-
-
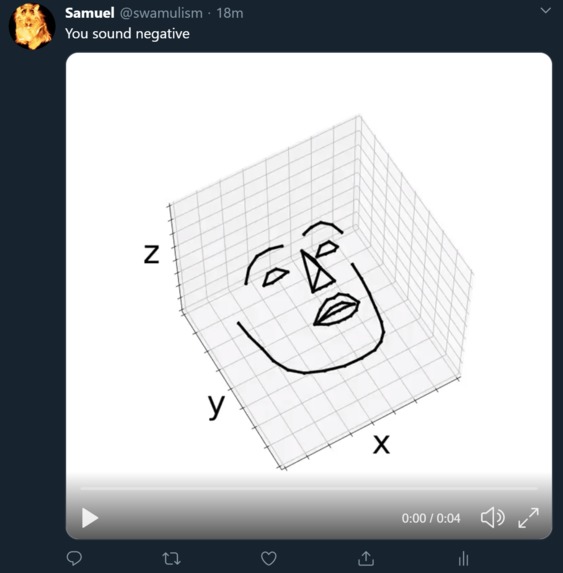
Example tweet
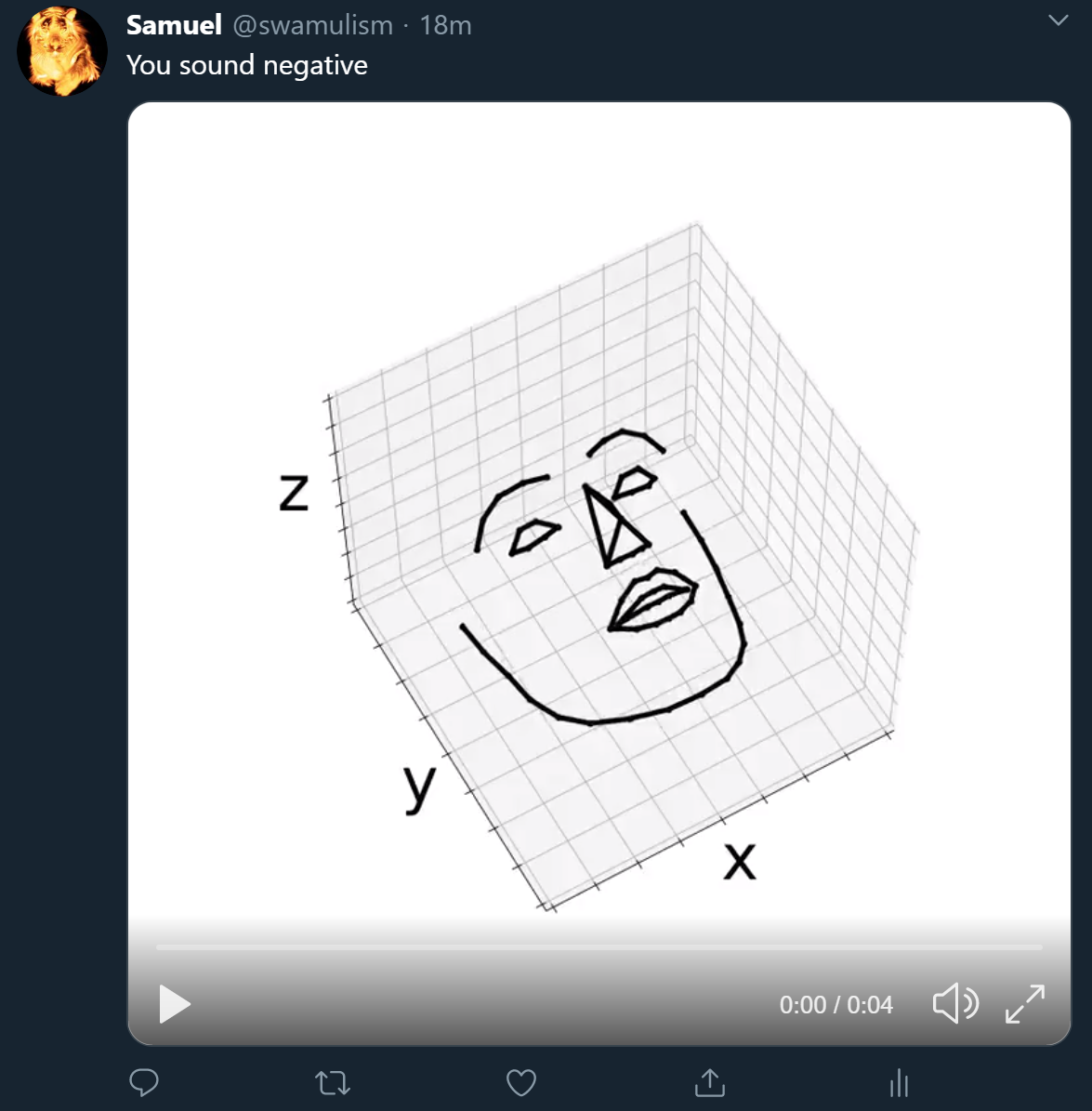
Inspiration
I wanted to do something interesting with the Twitter API and I thought the recent breakthroughs in face animation based on voice would be interesting to learn about
What it does
A bot that grabs mentions and posts a video with a face saying the tweet's content with a sentiment analysis
How I built it
I used a google cloud vm to first grab tweets that mentioned the bot, then the tweets' would be fed into a text to speech engine. Then this audio file would be fed into a research project that allows for face animation generation from an audio file. Finally a sentiment analysis would be done of the tweet and then the video would be uploaded saying the tweet sounds either positive, negative, or neutral
Challenges I ran into
There were a lot of dependency issues and not being familiar with any of the libraries I worked with made development a lot more of reading documentation rather than coding.
Accomplishments that I'm proud of
I am proud I was able to parse through a research project, integrate different unfamiliar technologies together, and finally have something that works(ish).
What I learned
I feel like I starting to get a grasp about how animations are generated using audio files.
What's next for Twitter talker
There are three main features that I would like to add
- Add real human faces instead of just a mesh, this should not be too difficult as there are ways to map the generated mesh to a real photo
- Use the sentiment analysis to choose different text to speech voices (e.g. an angry tweet will have an angry text to speech voice)
- Use the sentiment analysis to choose different faces instead of just a wire (e.g. a happy tweet will have a happy face or emoji saying the text)



Log in or sign up for Devpost to join the conversation.