-
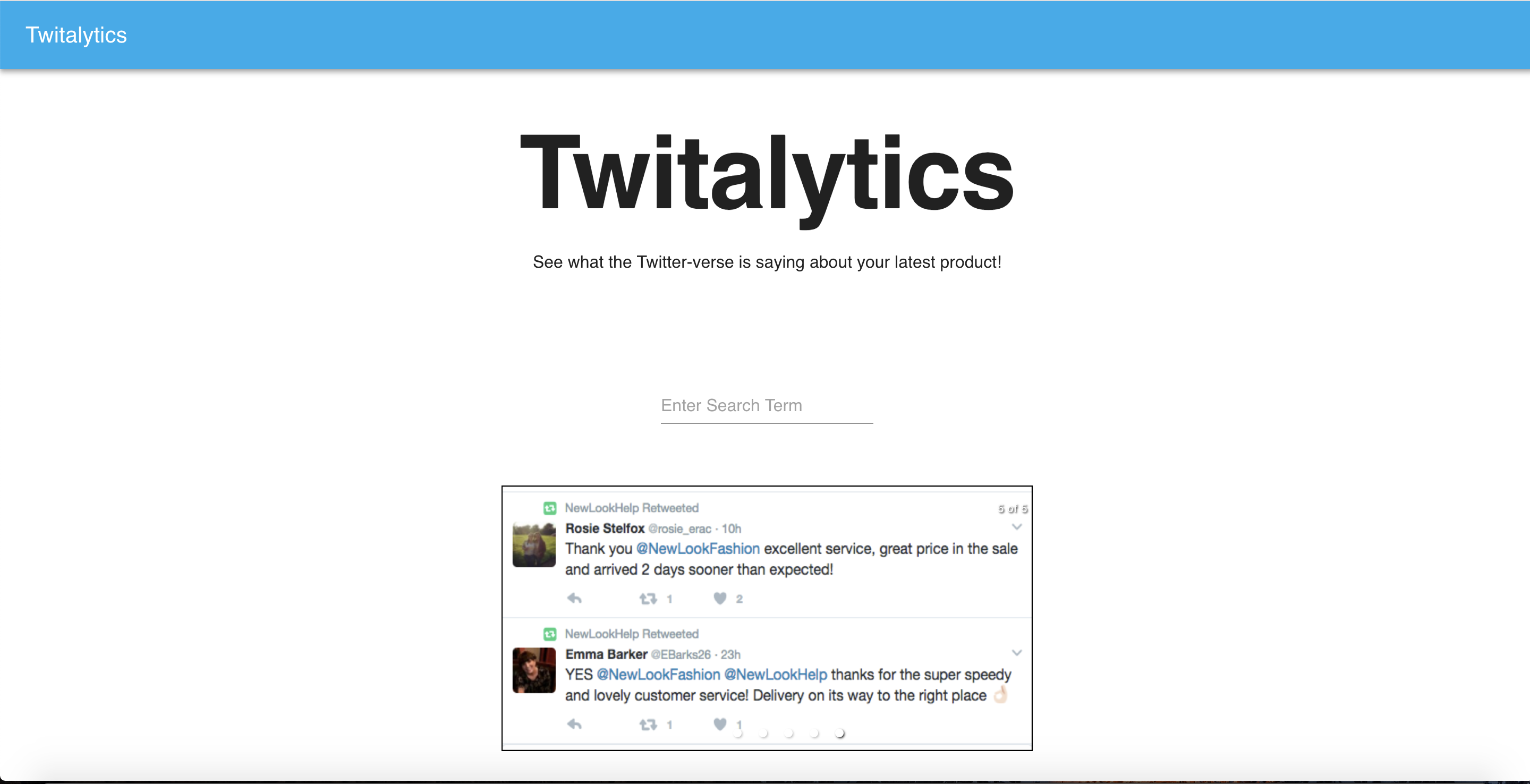
Home Page
-
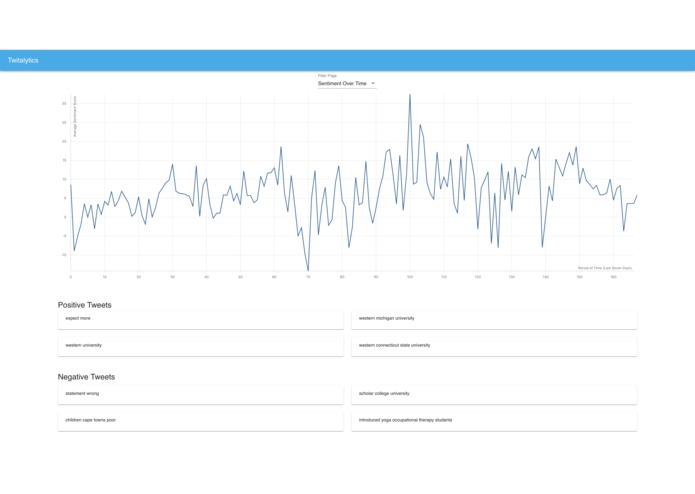
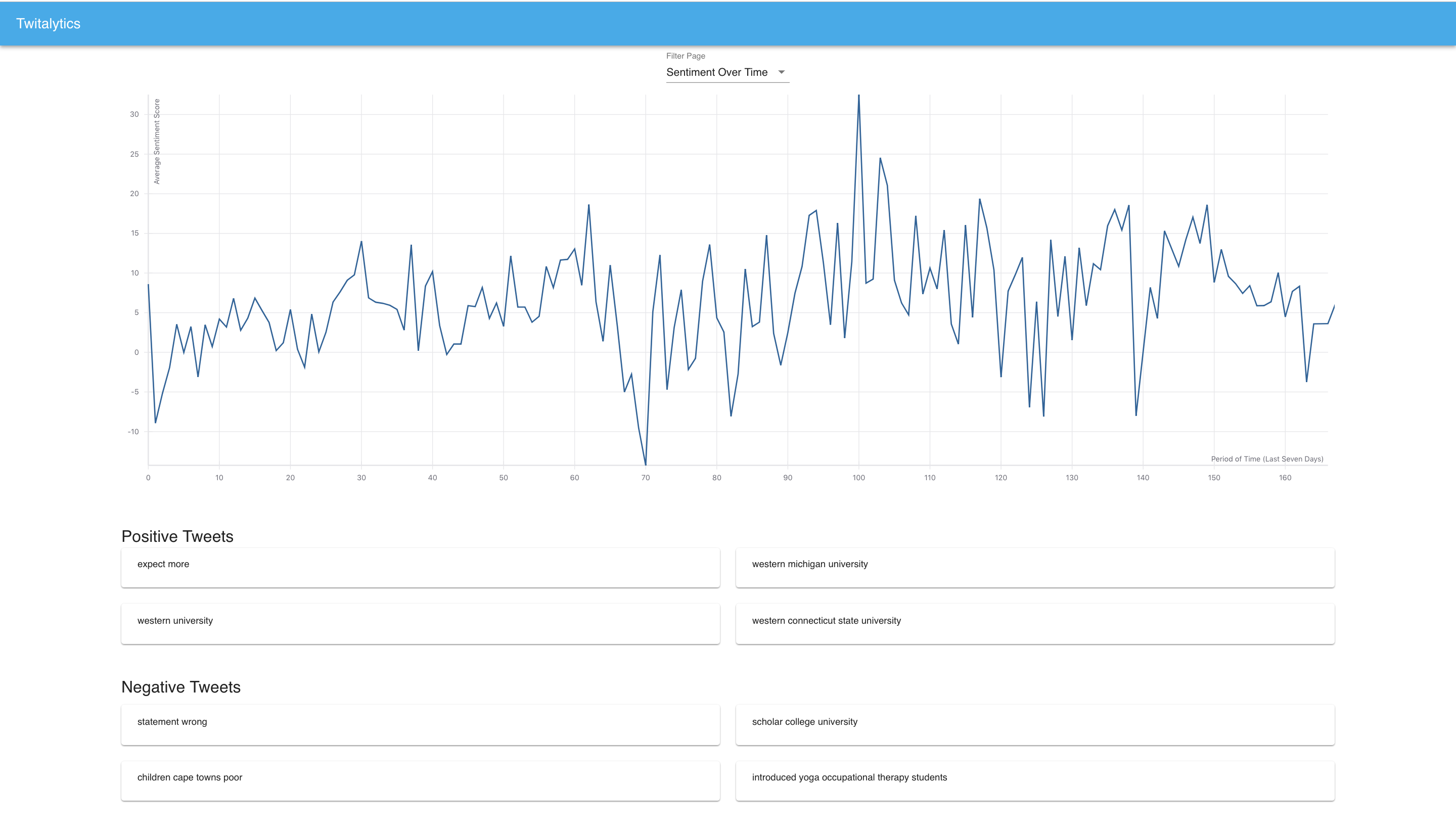
Sentiment Over Time
-
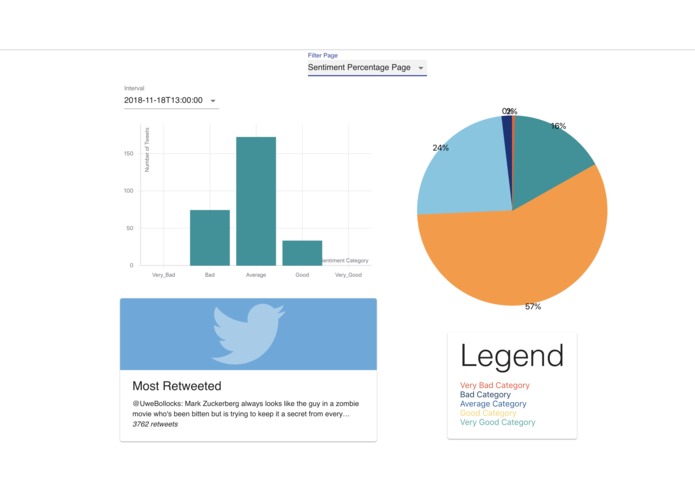
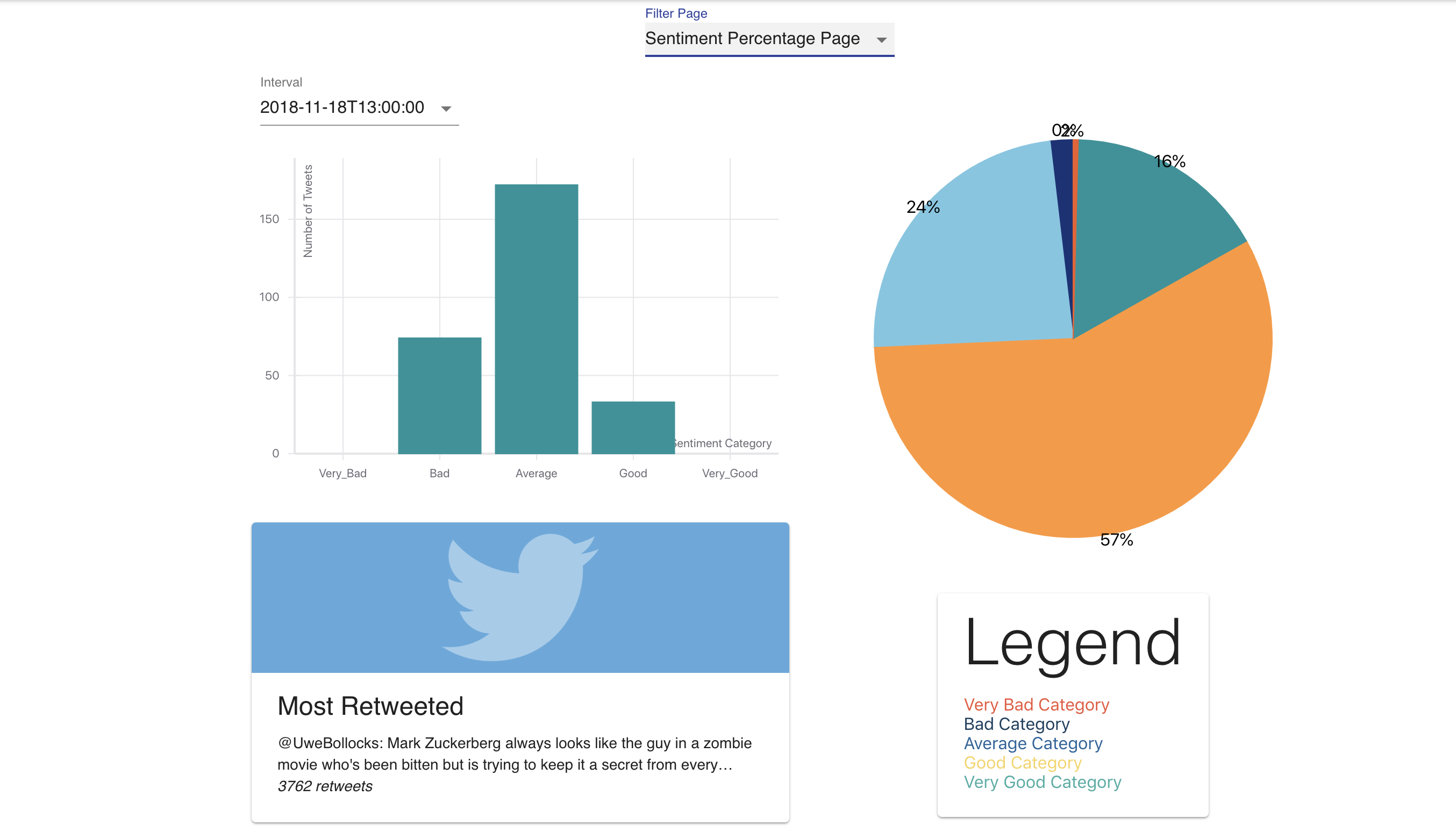
Sentiment Percentage
-
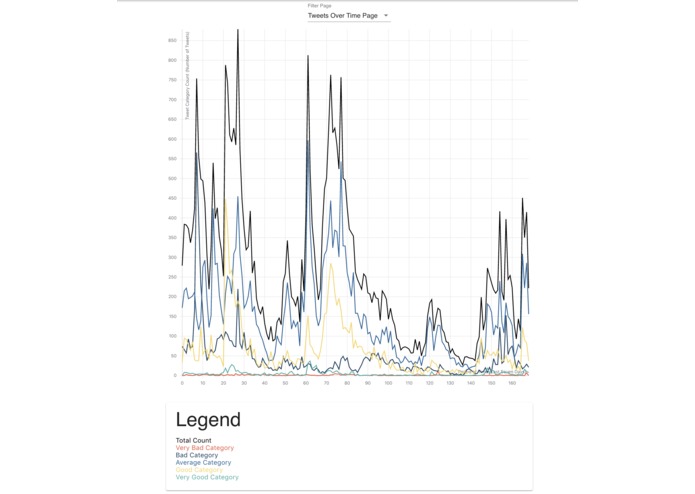
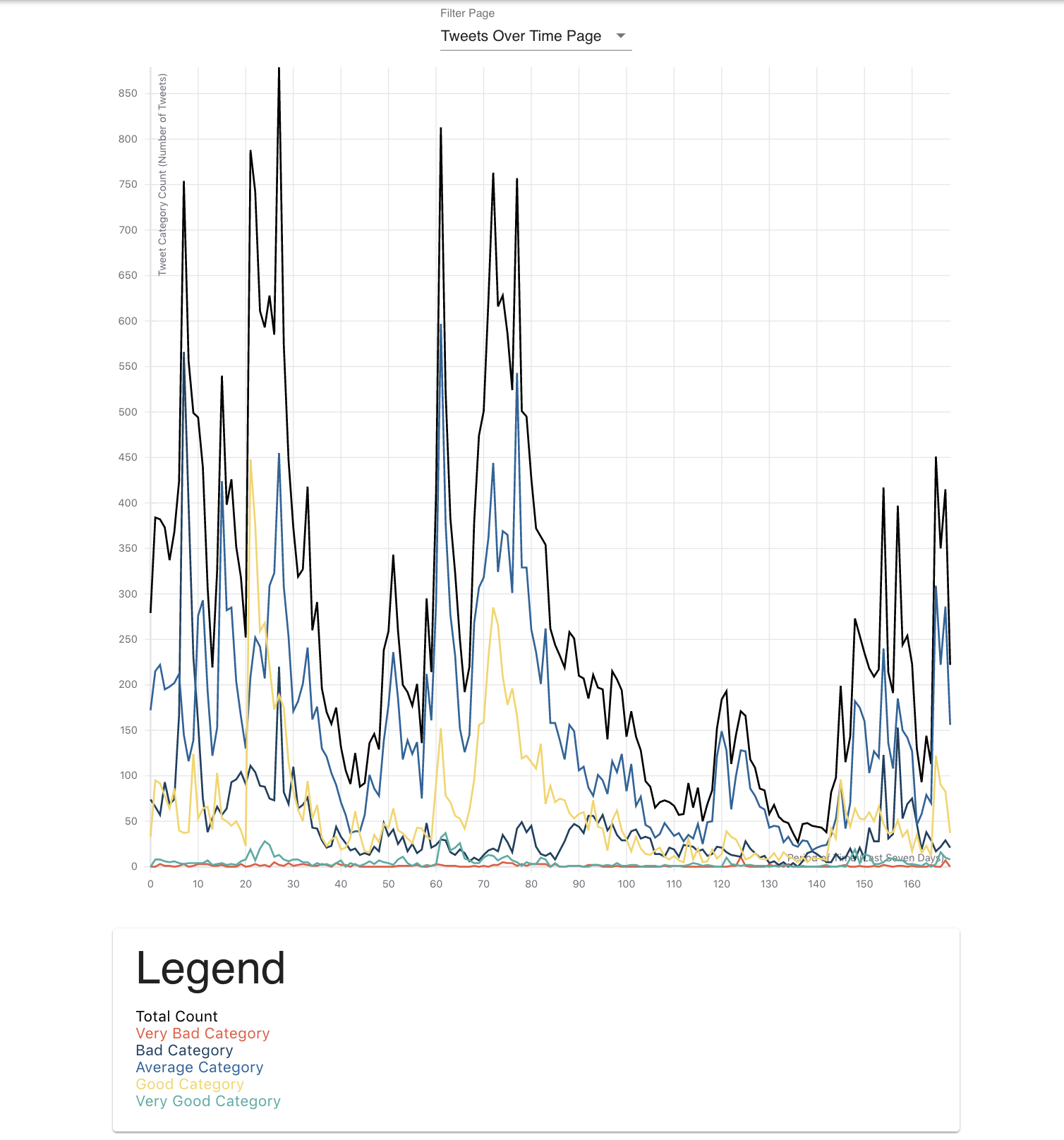
Tweets Over Time
Inspiration
Want to see how a product, service, person or idea is doing in the court of public opinion? Market analysts are experts at collecting data from a large array of sources, but monitoring public happiness or approval ratings is notoriously difficult. Usually, focus groups and extensive data collection is required before any estimates can be made, wasting both time and money. Why bother with all of this when the data you need can be easily mined from social media websites such as Twitter? Through aggregating tweets, performing sentiment analysis and visualizing the data, it would be possible to observe trends on how happy the public is about any topic, providing a valuable tool for anybody who needs to monitor customer satisfaction or public perception.
What it does
Queries Twitter Search API to return relevant tweets that are sorted into buckets of time. Sentiment analysis is then used to categorize whether the tweet is positive or negative in regards to the search term. The collected data is visualized with graphs such as average sentiment over time, percentage of positive to percentage of negative tweets, and other in depth trend analyses. An NLP algorithm that involves the clustering of similar tweets was developed to return a representative summary of good and bad tweets. This can show what most people are happy or angry about and can provide insight on how to improve public reception.
How we built it
The application is split into a Flask back-end and a ReactJS front-end.
The back-end queries the Twitter API, parses and stores relevant information from the received tweets, and calculates any extra statistics that the front-end requires. The back-end then provides this information in a JSON object that the front-end can access through a get request.
The React front-end presents all UI elements in components styled by Material-UI. React-Vis was utilized to compose charts and graphs that presents our queried data in an efficient and visually-appealing way.
Challenges we ran into
Twitter API throttles querying to 1000 tweets per minute, a number much less than what this project needs in order to provide meaningful data analysis. This means that by itself, after returning 1000 tweets we would have to wait another minute before continuing to request tweets. With some keywords returning hundreds of thousands of tweets, this was a huge problem. In addition, extracting a representative summary of good and bad tweet topics was challenging, as features that represent contextual similarity between words are not very well defined. Finally, we found it difficult to design a user interface that displays the vast amount of data we collect in a clear, organized, and aesthetically pleasing manner.
Accomplishments that we're proud of
We're proud of how well we visualized our data. In the course of a weekend, we managed to collect and visualize a large sum of data in six different ways. We're also proud that we managed to implement the clustering algorithm. In addition, the application is fully functional with nothing manually mocked!
What we learned
We learnt about several different natural language processing techniques. We also learnt about the Flask REST framework and best practices for building a React web application.
What's next for Twitalytics
We plan on cleaning some of the code that we rushed this weekend, implementing geolocation filtering and data analysis, and investigating better clustering algorithms and big data techniques.


Log in or sign up for Devpost to join the conversation.