-
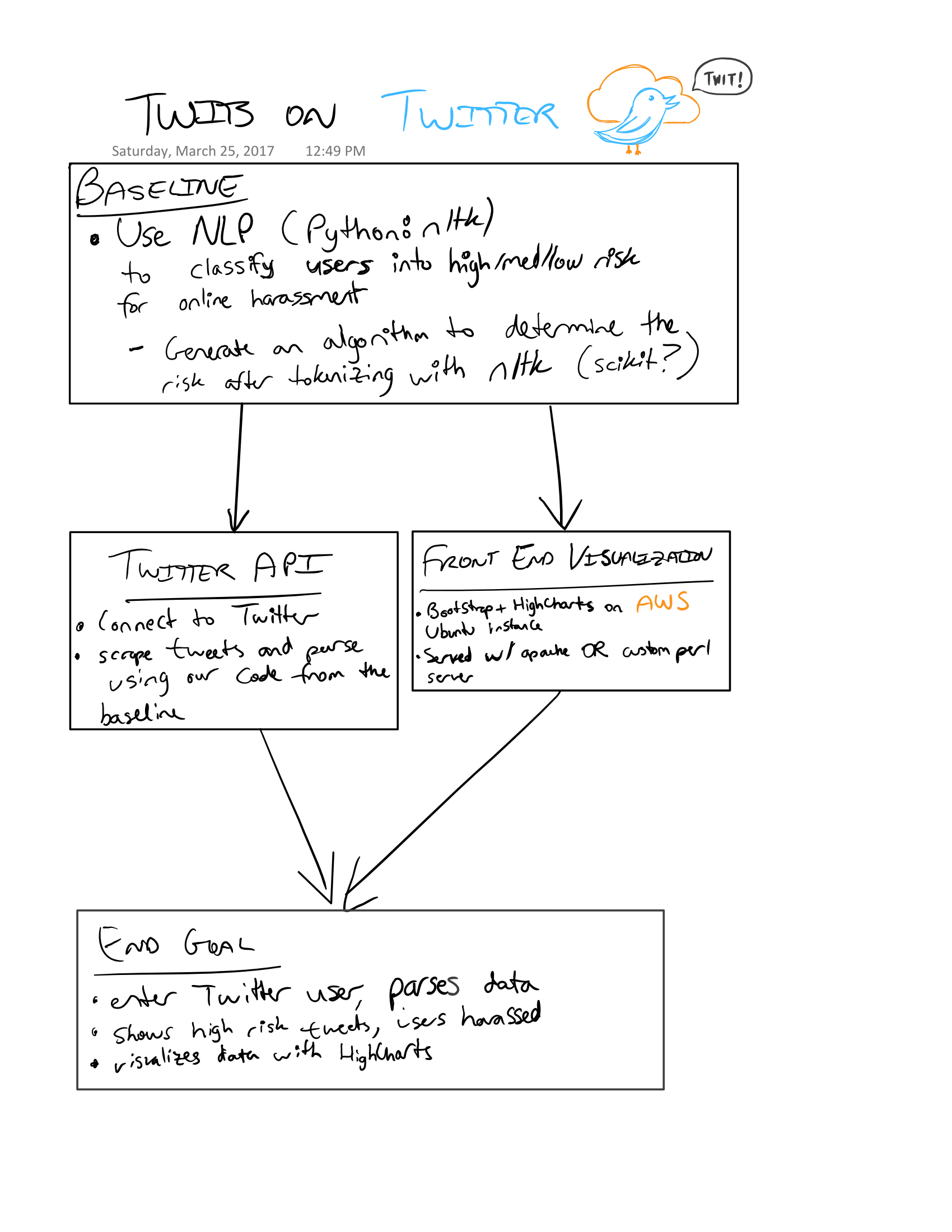
A high level abstraction we did at the start of the hackathon.
Inspiration
Our inspiration for this project is to combat online harassment, in correspondence with the anti online harassment theme for CrimsonHacks2017.
Specifically, we created a back end that could help moderators review content flagged by a machine learning algorithm, or that could be used to create an intelligent automatic moderating system, powered by a system that always learns. We used Twitter to demo our back end.
What it does
TwitsOnTwitter takes a Twitter handle from the user and grabs the last 200 tweets, and feeds them through our machine learning model (specifically, a support vector machine) to classify whether the tweet may be potentially harassing in nature. This data is visualized in the user’s browser, and specific harassment cases can be reviewed by clicking on the chart.
While the scope of this project is limited to Twitter, the back end could be expanded to accommodate any different social media platforms, online forums, and etc. This could be useful for automatically managing users’ behavior, and/or assisting a human moderator in reviewing and moderating online harassment.
How we built it
We built ToT using a t2.micro Ubuntu EC2 instance on Amazon Web Services (AWS). For the backend, we used a custom Perl server to serve HTTP and HTTPS requests instead of using a standard apache/nginx webapp. For good measure, we used Let’s Encrypt to generate an HTTPS certificate after registering twitsontwitter.net using domain.com. We used AWS’s Route 53 so that DNS requests would route to our EC2 instance’s Elastic IP. We used Python for natural language processing, which used a support vector machine algorithm to determine whether or not sample text could be considered online harassment. Specifically, we used Python’s nltk and scikit-learn libraries. For the frontend, we used a small bit of Bootstrap and Highcharts to visualize the data. On the server side, we used a Python wrapper to interact with Twitter’s API. We used AJAX to communicate with the server, and the server responded with JSON data, which was parsed with JavaScript.
Challenges we ran into
Lack of experience with machine learning and NLP led to a less than ideal machine learning model. Web development can be a lot harder than it looks! Insufficient training data with our algorithm seemed to lead to a lot of false positives. Trying to combine perl and python on the server side proved to be more difficult than expected.
Accomplishments that I'm proud of
HighCharts, while difficult at times, was impressive. The NLP algorithm was surprisingly decent, given our training set (and given the actual algorithm). We visualized and got to our end goal in 24 hours!
What we learned
We found how to break the communication barrier between programming languages and interactions between the client and server.
Lots of HTML, CSS, Bootstrap, and HighCharts was learned for the front end implementation. Perl’s CGI module, using Python with nltk and scikit-learn were learned to implement the back end.
We spent quite a bit of time learning to efficiently debug using Chrome’s Developer Console, a Perl error logging/debugging module that we created, and stacktraces on Python.
What's next for Twits On Twitter
There are many ways we can improve ToT. The machine learning algorithm definitely needs improvement to lead to fewer false positives and a higher detection rate for actual harassment. The UI needs more pretty charts. It also needs to be prettier itself. Real time moderation features could be added. Using the ML algorithm, we could expand to many different platforms including Reddit, Facebook, and Youtube by utilizing their APIs. We could integrate our ML solution into a social media-esque site looking to moderate users’ behavior related to harassment.



Log in or sign up for Devpost to join the conversation.