-

TweetX Logo
-
Stock Ticker Python File

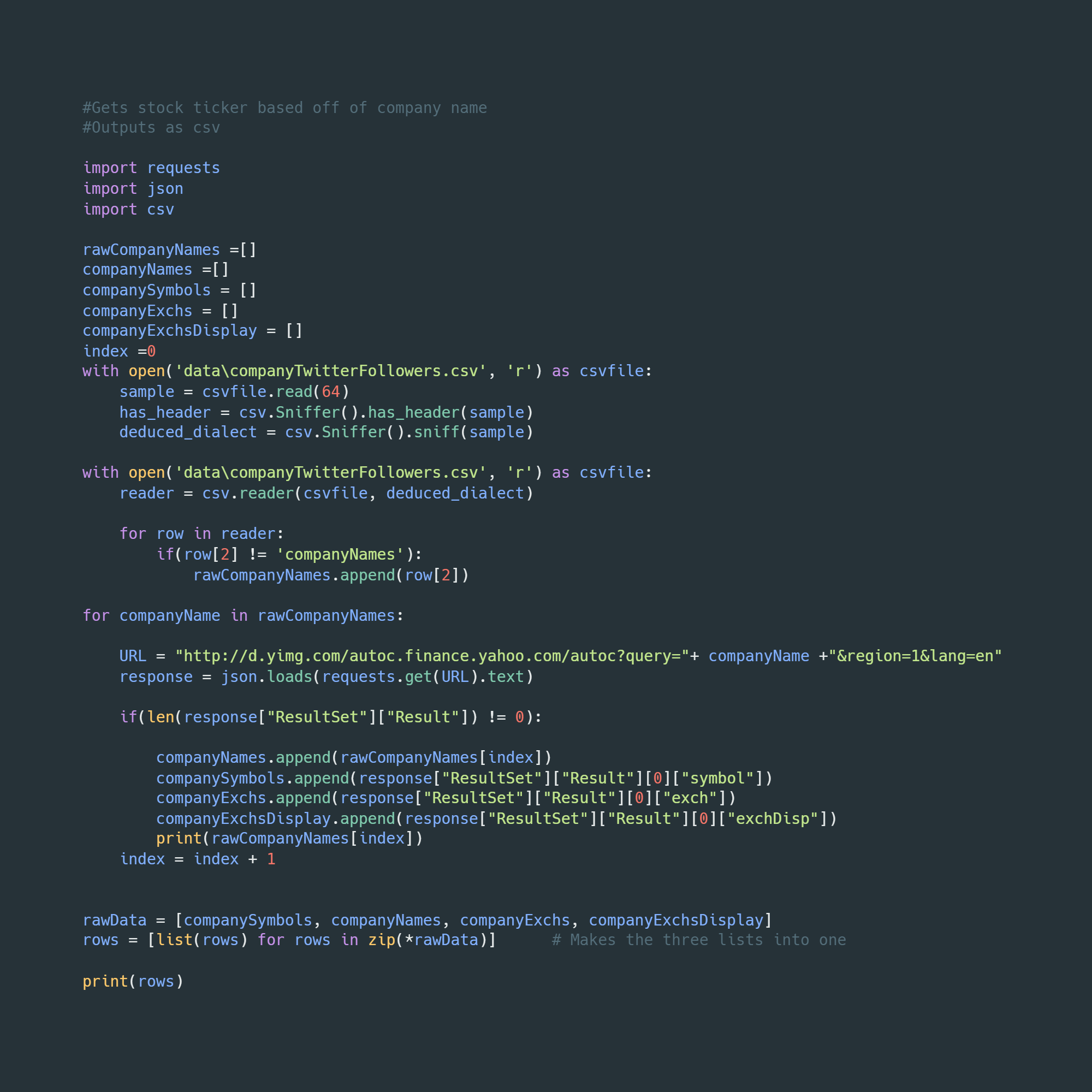
Investing in stocks based on the popularity of a company or its public figures is a common practice. To cater to this market, a new approach has been developed using web scraped data, with the assistance of tools such as Vscode, Adobe Dreamweaver, and Figma. The process involved dealing with large CSV files containing Twitter accounts for numerous companies, which were then parsed and filtered using a web scraper with full functionality. Handling data from multiple datasets presented several challenges, which were overcome using various techniques. To enhance the accuracy of the collected data, the Twitter API was used to query the scraped data.
Built With
- beautiful-soup
- css
- figma
- html
- javascript
- python
- yahoo-fin




Log in or sign up for Devpost to join the conversation.