

Inspiration
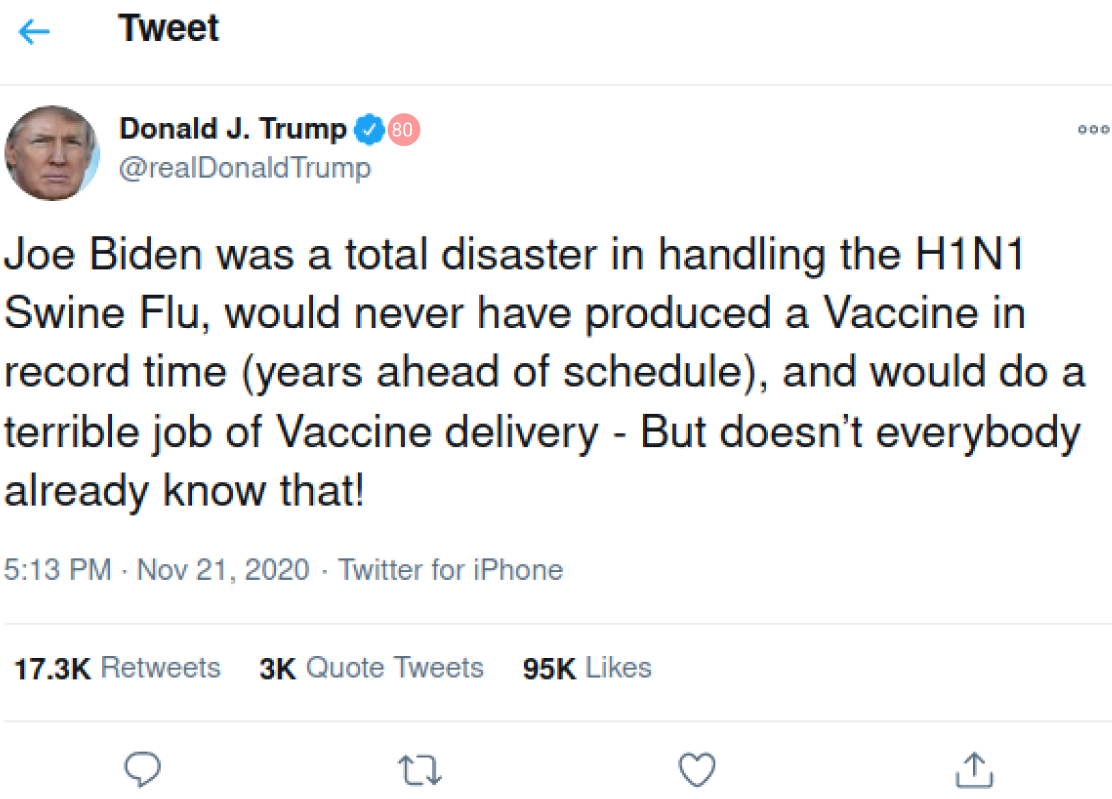
Twitter, social media, and interactions are cool. But misinformation, distrust, and lack of transparency are not cool. We believe Twitter is a powerful platform that can change the world for the better through instant exchange of information, however, nowadays it doesn't seem like it always serves a purpose it was created for. We see governments, politicized groups, and other people interfering with democracy and free speech, while spreading "fake news" and misinformation everywhere. This is why we created this project. We hope this prototype will give a good start to the idea of bias detection and healthier social media interactions between people.
What it does
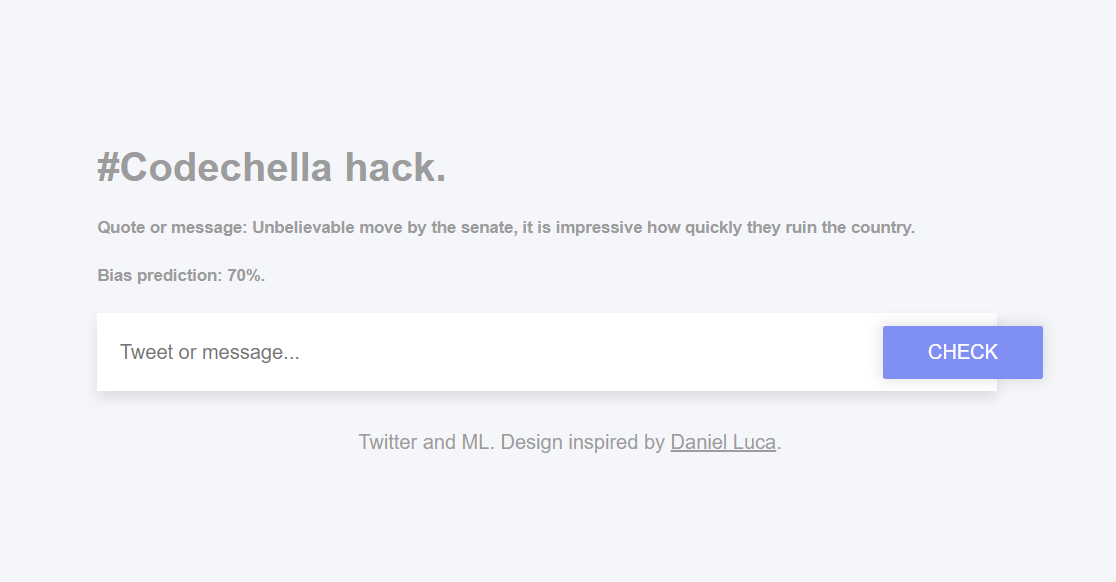
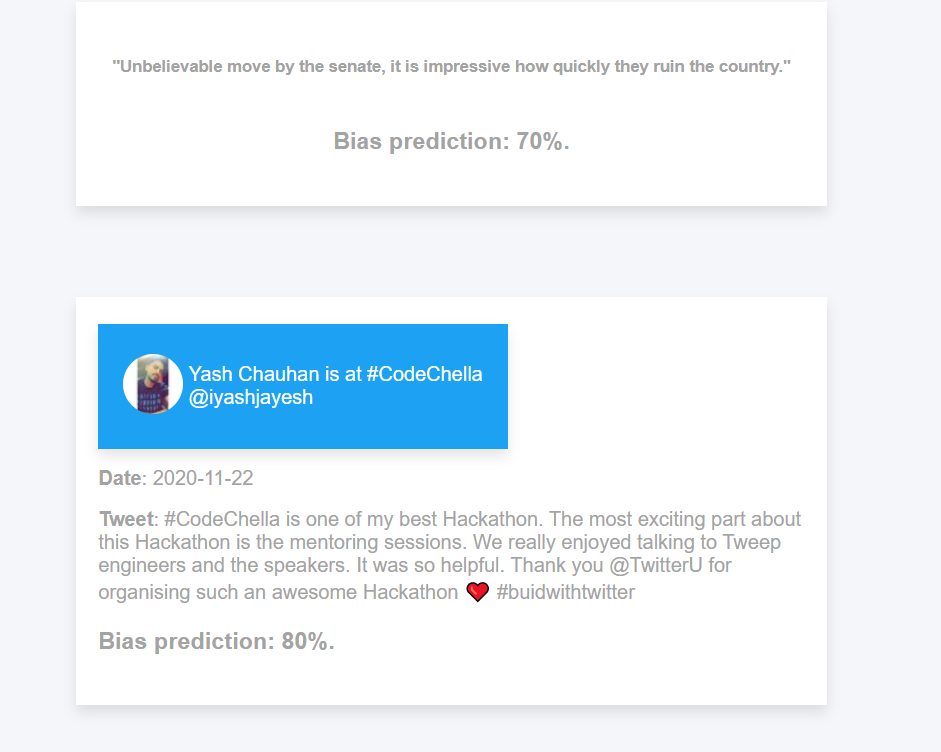
This project uses machine learning in TensorFlow, Python programming language, and Twitter API. It is a tool used to detect bias in tweets and tweet-like messages by analyzing their word structures and assigning them a percentage from 0% to 100%, where 0% is not biased at all and 100% is extremely biased. We hope that this prototype will show some potential in application of this topic and will interest someone like Twitter in incorporating our idea into their products.
How I built it
We built it in three stages: data collection, model training, and showcasing our results. Each of those stages were equally important and we worked hard to finish them in such a small amount of time and given resources.
Data collection
We collected our data using Twitter API in Python. We set up our config.py with authentication keys and other important to us data, created a tweet_bias_detection_utils.py that collects the tweets from specific Twitter account defined earlier, and filters our quality tweets that exceed a certain character limit. In our case, we chose the number of characters to be 49. The main logic of data collection is shown in the code snippet below from tweet_bias_detection_utils.py:
def func(...):
"""..."""
api = get_tweepy_api(get_tweepy_config())
accounts = get_accounts_of_interest()
biases_col, tweets_col = list(), list()
for account, bias in accounts.items():
acc_count = 0
tweets = api.user_timeline(screen_name=account, count=300,
include_rts=False)
for tweet in tweets:
clean_tweet_text = re.sub(r'https?:\/\/.*[\r\n]*', '', tweet.text,
flags=re.MULTILINE)
if len(clean_tweet_text) > len_tweets and acc_count < num_tweets:
sub_bias = bias - 10
biases_col.append(sub_bias)
tweets_col.append(clean_tweet_text)
# ...
return data
Model training
There was a lot of research that came into model training and choosing the best model that could be used. We realize that our selection was the best for the purpose of this hackathon given the time and resource constraints. Still, our choice of a simple 1D convolutional neural network might not be suitable in case we want our feature to go into production. That being said, our architecture worked phenomenally well given small data and a tiny laptop to run breakthrough ideas on. Here is the architecture of our model:
def func(...):
"""..."""
int_sequences_input = keras.Input(shape=(None,), dtype="int64")
embedded_sequences = embedding_layer(int_sequences_input)
x = layers.Conv1D(128, 4, activation="relu")(embedded_sequences)
x = layers.MaxPooling1D(4)(x)
x = layers.Conv1D(128, 4, activation="relu")(x)
x = layers.MaxPooling1D(4)(x)
x = layers.Conv1D(128, 4, activation="relu")(x)
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dense(128, activation="relu")(x)
x = layers.Dropout(0.5)(x)
preds = layers.Dense(10, activation="softmax")(x)
model = keras.Model(int_sequences_input, preds)
# ...
return model
With that model above, we achieved a phenomenal 80% accuracy on our training data set. Which proved to us that this is a viable approach. We also tested it using our own example phrases, and we felt like the responses from the model were fairly reasonable.
Showcasing our results
We chose to showcase our results through a website. Therefore, we purchased a server instance on Digital Cloud service that allows us to host the application using different settings. We also bought a domain name for our hack: https://codechella-tweet-bias.tech. We used Python to serve dynamic content with beautiful animation and interfaces. A mix of HTML and CSS was used to show what our model is capable of.
Challenges I ran into
The main challenge we ran into was hosting. We didn't allocate enough time for hosting our application. Since it wasn't static, we couldn't just use GitHub pages to kick start our deployment. Digital Ocean cloud instance and a fresh domain name were required to be able to produce a somewhat impressive project. However, after spending 2 hours before the deadline, we realized that it is not feasible, and therefore we couldn't finish deploying it. Although, we are aware of what caused the issue and what held us back for so long trying to deploy it: we ran all commands as root, which did not allow us to finish setting up routing at the end. Next time that happens, we definitely know what to do and how to accomplish whatever we want.
Accomplishments that I'm proud of
- Get together with a teammate to work on a project.
- Working machine learning model that predicts values we want.
- Research-based project that (feels like) solves a problem.
- Lots of Python code to my public repository.
What I learned
- Using word embeddings in machine learning.
- Hosting in the cloud and the pain of DNS lookup (it could take days).
- Using pandas library better.
- Centering HTML and how painful it still is.
What's next for Tweet Bias Detector
- Include badges on influential Twitter accounts (see images).
- Improve our website for people to use.
- Incorporate new models and more data.
- (Maybe) publish a paper on this topic.
- Spread a word about this project!


Log in or sign up for Devpost to join the conversation.