


Inspiration
We live in an era of information overload. Everyone has an opinion, and fact-checkers have become the ones deciding what's true. But who fact-checks the fact-checkers?
The real problem isn’t just misinformation. It’s that we’ve begun trusting our critical thinking to AI and algorithms that deliver verdicts instead of evidence.
Most tools today reduce complex claims to simple labels: True. False. Misleading. But very few show how a narrative started, what the strongest case on each side looks like, or whether the sources behind it are reliable.
This challenge especially urgent for sustainability and environmental issues, where conflicting narratives around climate change, energy policy, and environmental action drive real decisions made by real people every day.
Two Sides was inspired by a simple frustration: I wanted a tool that didn’t tell me what to believe. I wanted one that helped me think. By making evidence transparent and comparable, the goal is to empower people to evaluate complex claims for themselves.
What it does
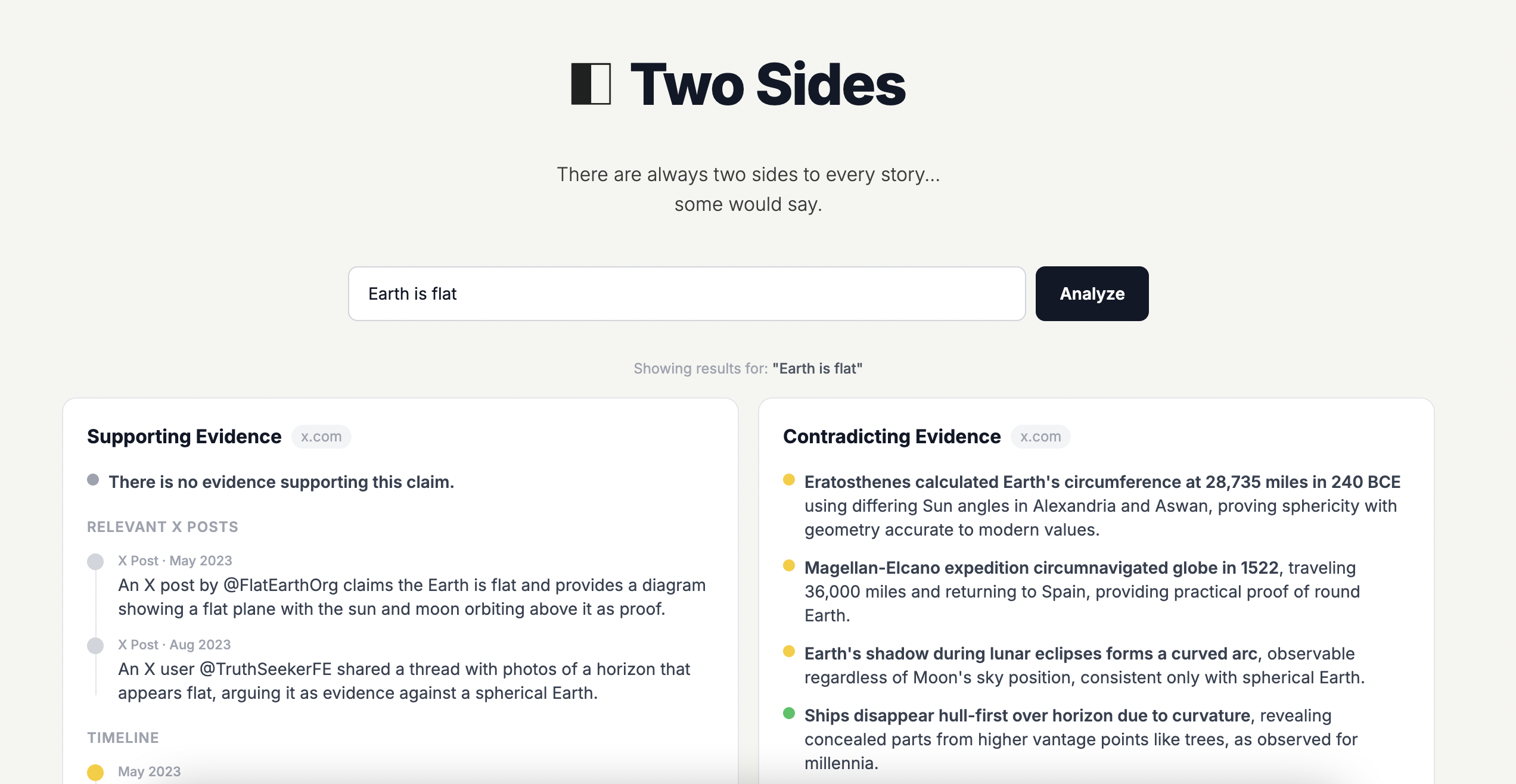
Two Sides is a media literacy web app that analyzes any claim and presents supporting and contradicting evidence side-by-side, allowing users to directly compare competing narratives.
Each claim is displayed with:
cited sources
publication dates by timeline
credibility indicators
Most LLM tools primarily retrieve information from official sources like news articles or institutional websites. But many controversial claims, niche discussions, and misinformation narratives originate on social media platforms such as Twitter and Reddit.
To capture the full picture, Two Sides integrates multiple APIs:
Perplexity for web and news evidence
Grok for discussions on X
Reddit for forum conversations
This allows the system to analyze both formal reporting and social media where narratives often begin.
Two Sides doesn’t decide what is true. It shows the evidence on both sides so you can decide for yourself.
How I built it
- Frontend: Built with Next.js and Tailwind CSS
- Evidence retrieval: Perplexity Sonar Pro — two searches run at the same time for every claim, one looking for supporting evidence and one for contradicting
- Social media: Grok (xAI) pulls live posts from X/Twitter, while Reddit is accessed through a separate API
- Credibility scoring: Each source gets dynamically scored by AI based on its editorial standards, known bias, and reliability history
- Timeline: When a claim has evidence spanning multiple months, a chronological timeline appears so you can see how the story developed over time
- Architecture: Perplexity and Grok run in parallel to keep things fast, with credibility scoring kicking in as a second pass once sources are finalized
Challenges I ran into
- The biggest challenge was getting LLMs to support a conflicting narrative without it moralizing since models naturally resist giving evidence for claims they consider false.
- Integrating three data sources (Perplexity, Grok, Reddit) turned out to be very messy. Each returned evidence in different formats and quality levels. Reddit's API was blocked entirely by Vercel's servers at deployment. After several attempts to merge everything into one unified feed, I separated them into distinct retrieval layers, each with its own summarization and credibility logic, which ended up producing cleaner results.
Accomplishments that I'm proud of
- Balanced retrieval system that presents the strongest available case for both sides of any claim, even controversial or false ones
- Dynamic AI credibility scoring that goes beyond static domain lists
- A clean, minimal UI that puts the evidence front and center without visual noise
- The timeline feature that shows how narratives evolve over time, not just a snapshot
What I learned
This was my first project where I actually deployed LLMs and worked with real API calls. Prompt engineering turned out to be the most underrated skill. The difference between a model that refuses to engage and one that returns clean structured evidence came down entirely to how the original task was framed. I also learned that building with multiple APIs means a lot of orchestration work.
What's next for Two Sides
- Improving confidence scoring and adding a quantitative bias meter that shows how strongly evidence leans on each side
- Smarter credibility scoring that goes into domain-level ratings to evaluate individual articles and authors
- Better handling of false or fringe claims and hallucinations
- Adding manipulation flags like "exaggerated language" and "scientifically unsupported" as source-level labels once the detection logic is more reliable
- Richer information retrieval pulling from more sources including academic databases and official government records
- Browser extension that lets you highlight any claim on any webpage and instantly see both sides inline
Built With
- next.js
- perplexity
- react
- tailwindcss
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.