
Inspiration
Social Media sites like Twitter, Facebook, etc. are like a warehouse of emotions. People tend to share their happiness, sadness and also vent out their frustrations and anger. This collection of people’s sentiments in the public domain can be of great value if utilized effectively. The applications of sentiment analysis are broad and powerful. The ability to extract insights from social data is a practice that is being widely adopted by organizations across the world. Some examples include: • Shifts in sentiment on social media have been shown to correlate with shifts in the stock market. • The Obama administration used sentiment analysis to gauge public opinion to policy announcements and campaign messages ahead of the 2012 presidential election. • The FBI is using sentiment analysis to track how ISIS or other individuals planning to execute a terror attack. The ability to quickly understand consumer attitudes and react accordingly is something that Expedia Canada took advantage of when they noticed that there was a steady increase in negative feedback to the music used in one of their television adverts.
Sentiment analysis is in demand because of its efficiency. Thousands of text documents can be processed for sentiment (and other features including named entities, topics, themes, etc.) in seconds, compared to the hours it would take a team of people to manually complete. Because it is so efficient, many businesses are adopting text and sentiment analysis and incorporating it into their processes.
However, machines still will never be able to measure sentiment as well as humans, and even humans don’t agree 100% of the time. The number of sentiment types is also part of the equation. Some platforms offer three types of sentiments, some offer four types, and some even offer more than five types. The more you increase the number of sentiment types, the less accurate your results become. And it can be hard to figure out the sentiment from say a sarcastic tweet- which sometimes even humans have a problem demystifying.
Nevertheless, if properly planned and conducted, twitter sentiment analysis can provide valuable insights that can be utilized to add great value to business decisions and processes.
In this report, we will look at the infrastructure we built for performing sentiment analysis on twitter feeds using Apache Spark and show Data Scientists can conduct exploratory analysis on tweeter feeds and build sentiment analysis models.
What it does
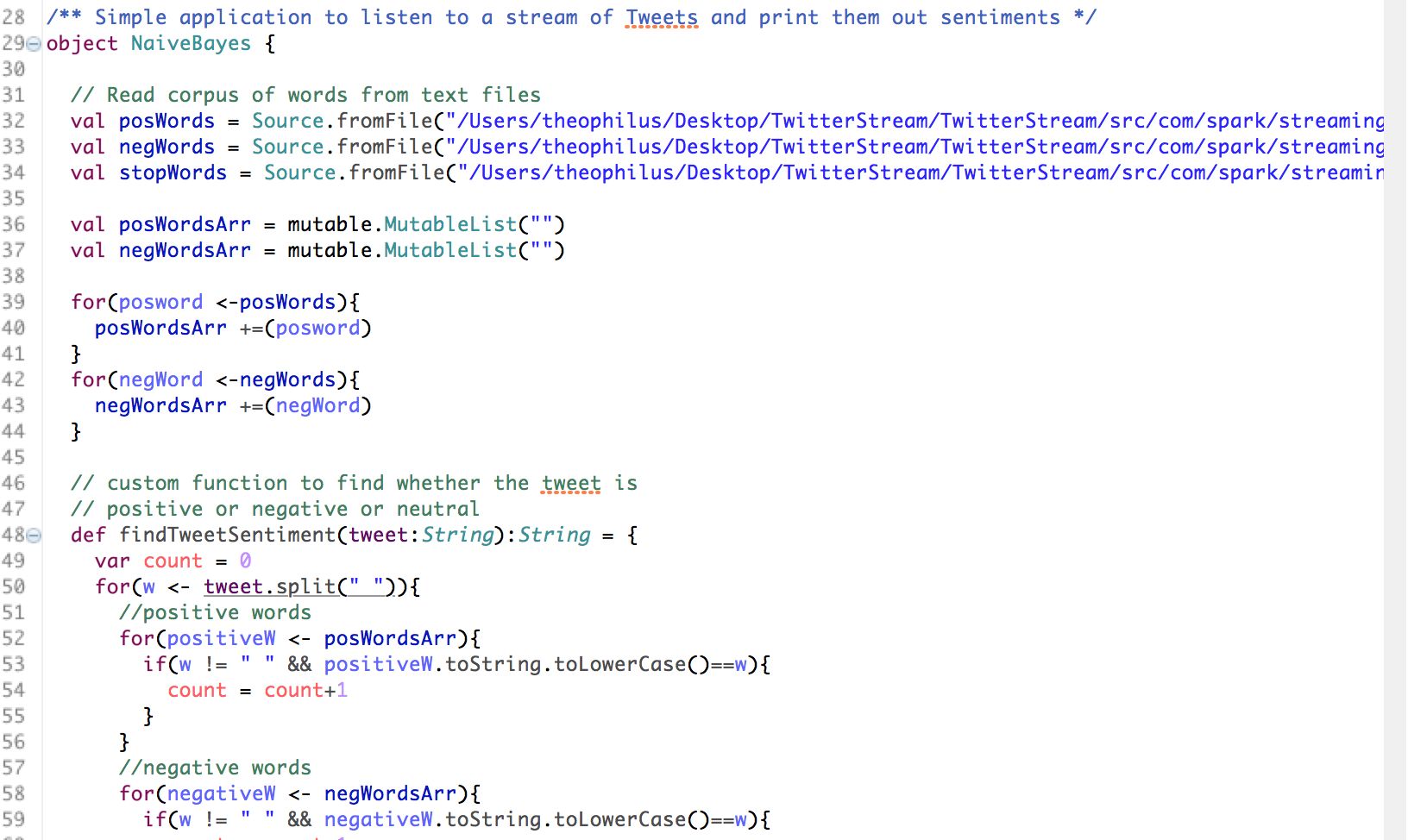
To build a data product that obtains, analyzes sentiments of a stream of tweets given the police shooting in Dallas, Texas and finally build a Naive Bayes classifier to score how well the model is performing.
How we built it
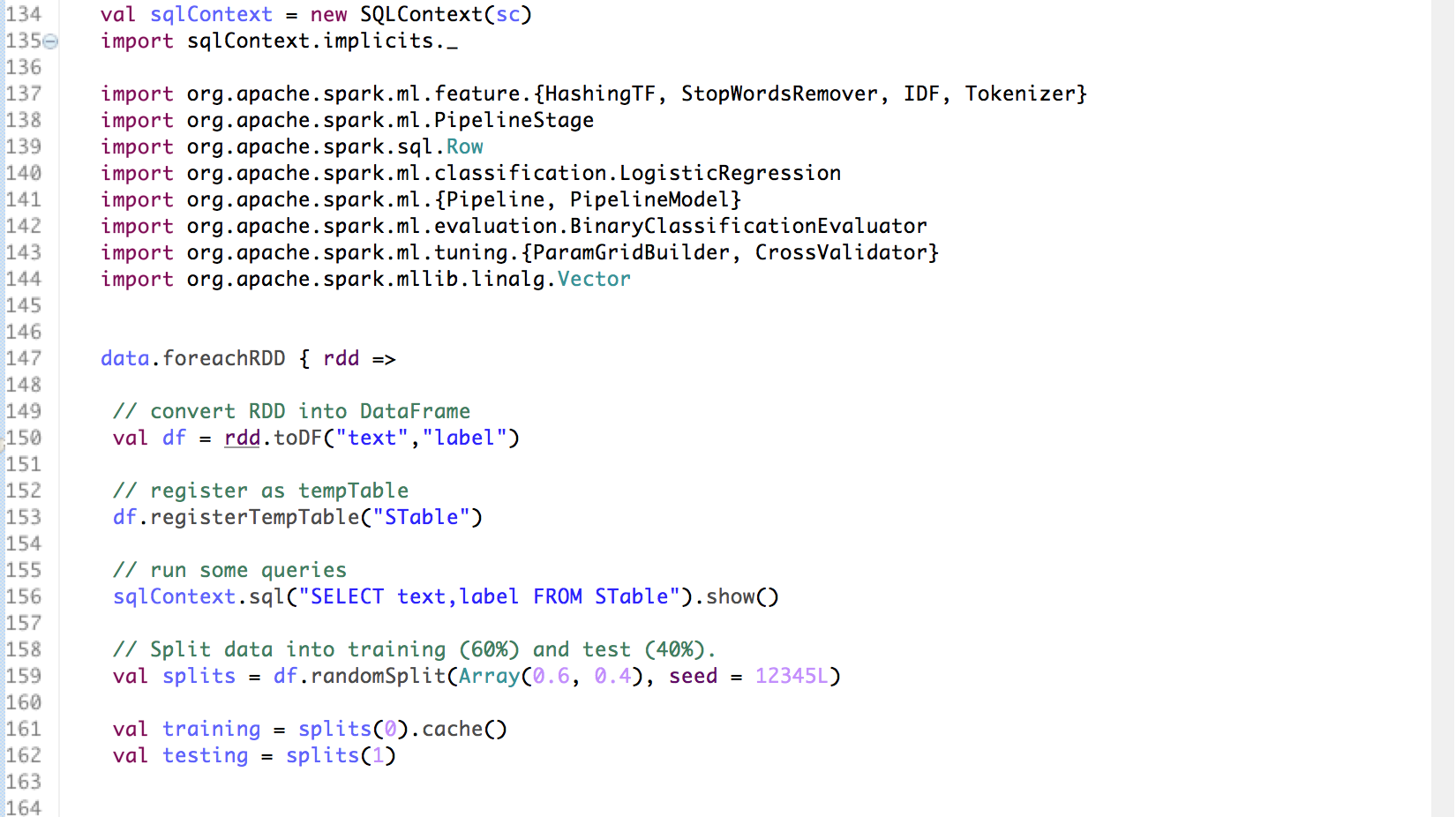
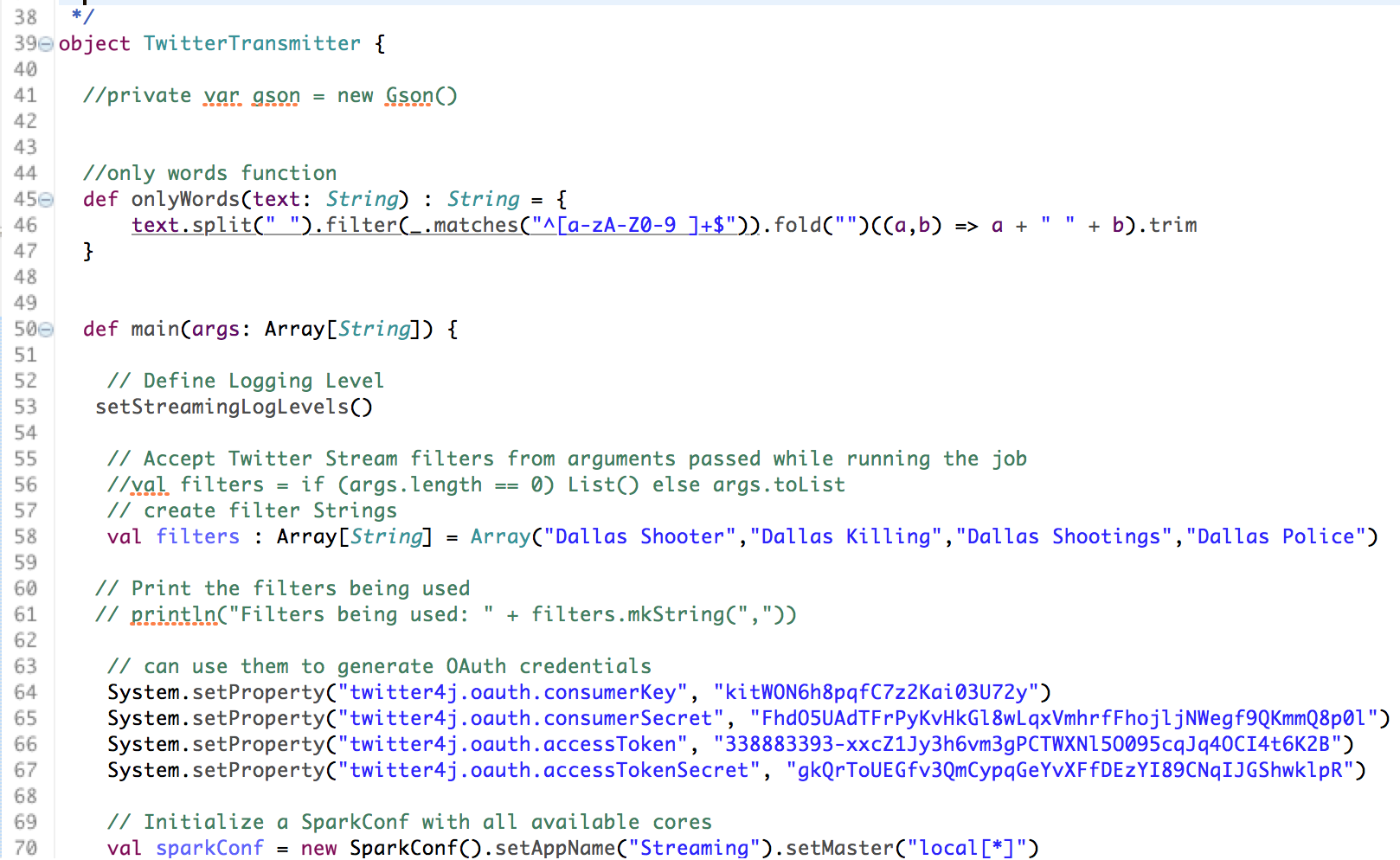
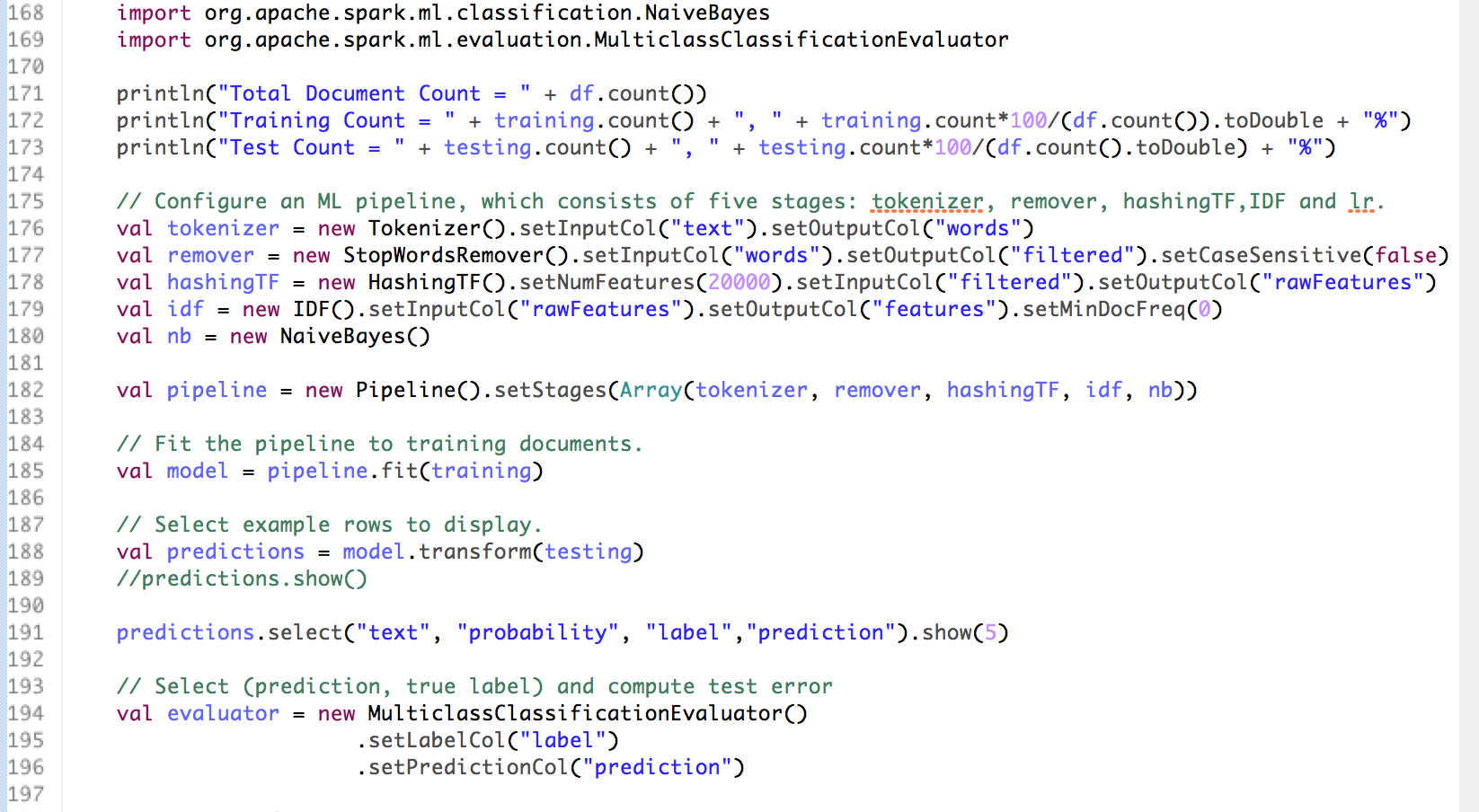
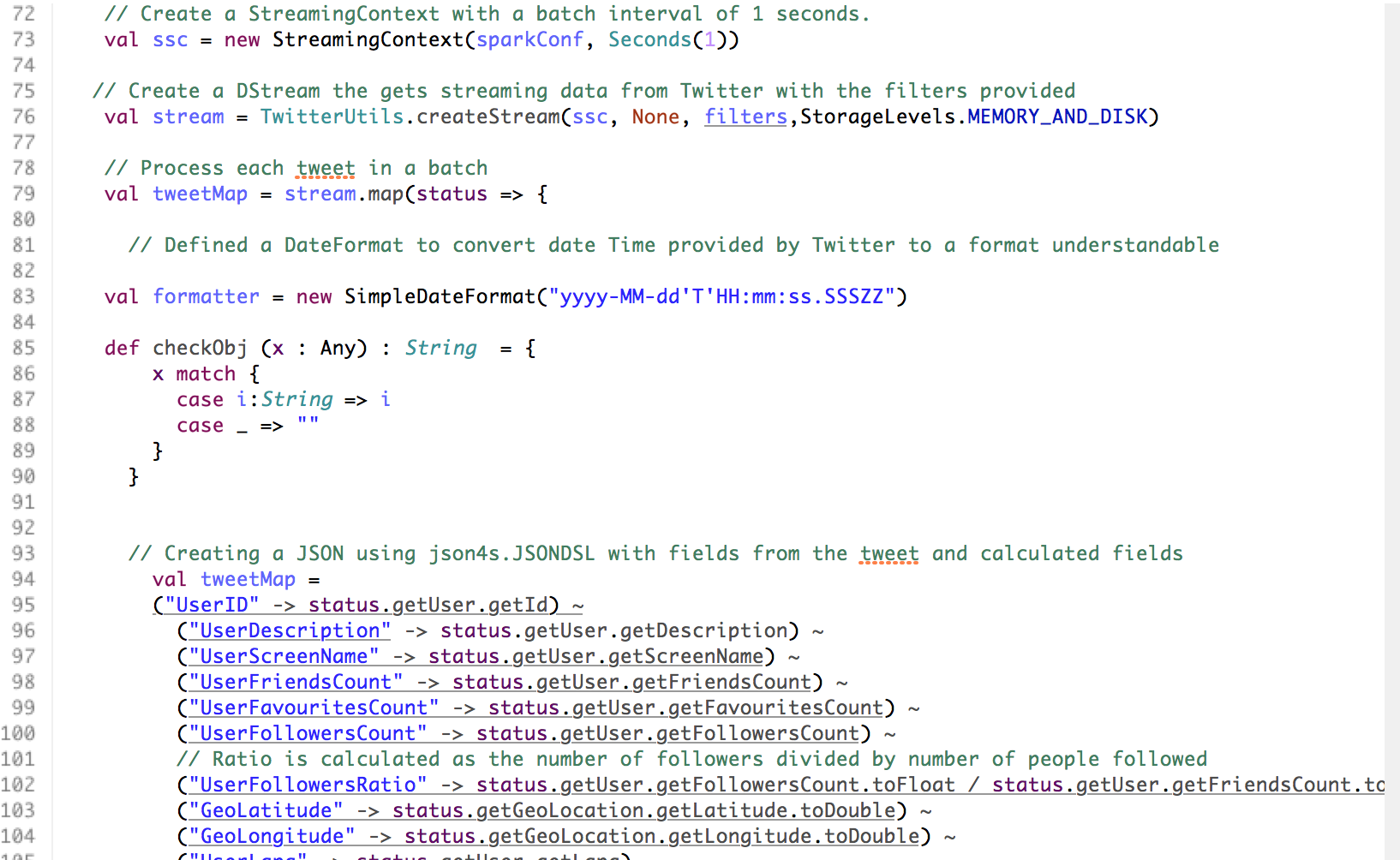
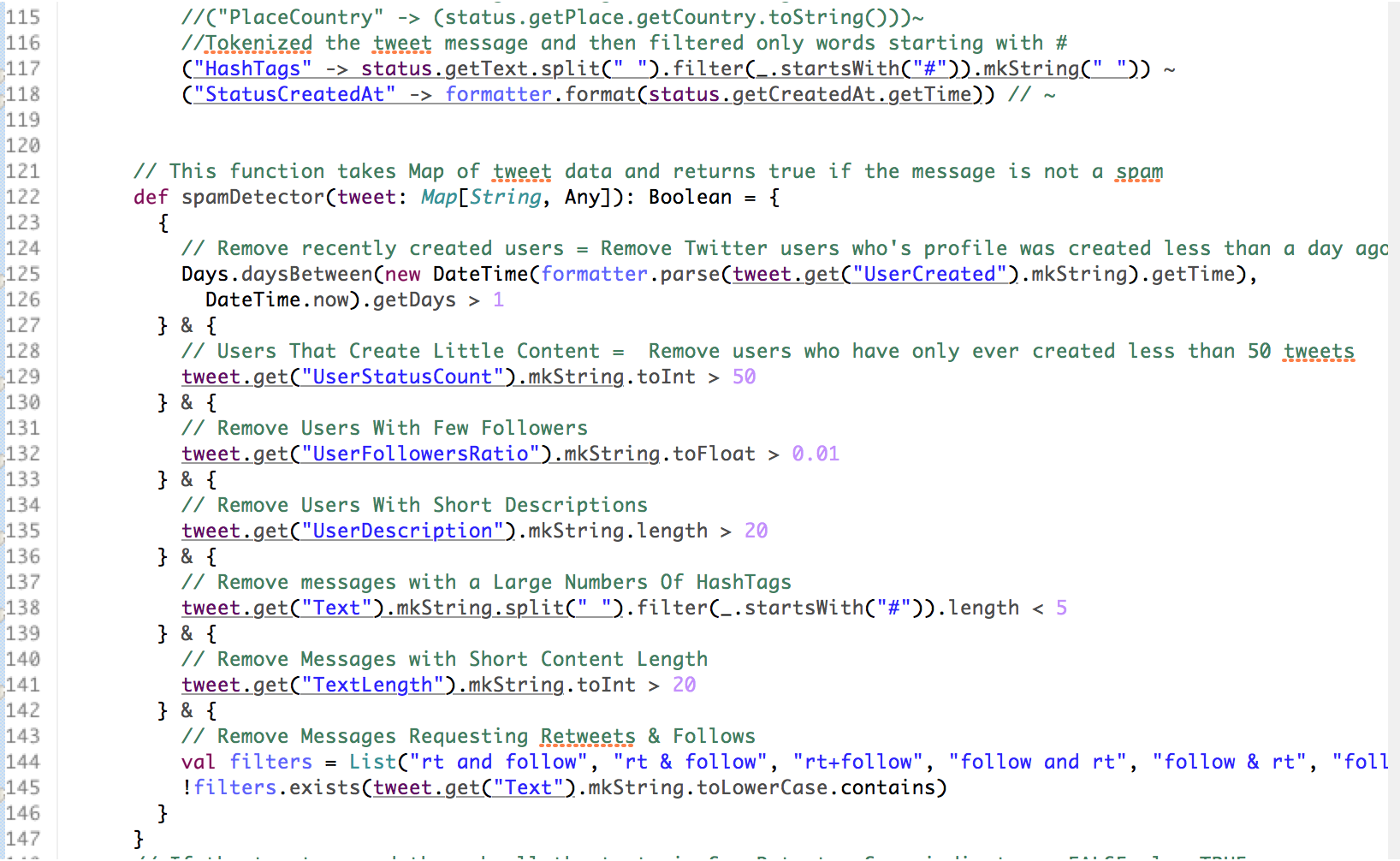
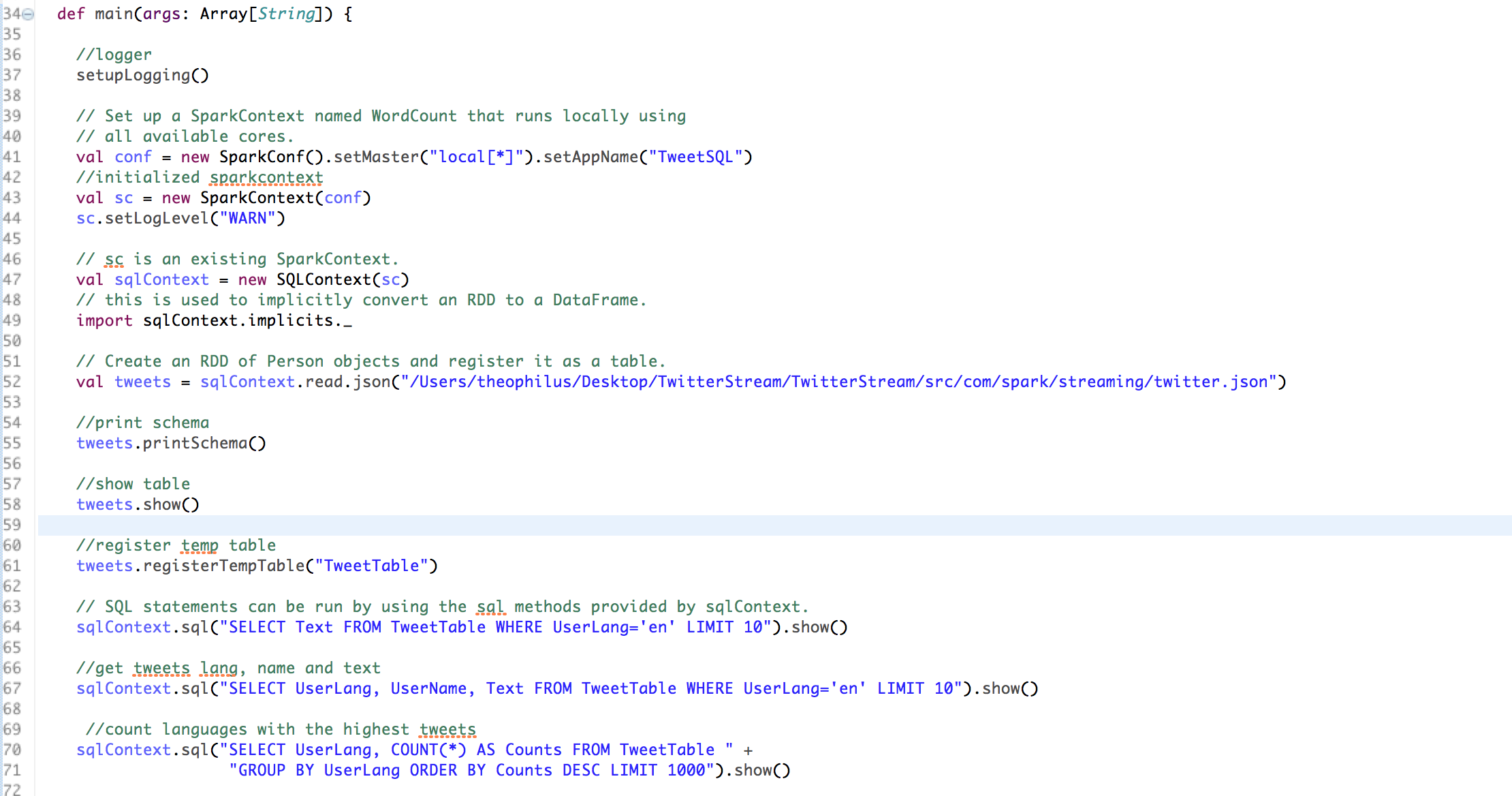
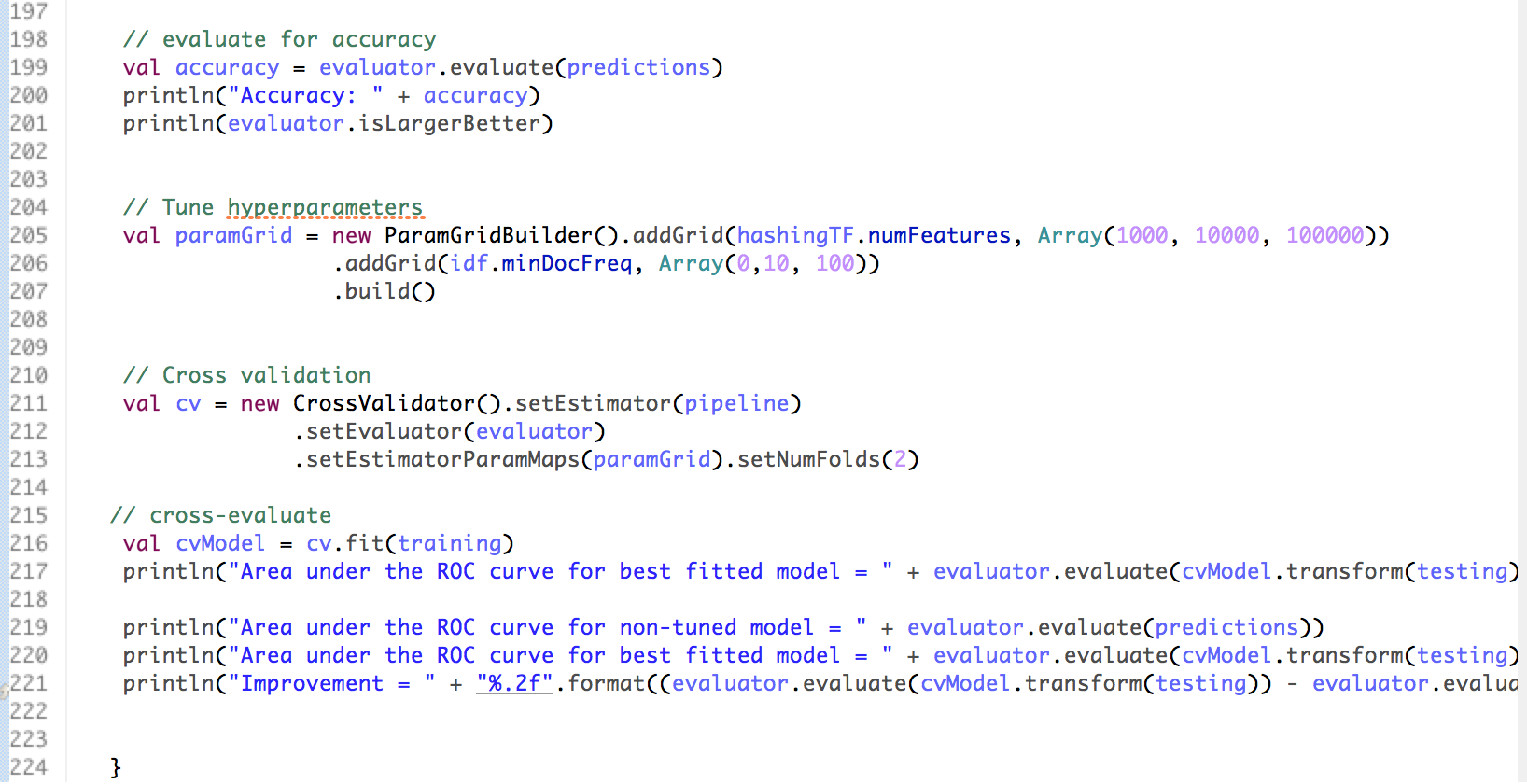
• First, we pull the incident related tweets from Twitter API by applying filter such as words related to the police shootings in Dallas, Texas. • The tweets are emitted and processed using Spark Streaming Context and written to a JSON file called twitter.json • The streams of tweets are then processed as ‘RDDs of tweets’. Each of the tweet attributes are transformed using the power of Spark SQLContext API to convert the JSON file to a structured table format for further processing. • We then run SQL queries on the structured table to conduct exploratory analysis to gain some general insights from the tweets • The tweets are later classified as positive, negative or neutral sentiments using a general collection of positive and negative words. • Using Machine Learning Pipeline and leveraging its five stages(Tokenizer, StopWordsRemover, HashingTF, Inverse Document Frequency (IDF)), we cleaned and prepared the data for model building • Finally we build a Naïve Bayes classification model on the tweets sentiments data
Challenges we ran into
• In Spark Streaming, one has to be really careful while using data taken from the streaming context. Operations performed on the RDDs should be done using transform and forEachRDD functions. • In Spark, transforming the DStreams into Data Frames can be quite a pain and one has to be cautious in order to maintain the schema properly. • While streaming into your local disk, one has to limit the number of tweets that are coming in to prevent disk from getting fully loaded with streams of tweets. • One has to also make sure all spam related tweets are filtered out to avoid writing meaningless data into database files or text files. • There is no spark API currently available for graphical visualization of results but there are other external tools like plotly than could be used.
Accomplishments that we're proud of
Spark provides a friendly and efficient platform cluster computing. Leveraging this platform, we successfully build scala and spark application infrastructure that analyzes the sentiments of tweets streamed about the Dallas Police Shootings, except that we did not include any form of graphical visualization in our reports since we restricted our domain on spark and scala. Most of the tweets that came in at each run of the application, were mostly negative tweets as compared to the positive and neutral tweets. Our biggest accomplishment is that we could incorporate this application into marketing campaign to see how customers feel about certain products and services.
What we learned
We came to learned that processing of text could be very challenging. Dealing with sarcasm is one of the major problems in text analytics.
What's next for Twitter Sentiment Analysis of Dallas Police Shooting
Given our time constraint, not all special features for tweeter analysis and predictive modeling within Spark were utilized. Below are some other interesting dimensions we will continue to add to this project in the future • Geo-spatial maps could be plotted, signifying the location (and sentiment) of the tweets. • Creating dashboards to monitor all incoming tweets, user interaction and present results in a visually appealing manner. • Creating a pipeline to dump all processed tweets into HDFS, Databases like Cassandra, Mongo DB, PostgreSQL or MySQL. • This project can be incorporated into marketing campaigns in order to make decisions.


Log in or sign up for Devpost to join the conversation.