-
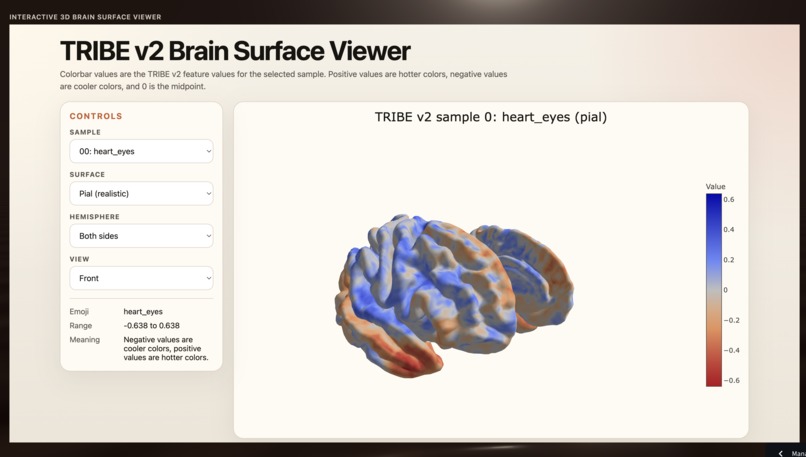
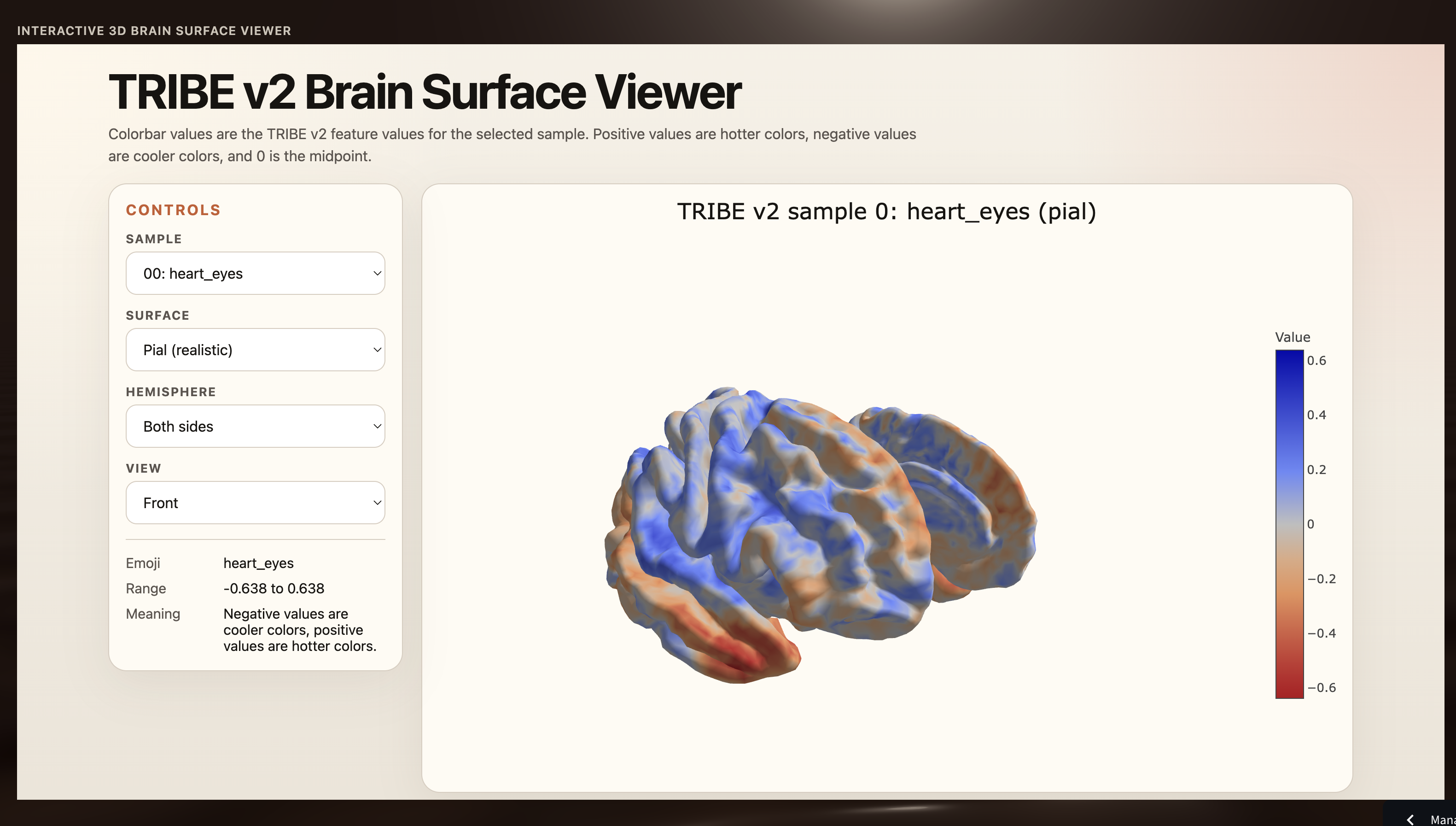
sentiments mapped on predictive brain activity
Inspiration
Emojis have become a universal language in digital communication, but there's a gap between what we type and what we express. We wanted to explore whether a machine could learn to "read" the emotional tone of a tweet and predict the right emoji and more importantly, understand where that prediction breaks down. This has real implications for predictive text, accessibility tools, and social media sentiment analysis.
What it does
Tweeti is an NLP pipeline that takes raw tweet text and predicts the most appropriate emoji from 20 classes. It cleans and vectorizes tweets using both TF-IDF and sentence embeddings, compares five classification models, and performs in-depth error analysis to reveal which emojis are "linguistic twins" pairs that share so much emotional context that even humans use them interchangeably. An interactive Streamlit dashboard lets users explore the data, model performance, and emoji confusion patterns visually.
How we built it
We started with raw tweet and emoji label files from StrataScratch. After cleaning (lowercasing, removing URLs, mentions, and special characters) and deduplicating, we engineered two feature representations: a combined word + character n-gram TF-IDF matrix and dense sentence embeddings via all-MiniLM-L6-v2. We balanced training data using median-class resampling while keeping the test set naturally distributed for honest evaluation. We trained Naive Bayes, Logistic Regression, Linear SVM, and XGBoost, then built a Streamlit dashboard to make the results explorable and interactive.
Challenges we ran into
Our biggest challenge was discovering that duplicate tweets were leaking across train and test splits, artificially inflating accuracy. Removing duplicates gave us more honest metrics but also revealed a harder truth: some emojis share nearly identical linguistic contexts, placing a fundamental ceiling on text-only prediction. We also had to carefully handle class imbalance naive training caused the model to over-predict majority emojis like ❤️ and 😢 while ignoring rarer ones.
Accomplishments that we're proud of
We're proud of the depth of our error analysis. Rather than stopping at an accuracy number, we zeroed the confusion matrix diagonal to extract the most confused emoji pairs and pulled actual misclassified tweet examples. This told a richer story than metrics alone. We're also proud of building and deploying a full interactive dashboard within the datathon timeframe, and of catching the duplicate issue mid-project and having the integrity to fix it rather than report inflated numbers.
What we learned
We learned that preprocessing decisions (like duplicate handling) can dramatically distort results if you're not careful. We also discovered that emoji prediction is inherently ambiguous the same tweet can legitimately pair with multiple emojis, which means "errors" sometimes reflect human inconsistency, not model failure. On the technical side, we learned that character-level n-grams capture informal spelling patterns (like "soooo" and "hahaha") that word-level features miss entirely.
What's next for tweeti
Fine-tuning a transformer model like BERTweet end-to-end instead of using frozen embeddings. Incorporating conversational context the tweets before and after as additional signal. Exploring emoji clustering, collapsing semantically similar emojis into sentiment groups before classification. And expanding the dashboard with a live prediction feature where users can type any text and see which emoji the model picks and why.
Built With
- html
- logisticregression
- matplotlib
- naivebayes
- numpy
- pandas
- python
- scikit-learn
- seaborn
- streamlit
- svm
- tf-idf
- vectorizer
- xgboost







Log in or sign up for Devpost to join the conversation.