-
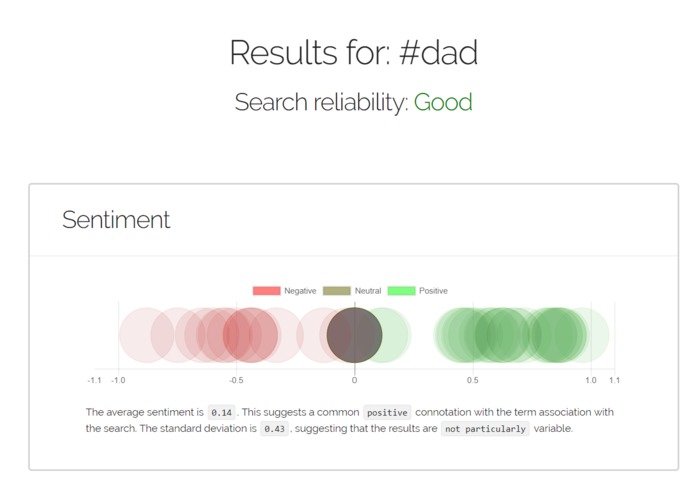
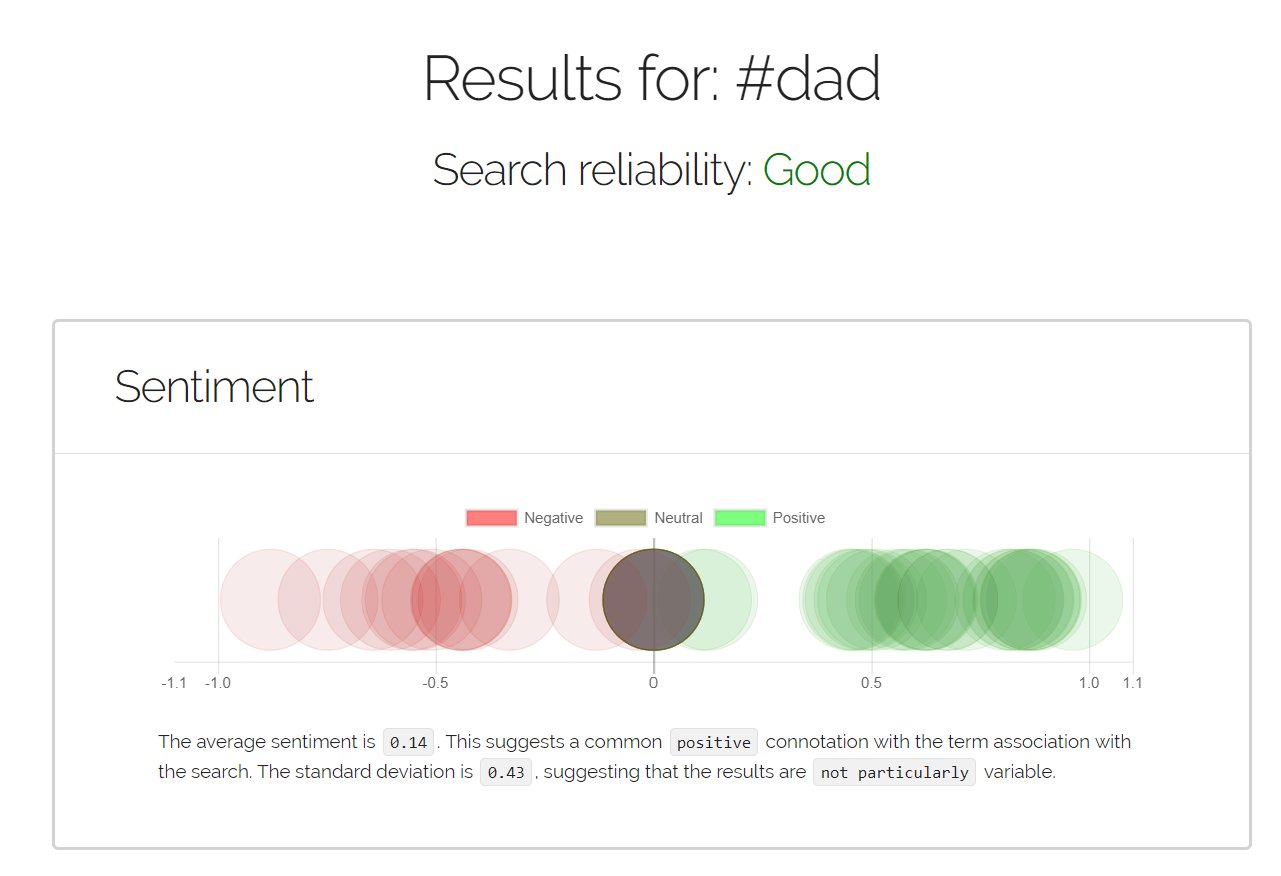
Sample Results
-
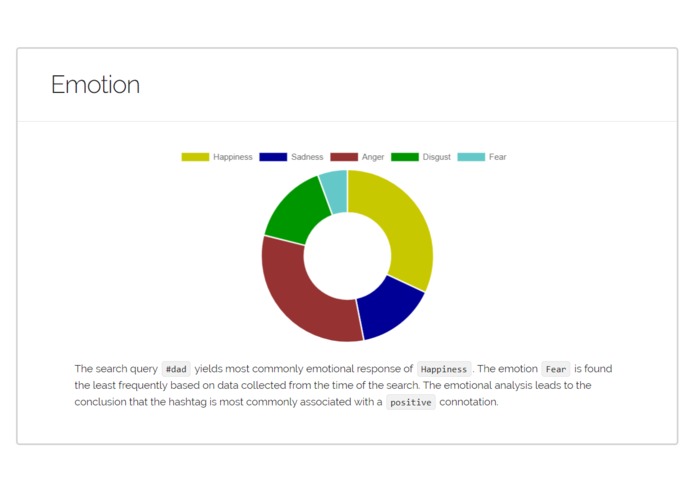
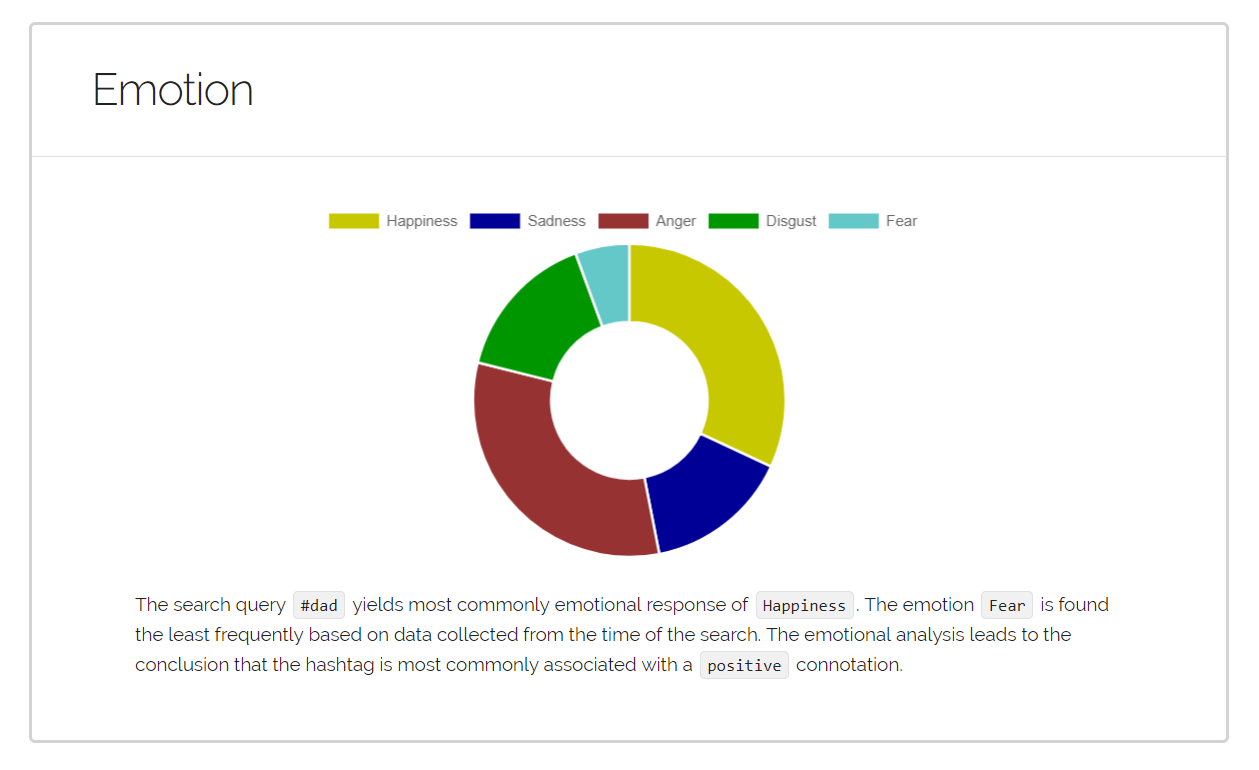
More Sample Results
Inspiration
The inspiration came from long hours on social media, and the understanding that all accounts and feelings may, in fact, have a connection between them -- a link that has properties that are traceable. We began to consider the qualities found in IBM Watson and began to look into web devlopment as a way to represent these links. Twitter has been in the national spotlight in recent times, which made it the obvious choice.
What it does
The program provides results for a given query (either a phrase or a hashtag); starting by compiling a clean list of tweets and their vital information, such as hashtags, mentions, content. These results are then processed by the IBM Watson National Language Understanding API; which allows for the recognition of various emotions in each tweet as well as the recognition of sentiment of each tweet. Each of these tweets in the set were then compared to each other and the results were embedded into the results page of our website.
How we built it
There are four major languages/scripts used to create this project alongside numerous APIs. It all starts with the Twitter Search API, which allows us to retrieve information on a large number of recent tweets. This information is then processed with PHP, that feeds it into the Watson Natural Language Understanging API. From here, the results are formatted into an JSON file which is sent to client side Javascript for analysis. The Javascript then formats the information and organizes it into interactive visuals that are then placed onto the responsive design webpage created from HTML.
Challenges we ran into
The largest challenge of integration. Our integration struggles came in two forms- one was the connection of the APIs, and the other was personell integration. We were well aware that even the smallest bug would come back to haunt us, any small problem would compound over time. With each API, we saw that there were it's own problems to deal with, and it was challengin to bring them back to a common code towards the end of each of their uses. We had one new member to hackathons, and one member with only one hackathon of experience. Nevertheless, we found that, in the beggining, it was hard to working to each other's strength. This challenge of working to each other's strength soon became one of our greatest strengths towards the end; not only did we overcome the issue, we were able to have specialization to accompany breadth of knowledge towards the end.
Accomplishments that we're proud of
We were very proud of the initial responsive design of the website-- mostly becuase of what it represented for us. It was a stretch goal for us to be able to make such an active, advanced website, and that goes to show that we were succesful in the completion of the base model of the project relatively quickly. This gave us the freedom and flexibility to keep on adding right until the very end, something that we made use of thoroughly. We are also very proud of the accuracy that was presented by the topic, if we inserted a charged topic, we were able to recieve skewed results that aligned perfectly with our thoughts from looking through the tweets manually. This gave us the satisfaction of knowing that not only had we made a complete product, we had been able to give it that humanness that we felt like was missing from a lot of IBM watson analyses.
What we learned
We learned how to use PHP, for two of our three members, PHP was completely new, and we were able to become familiar with it relatively quickly. With that said, the best thing that we picked up on is how to apply Computer Science knowledge as a whole to specific tasks and integrate them nicely without familiarity. We learned that a Web Development using API's has small nuances, but the overarching concepts remain the same. That is what allowed us to be succesful in our project.
What's next for Twitter Feels
The next step will be to keep on expanding. This is a process that can eventually be applied to more and more tweets, and over time, the number of parameters can be expanded. We can use the information to not just understand hashtags, but to analyze varying sets of data that are more than just the recent. We will work to establish a time-based version of Twitter Feels, which would be a reflection of people's thoughts at various snapshots in time, allowing us to create one large societal "image" using these snapshots as a basis to understand progression with respect to time.
Built With
- css3
- html5
- ibm-watson
- javascript
- php
- skeleton.css



Log in or sign up for Devpost to join the conversation.