI: Drought risk score, flood risk score
- BLS: County unemployment rate
- BEA: Farm proprietor net income
- USDA RMA: Crop insurance loss ratio
- Google Earth Engine: Center-pivot irrigation footprint
- U.S. Census: Population, poverty rate, median income, education
ML Analysis Stack
The analysis runs as a sequential pipeline (run_analysis.py):
02_eda → 03_efficiency → 04_causal → 05_shap → 06_cluster → 07_insights → 08_subgroup
- 03: Random Forest MDI + LassoCV to decompose climate / soil / human factor contributions
- 04: DRLearner (EconML) for causal ATE/CATE estimation of irrigation technology adoption
- 05: SHAP beeswarm to surface directional feature effects on WUE
- 06: K-Means clustering of counties into agronomic archetypes
- 07: Rule-based policy flagging for three insight categories
Backend & Frontend
A FastAPI backend serves pre-computed JSON to a map frontend. A /simulate endpoint lets users adjust feature values and see predicted WUE change. A /explain endpoint passes county data to Gemini to generate plain-language policy briefs.
Challenges We Ran Into
Messy, heterogeneous federal data. NASS data ships in at least four different pipe-delimited and JSON formats depending on year and query type. BLS unemployment data changed its series format mid-pipeline. We wrote separate parsers for every source and spent significant time on fallback logic when primary sources returned empty blobs.
The WUE denominator is unobservable. No federal dataset directly measures how much water a county applied. We had to derive Ŵ from irrigated acreage × ET₀, which introduces systematic error in counties with high
groundwater use (where actual applications exceed crop demand). The metric is best interpreted as a relative ranking across similar climate zones.
Causal identification is hard at county scale. Counties that adopt center-pivot irrigation differ from non-adopters in dozens of confounding ways. We chose DRLearner specifically because it is doubly robust — consistent if either the
outcome model or the propensity model is correctly specified — but we could not fully rule out remaining omitted variable bias (e.g., aquifer depth, local water pricing).
SHAP + panel-scale data is slow. Running TreeSHAP over 2,600 counties with 500-tree forests required careful batching and pre-computation; doing this interactively in a browser was not feasible.
Accomplishments That We're Proud Of
- Successfully joined nine independent federal datasets into a single analysis-ready county table, something that, to our knowledge, has not been published as an open pipeline.
- The causal model found a statistically significant ATE for center-pivot adoption even after controlling for climate and soil — suggesting the efficiency gap is partly a policy problem, not just a geography problem.
- The Virtual Water Export insight layer flags arid counties that are effectively exporting their scarce water in the form of water-intensive crops — a risk that is invisible in standard agricultural statistics.
What We Learned
- Federal open data is rich but fragmented. The raw signal for county-level water efficiency is all publicly available; the barrier is integration, not access.
- Causal ML requires humility. It is tempting to report a clean ATE number. The real lesson is understanding why the estimate might be wrong and what identifying assumptions are being leaned on.
- Visualization drives insight. The SHAP beeswarm and the three-bucket MDI pie chart communicated more to non-technical stakeholders than any regression table.
- The Herfindahl-Hirschman Index for crop diversity, HHI = Σ(sᵢ²) where sᵢ is crop i's revenue share, turns out to be one of the strongest human-factor predictors of WUE — monocultures are consistently less
water-efficient.
What's Next for U.S. Agricultural Water Analysis
- Temporal dimension: extend from a single cross-section (2022) to a panel (2012–2022) to enable difference-in-differences estimation of policy interventions.
- Groundwater integration: add USGS NWIS well-level data to correct the Ŵ denominator in over-drafted aquifer regions (e.g., High Plains).
- County-to-farm bridge: aggregate FSA CLU parcel data to bring the analysis down from county to individual farm — the policy levers are at that scale.
- Water pricing signal: incorporate state water rights transaction data to test whether markets improve or distort WUE.
- Direct integration with Zerve for reproducible, shareable analysis notebooks that policymakers and extension agents can run without code.
Built With
- fastapi
- github
- google-cloud
- html
- python
- uvicorn

Log in or sign up for Devpost to join the conversation.