-
-
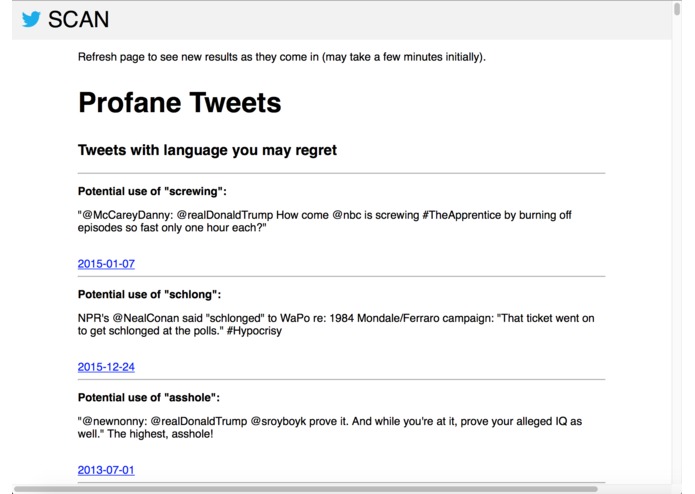
Some insightful finds
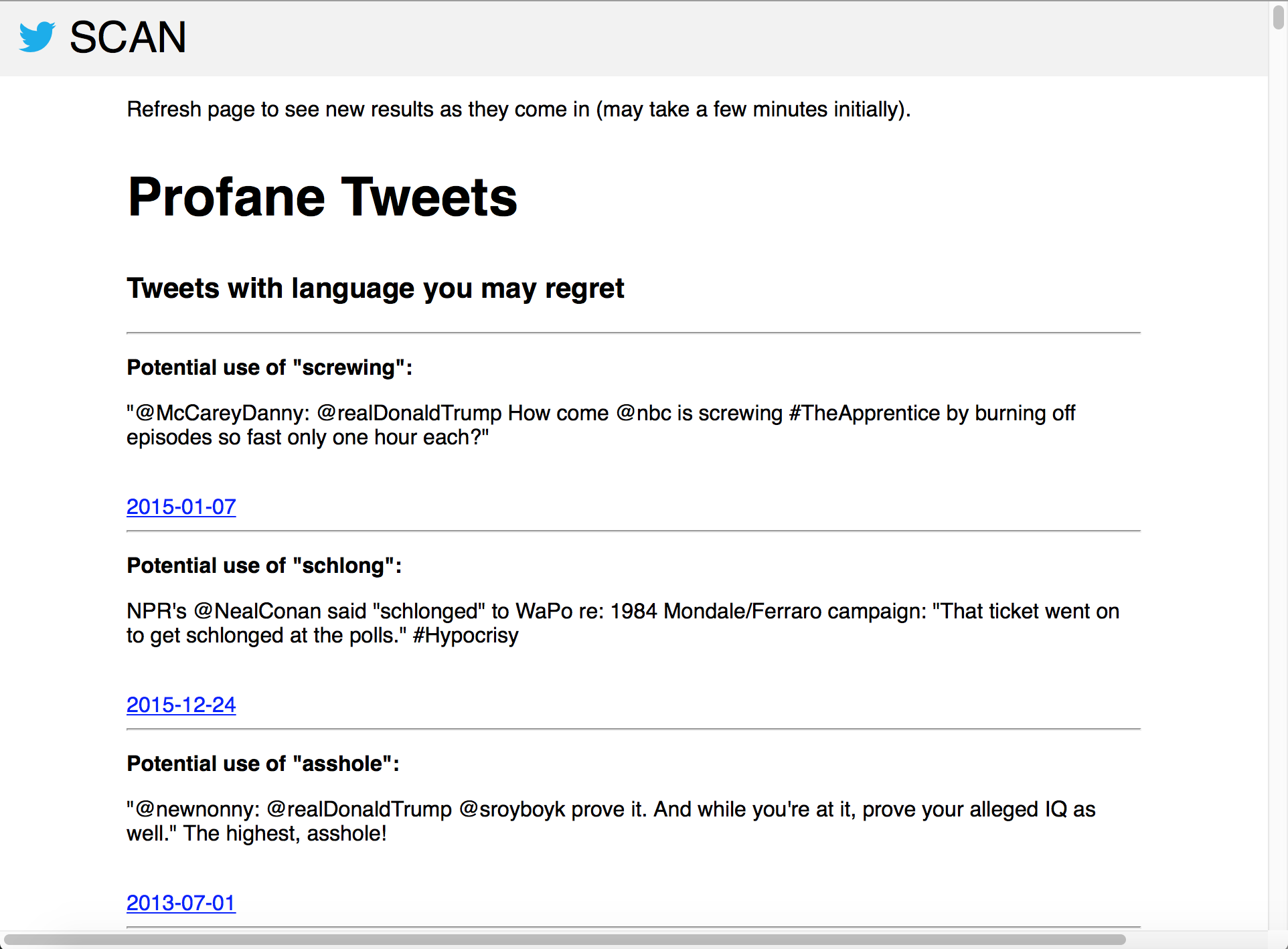
Inspiration
We've all heard stories: the employee fired, or not hired because of something on their Twitter account. Twitter doesn't make it easy to find and delete these red-flag tweets. We do.
What it does
- Gathers ALL of your tweets (We've done over 30,000 on one account, well above the normal 3200 of most services)
- Scans them for profanity, negativity (using AFINN sentiment analysis), and controversy
- Flags tweets you should review.
- Searches the IBM cloud for insights into tone ## How I built it I started off by writing two scripts, one for scraping the tweets and storing them in firebase, and the other for retrieving them and analyzing them. Once I got them working seperately, I combined them into one express.js-based API, and eventually a web-app for fetching and presenting the data.
Challenges I ran into
Half the battle was figuring out how to scrape this volume of tweets. Using a tiny hole in Twitter's strict scraping policies, I developed a process for individually retrieving the tweets of every day of an account's life. It's tedious, but that's what it takes to get past Twitter's limitations.
The next biggest challenge was presenting data quickly. Many accounts have tens of thousands of tweets, which translates to megabytes of data per account, and with Twitter's rate-limiting, fetching those was a slow process. Through iteration, I worked out a process for delivering actionable data within about a minute for almost every account, which was a 10x improvement on my original prototype.
The third challenge was seperating signal and noise. In attempting to identify profanity, I encountered a problemt that I soon learned is referred to as the "Scunthorpe problem". In searching out offensive strings, it's hard to seperate them from unfortunate matches in common, inoffensive language (i.e Saturday, bass, tycoon). Sorting through this was the most interesting challenge I encountered, because there are a lot of very interesting workarounds to solve this probelm.
Accomplishments that I'm proud of
- Producing a functional and valuable web-app within 36 hours (I even discovered some tweets of my own that were worth deleting)
- Increasing the speed by 10x from version 1.
- A great domain name (tweetscan.org) ## What I learned
- How AFINN-based sentiment analysis works
- How to more efficiently deal with large-scale scraping
- Sort algorithms
- Filtering profanity (and the inherent challenges in doing so)
- Self-hosting a web-app (I had always used heroku or Azure previously) ## What's next for Tweet Scan
- More accurate filtering
- Trends and graphs (Particularly in sentiment, reading-level, and language)
- Image flagging (using the Google Cloud Vision API)



Log in or sign up for Devpost to join the conversation.