-
-
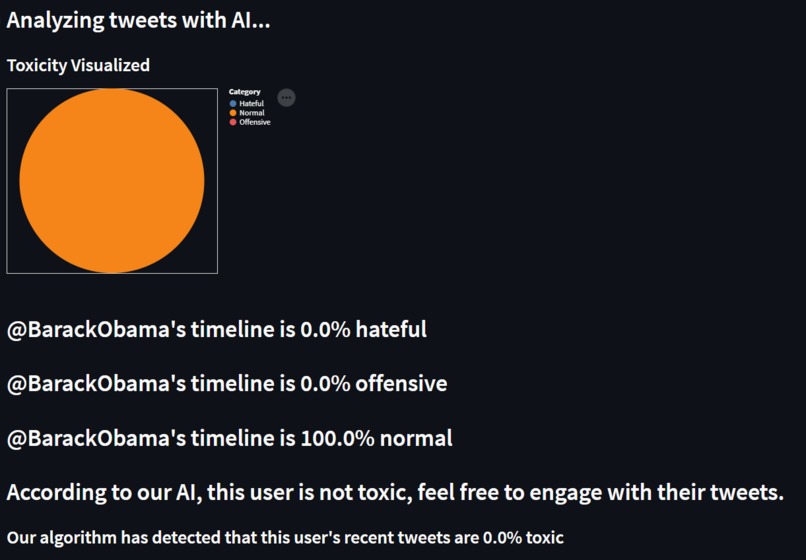
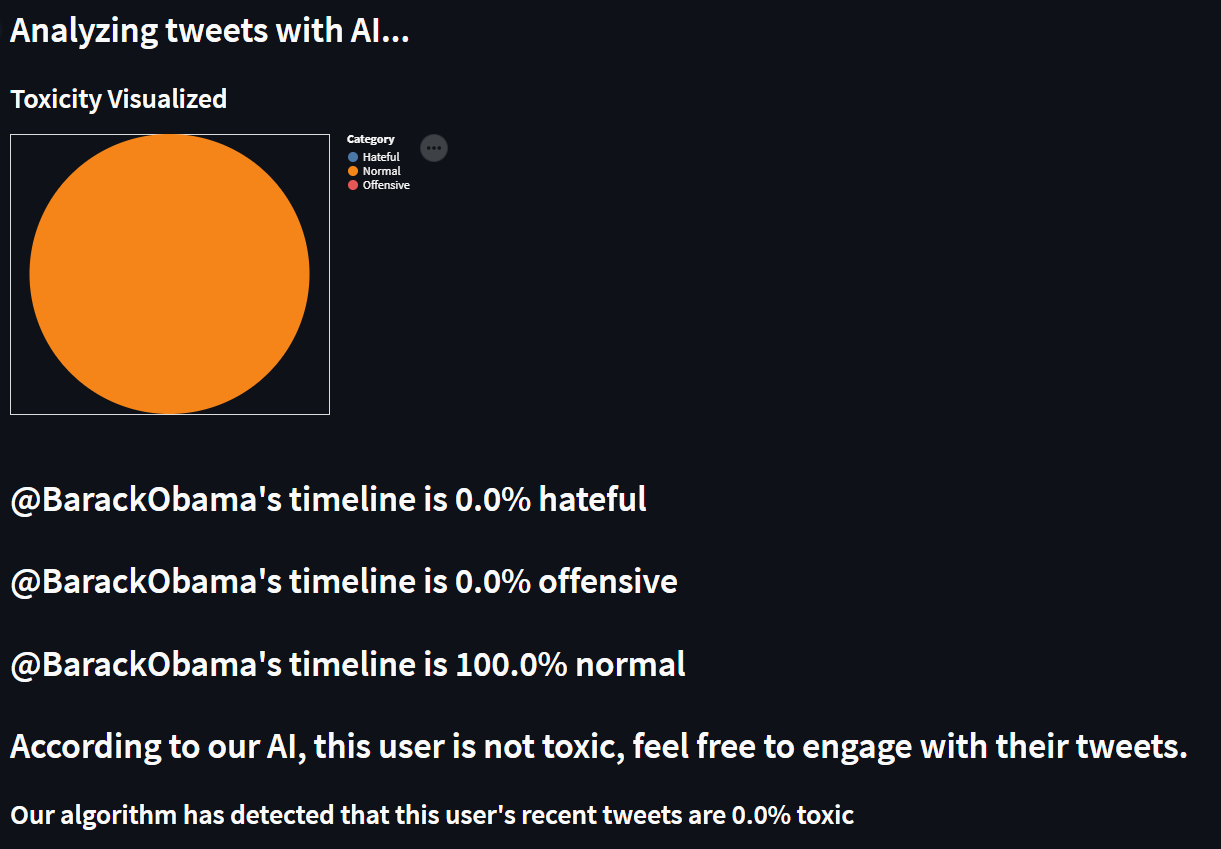
Barack Obama timeline results
-
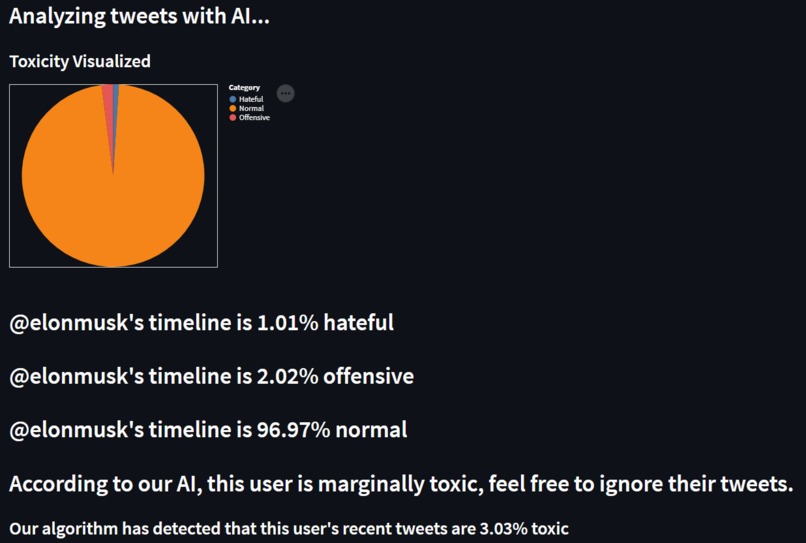
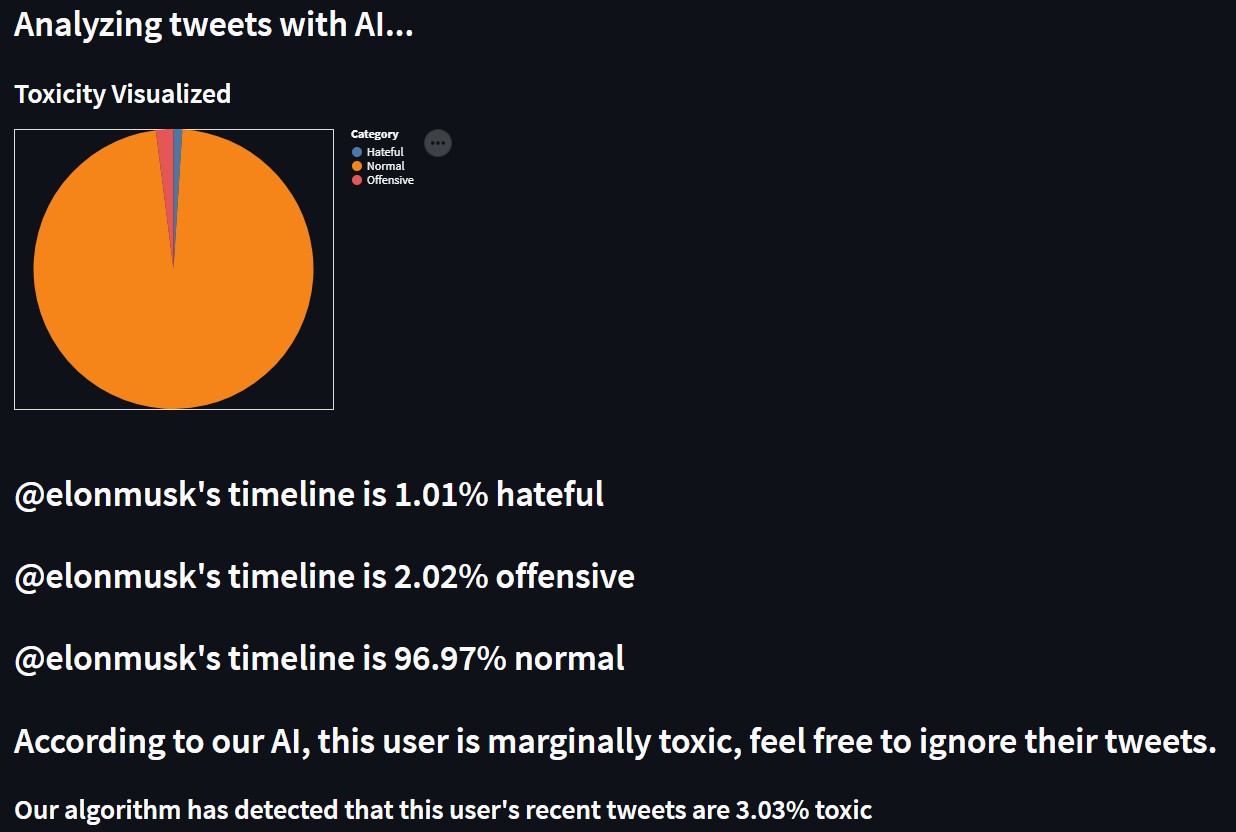
Elon Musk timeline results
-

Our logo

Inspiration
NYU Professor Jonathan Haidt's research exposed the potentially toxic effects that social media has on mental health, especially for teens, being correlated with depression and anxiety.
Our goal is to minimize the effects of toxic language on Twitter users, especially those prone to higher levels of social media usage, by classifying users’ tweets as offensive, hateful, or normal.
What it does
This website is able to read through the recent Twitter timeline of any user with a public profile and classifies the type of language used by that person.
It classifies each tweet into three categories: hate speech, offensive, and normal.
This tool will be able to warn people of any offensive or hateful users so that Twitter can be a safe and welcoming space for all, especially for those who are targeted by these accounts.
How we built it
We used the Streamlit Python module in order to build our website, taking input from the user and outputting the stats.
Next, we used the Twitter API in order to get the timeline information of a desired user.
Afterward, we combined two Kaggle datasets with the Python Pandas module.
The labeled tweet datasets can be found here: Link 1 Link 2
Then, we trained a custom Co:here NLP model on the combined dataset and called it with the Co:here API.
Finally, we analyzed the data and output visualizations with the Pandas, Altair, and Streamlit Python Modules.
Challenges we ran into
A major problem of our original ML pipeline was that the first dataset we found was extremely unbalanced, having many more offensive tweets than normal tweets, with a 17-77-6 split between normal, offensive, and hateful tweets.
We trained a custom Co:here classification model on this data and the recall was approximately 80% while the precision was only at 67%.
Essentially, this means that the model will generally choose offensive more than it should, making our false positive rate higher than it should be.
In order to compensate for this, we took another Kaggle dataset, which had many normal tweets and less toxic tweets, and combined the data together such that our new dataset was balanced between toxic and normal, with a 45-47-8 split between normal, offensive, and hateful.
Note: We did not need to worry about repeated tweets between the two datasets because Co:here automatically removes duplicate examples.
By making this change and retraining our custom Co:here classification model, we were able to boost our accuracy from 80 to 93%. Furthermore, the difference in accuracy between our model and Co:here’s default NLP classifier is an impressive 85%.
In addition, Twitter API only allowed requests on a user if their numerical ID was known, which our website’s user would not know. So, we created an algorithm to use a Twitter user’s tag to get their numerical ID.
For the responses, we also needed to learn about the possible exception cases and manage them accordingly so that an error would not be displayed on our website if, for example, the username field was left empty or the user was not found.
Accomplishments that we're proud of
We created a service which allows users to not engage in toxic discourse on Twitter, thus protecting their mental health and making the platform a safe space for users.
We achieved an increase in the accuracy of our custom Co:here NLP model from 80 to 93% by expanding our dataset.
We deployed a webapp utilizing two different APIs by only using Python.
We learned how to use the Streamlit and Altair modules and the Co:here and Twitter APIs for the first time.
What we learned
We can build different parts of the pipeline simultaneously, with one person working on Twitter while the other works on Co:here. Using the APIs also compelled us to learn environment variables and how to preserve private API keys.
Furthermore, we confirmed the data science principle that modifying data is often more feasible and effective than tuning hyperparameters for increasing accuracy.
What's next for Tweet Safely
Currently, we are using a fully-trained model that will not change over time. However, as inspired by Tesla’s self-driving data engine, we could attempt to feed information classified by our model back into itself, like how Tesla’s AI is constantly retrained on new data on the road as described by ML expert Andrej Karpathy.
In addition, we could add a feature which detects fake news, scams, or spam; users would have better peace of mind if they knew the validity of claims made by other users.
Another feature that could be added is the analysis of images attached to posts. For example, users should be notified if posts include images which depict graphic content.





Log in or sign up for Devpost to join the conversation.