-
-
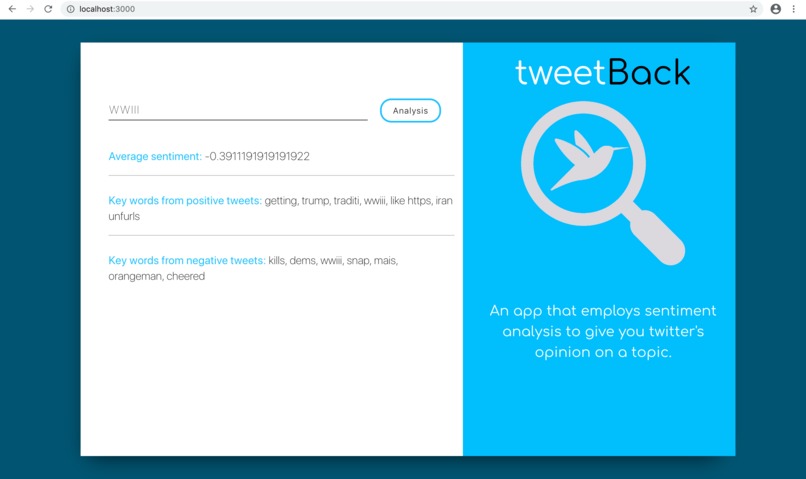
orangeman
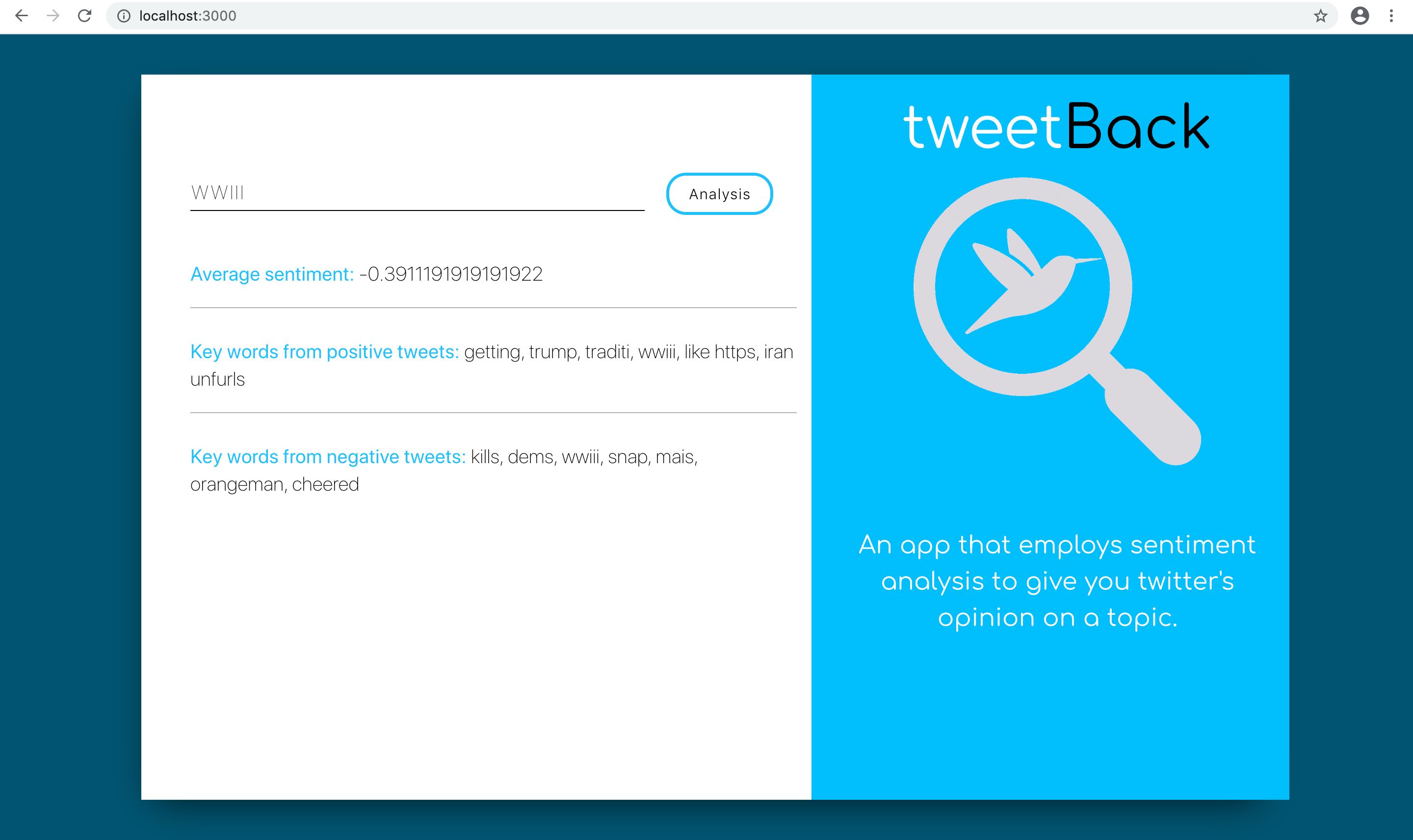
Inspiration
With over 500 milllion tweets being sent every day. Each and every tweet is an opinion, description or experience waiting to be harnessed. However, often times, critical feedback is overshadowed by clickbait. We decided to utilize such opinions to form a real time, sentiment analysis web app called “tweetBack”
What it does
tweetBack collates the top 100 tweets from a searched “Keyword” and performs a sentiment analysis on each one of them. The end result being an average sentiment analysis ranging from -1 (really bad) to 1 (really good), along with top keywords from each top positive and negative tweet.
How we built it
Back-end First, we used twitter's API to search for popular tweets related to a particular topic. Then, we performed a sentiment analysis of the tweets related to that topic using NLTK, and calculated an overall sentiment score. Lastly, we used the Gensim library to find and output the relevant keywords from the tweets.
Front-end We used React.js, along with HTML and CSS to create the website. We also used Flask to integrate the python backend with the React frontend.
Challenges we ran into
The first major challenge was doing the frontend/backend stuff. None of us have really had any experience with web development, so we had to learn a lot on the spot and get a lot of help from mentors. Another challenge was with the keywords -- the first library we used to extract keywords proved mostly useless, and once we found the second library, it refused to download on some of our members' computers.
Accomplishments that we're proud of
First, learning how to use an API--this was new to all of us. Second of all, designing a beautiful UI -- we've made apps with UIs before, but little effort was put into the presentation. This app, however, looks SLEEK! Some of us have never used HTML or CSS -- by the end of this project we've become basically experts.
What we learned
Most of the things we learned were covered in the above section. In addition, we gained some insight into how natural language processing models, namely sentiment analysis, work.
What's next for tweetBack
We would like to extend tweetBack's features to more platforms, such as reddit, Google reviews, and other social media apps. As well, we would like to improve the sentiment analysis to be more accurate and consider the context of the tweet better, which could be accomplished by training it with our data set. Another goal is to improve the keyword extraction method for tweets, as some extracted keywords are currently redundant and not insightful. A possible solution would be to use multiple keyword extraction APIs, and then combining the results and only keeping the recurring words. Also, our program does not handle empty queries well, we plan on improving that as well. Also, our program does not filter tweets from other languages, and attempts to perform English sentiment analysis on tweets of all languages (although most tweets are in English).


Log in or sign up for Devpost to join the conversation.