
Humans and computers have an I/O asymmetry problem. Our screens show us millions--or even billions--of bytes worth of information every second, yet we can only manage to type a few bytes on our keyboards in that same timeframe. Furthermore, most of those characters we do type are redundant, since we can usually infer the rest of the word from context and the first few letters.
TypeBoost helps turbocharge your typing speed by offering to complete the word you're typing once it becomes clear from context once the rest of the word should be. You spend less time typing, but get more ideas onto the digital page. We have autocomplete for code, and it made all of us more productive this weekend. Why not have autocomplete for English, as well?
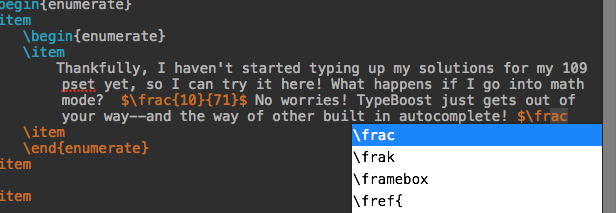
Anywhere you type on your computer, TypeBoost guesses at the rest of the word and types it out in front of your cursor. If you don't want to accept the suggestion, just keep typing and TypeBoost will get out of your way. However, if you hit the spacebar twice, TypeBoost will accept the completion, finishing the word, and putting your cursor in position for the next one.
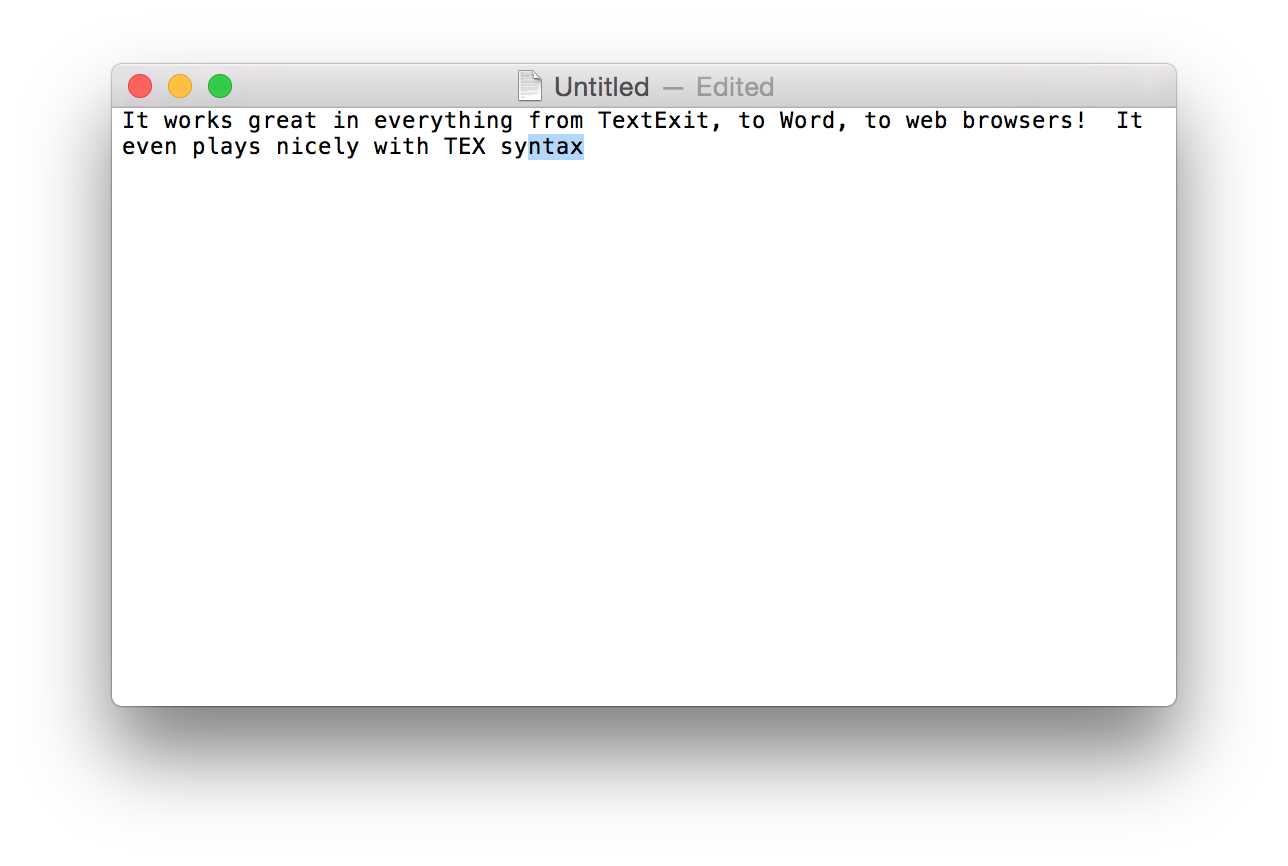
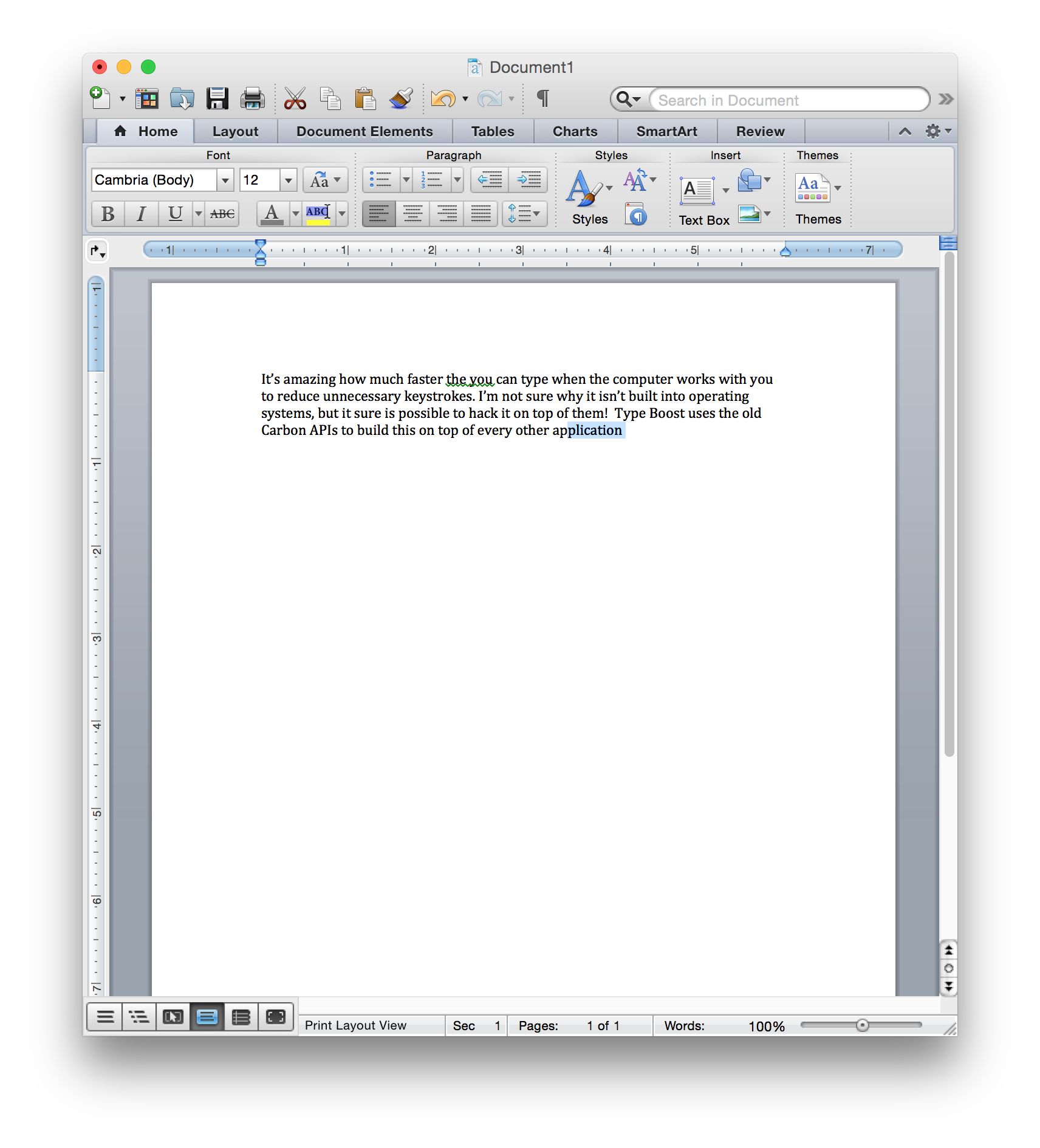
The tricky part about making something like this is that you don't have access to the text view the user is typing into. That means you can't add any UI of your own, at least not if you want it to work on top of every other program on the operating system. Instead of trying to inject into TextViews, TypeBoost uses old accessibility APIs from Apple's Carbon framework to tap into keyboard and mouse events as they come in, storing the information it gets in its own internal state machine. When it comes time to make a prediction, TypeBoost simply pretends to keyboard, issuing keystrokes for the rest of the characters, and then highlighting those characters. Similar APIs are tucked away within Windows, and I structured the code so it would be almost entirely reusable for a Windows version.
The second difficult part is doing the actual text prediction. Trawling through the sea of Google's publicly available ngram data, I wrote a series of programs to model and predict the English language. The original data lists all the word combinations that have appeared in books Google has scanned, and lists their frequencies by year. Using the Azure cloud and a small group of my friend's personal computers, I went through more than 10 TB of this data, filtering and combing to build a English language model that's both effective at predicting words and can fit on a personal computer. I then baked that model down to a set of data structures which I like to think of as being between a trie and a heap, which both allow context-sensitive prediction in O(1) time, and well as being quickly able to write to and from disk.
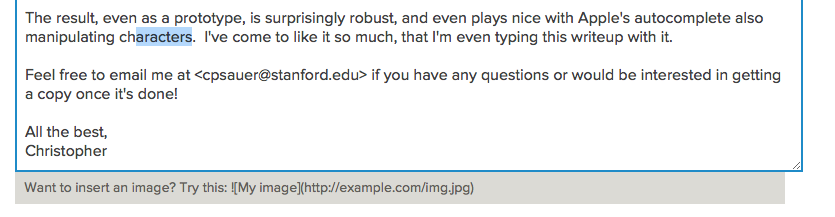
The result, even as a prototype, is surprisingly robust, and even plays nice with Apple's autocomplete also manipulating characters. I've come to like it so much, that I'm even typing this writeup with it.
Feel free to email me at cpsauer@stanford.edu if you have any questions or would be interested in getting a copy once it's done.
All the best, Christopher
P.S. I didn't have time to make a video--this was a pretty hard hack for one person--but if you'd like to see it in action, I'd love it if you'd come by and try it for yourself!
Built With
- azure
- c++
- carbon-(api)
- google-ngrams
- machine-learning
- objective-c
- objective-c++
- os-x



Log in or sign up for Devpost to join the conversation.