-
-
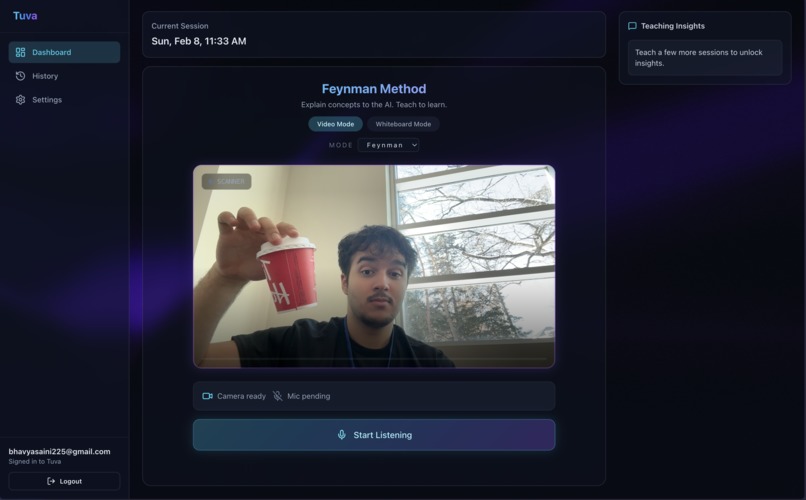
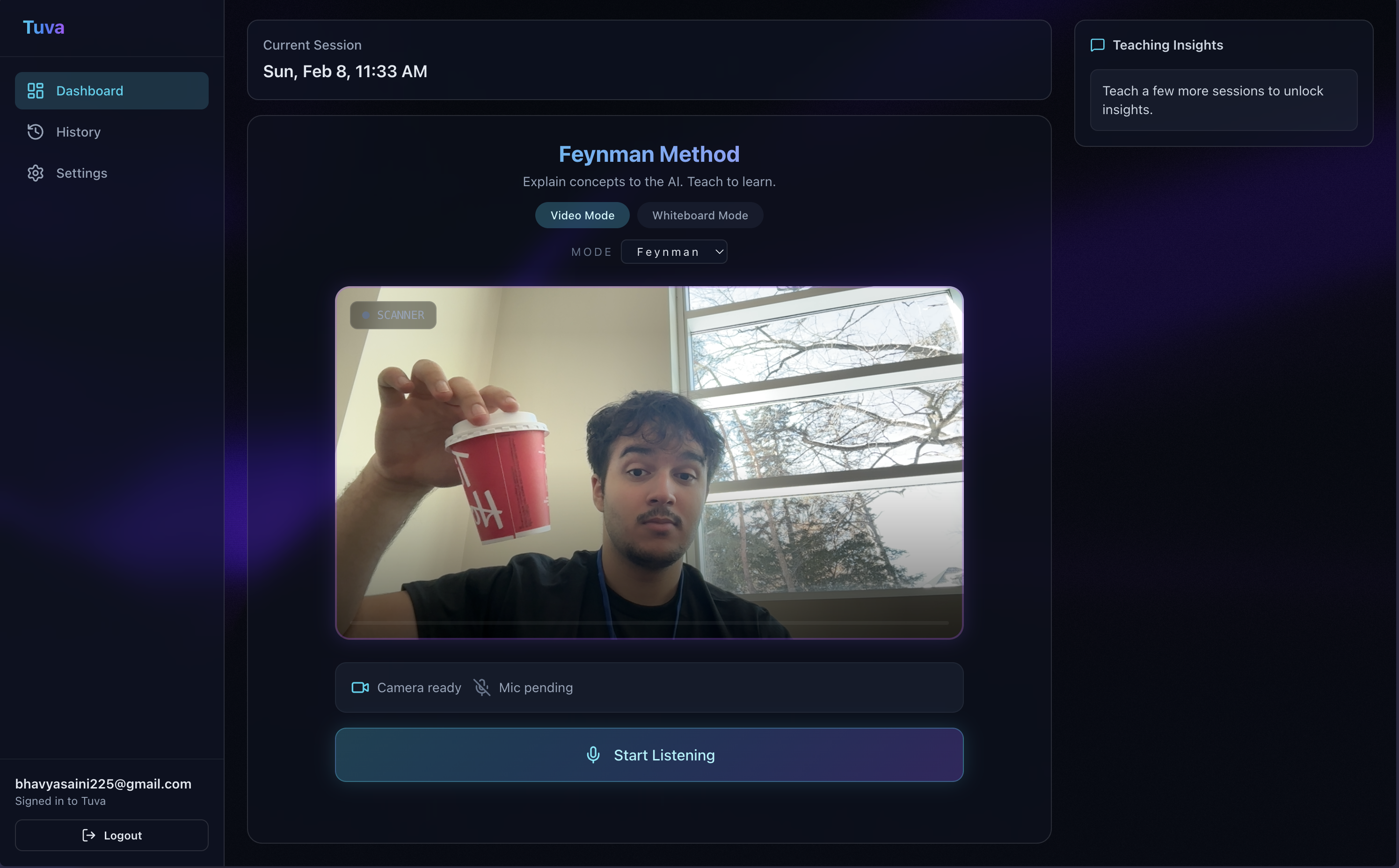
Video Demonstration
-
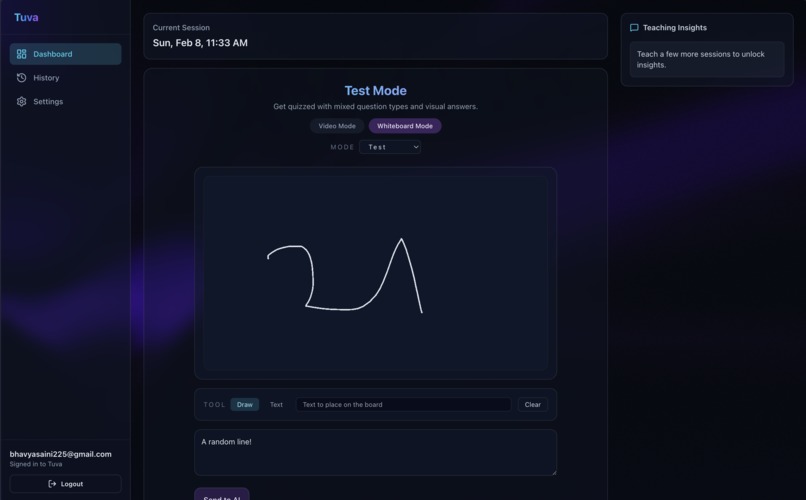
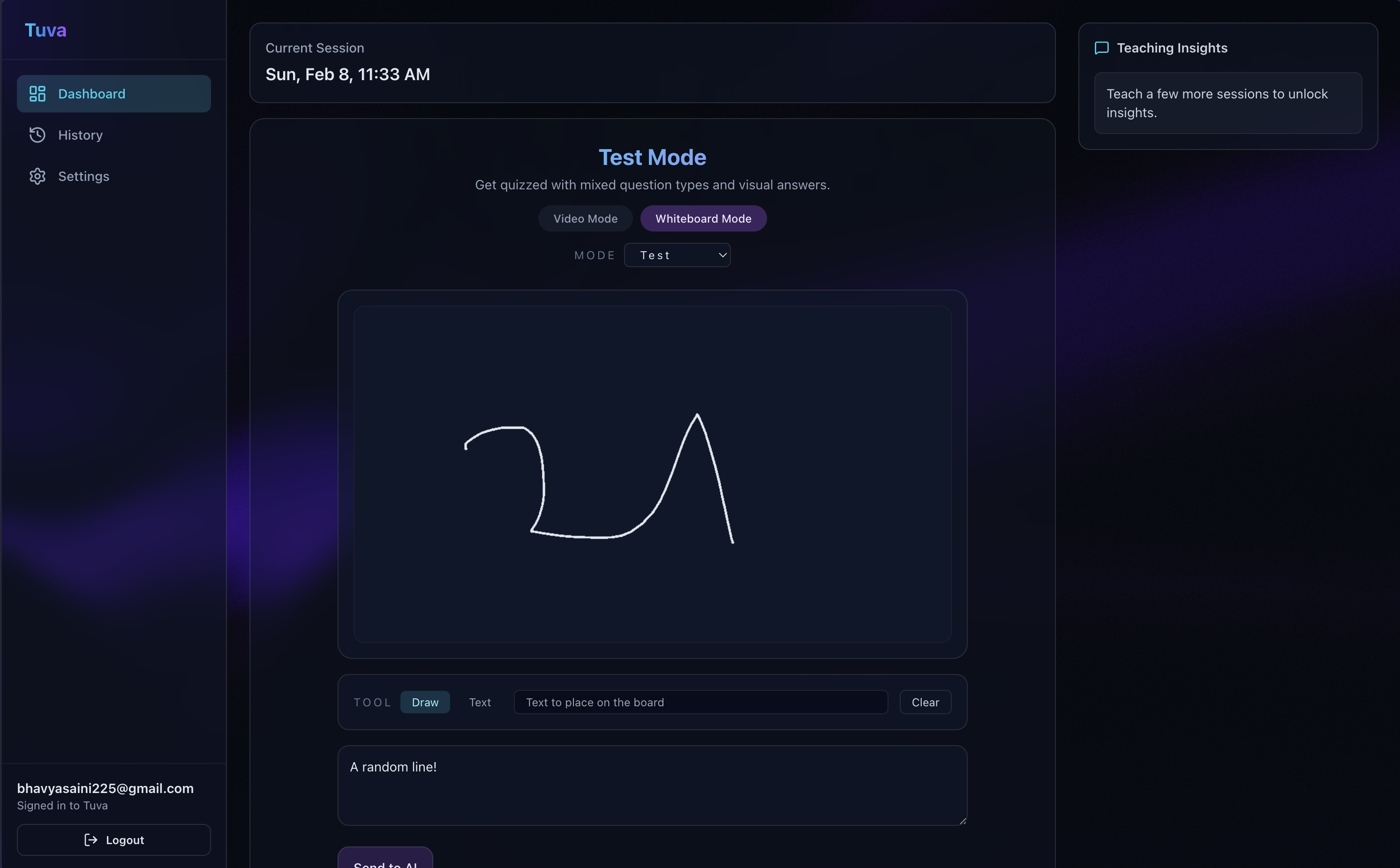
Whiteboard Demonstration
-
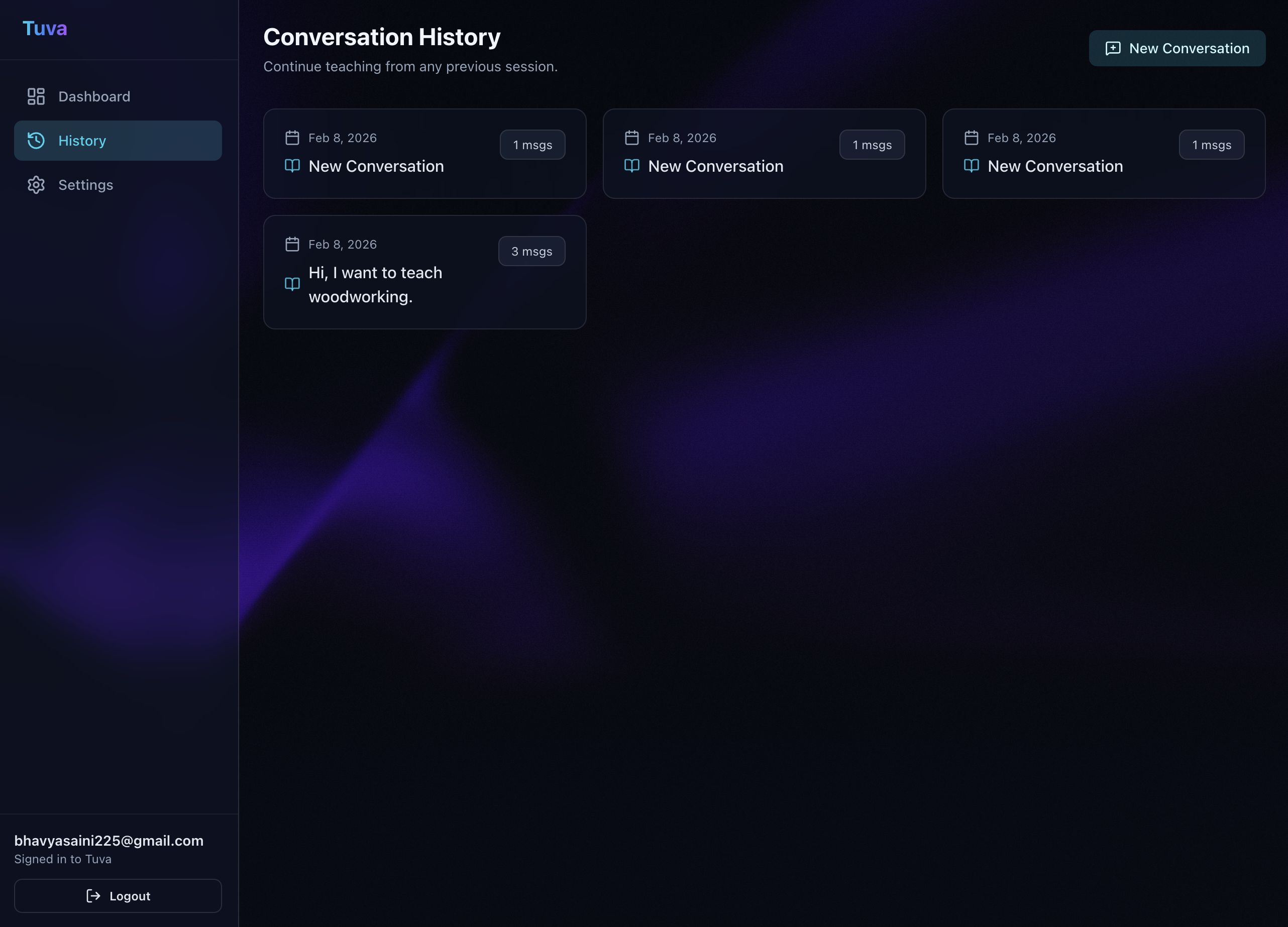
Chat History Webpage
-
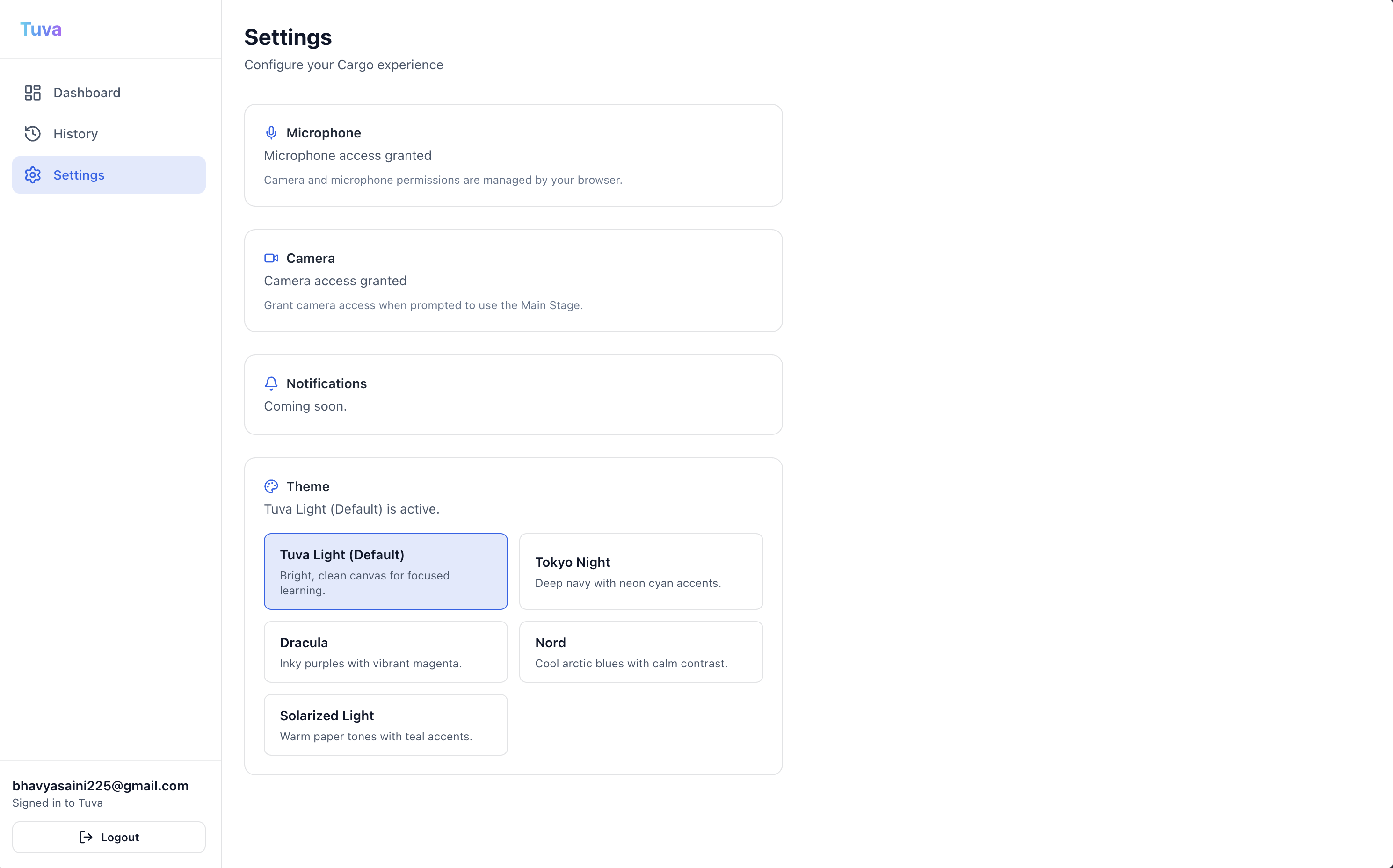
Settings Webpage (Light Theme)
-
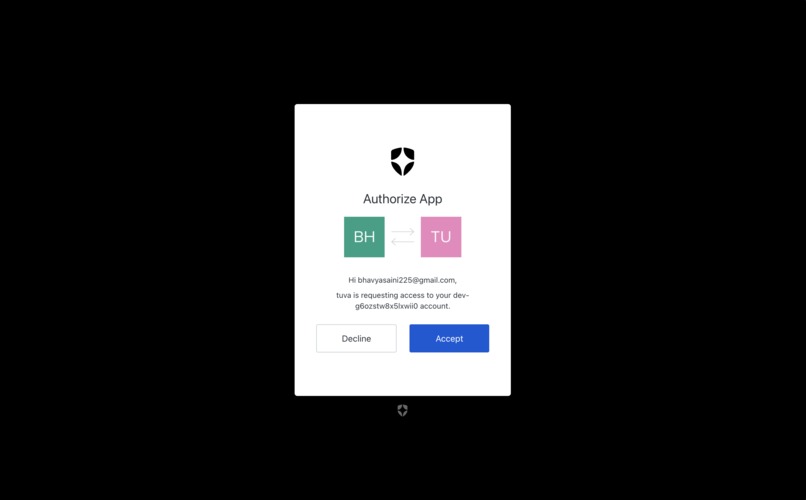
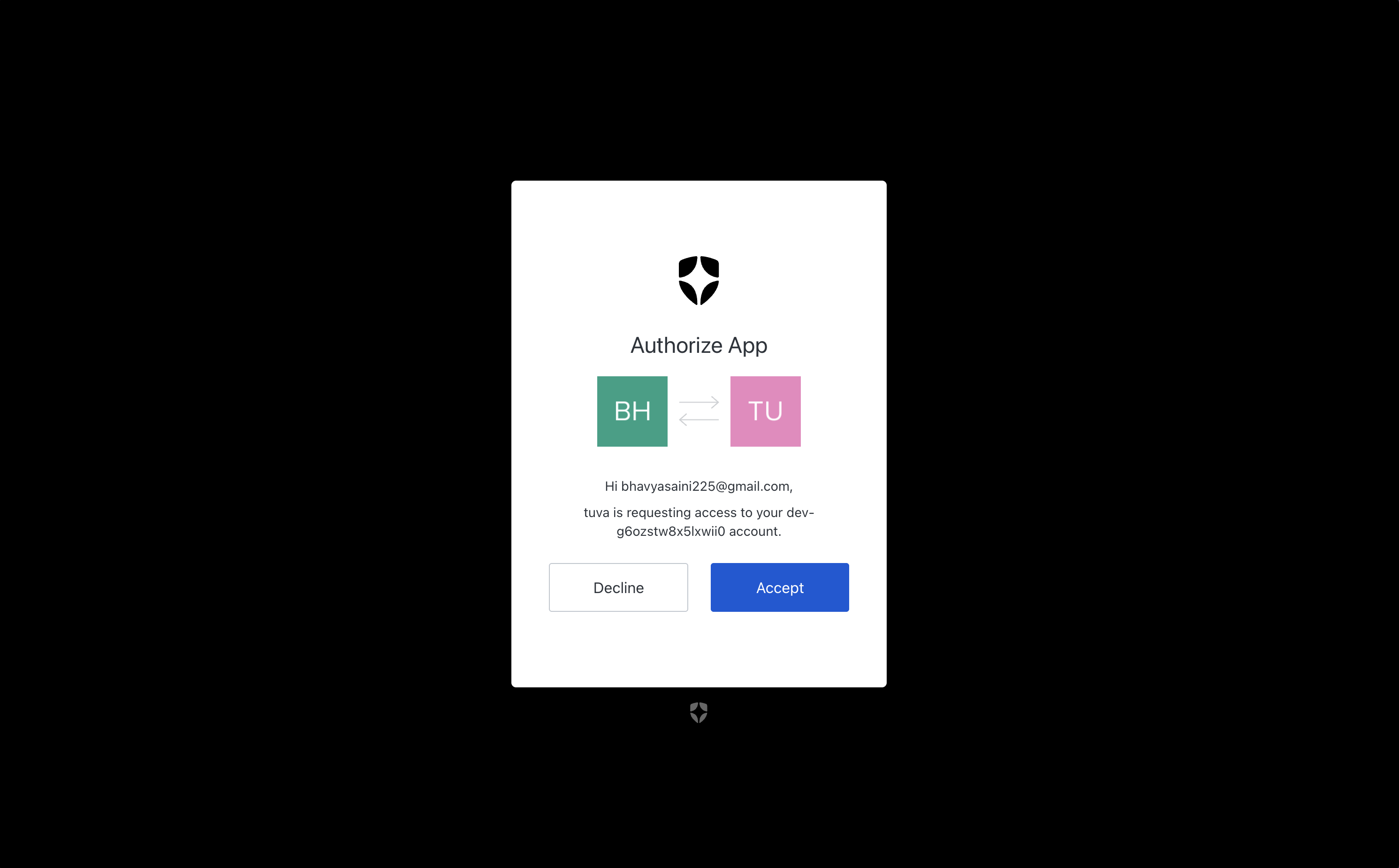
Auth0 Authentication
Tuva: The First AI That Learns From You Inspiration We built Tuva to solve the Illusion of Competence. We have all watched hours of lectures, nodded along, and felt like we understood the material, only to blank out when trying to solve a problem. As physicist Richard Feynman noted, the easiest person to fool is yourself.
We realized that most EdTech is passive. It feeds you content. We wanted to build an Active Recall Engine. We wanted an AI that forces you to lecture it. If you cannot explain a concept to Tuva simply, you do not own that knowledge yet.
What it does Tuva is a reverse-tutor. Instead of an AI teaching a student, the student teaches the AI.
Visual Perception: Tuva uses your webcam to see your whiteboard or notebook. If you draw a diagram, Tuva analyzes it in real-time.
Socratic Sabotage: Tuva plays the role of a confused student or a strict proctor. It interrupts to ask why a pointer moves a certain way or demands proof for a formula.
Multimodal Feedback: Using low-latency voice synthesis, Tuva speaks back to you, creating a realistic teaching environment.
How we built it
Tuva is a high-performance Next.js application that orchestrates open-source intelligence into a single Digital Human.
The Eyes (Vision): We utilize Gemma hosted via Featherless.ai. This allows us to leverage powerful open-weight vision capabilities without being locked into closed ecosystems. We capture webcam frames and feed them to the Featherless inference endpoint to analyze handwritten diagrams.
The Voice (Audio): We integrated ElevenLabs for ultra-low latency text-to-speech. We stream the audio buffers directly to the client to minimize delay.
The Brain (Memory): We utilized Backboard.io to give Tuva persistent thread memory.
Security (Auth): We implemented Auth0 to handle secure user authentication, ensuring that each student's learning history and conversation threads are private and persistent across sessions.
The Interface: Built with Next.js (App Router) and Tailwind CSS.
Challenges we ran into
The biggest challenge was Latency Engineering. To create a flow state conversation, the loop of Speech to Text to Vision Analysis to Inference to Voice Generation needs to happen in under 2 seconds. We optimized our prompts to be radically concise, which reduced token generation time significantly.
Integration was also a hurdle. Wiring up Auth0 user sessions to correctly sync with Backboard threads while piping visual data to Featherless required careful state management to ensure the AI always knew who it was talking to and what they were looking at.
Accomplishments that we're proud of
- Open Source Vision: Successfully implementing Gemma via Featherless for real-time visual analysis, proving that open-weight models can handle complex multimodal tasks.
- The No Yap Architecture: We successfully curbed the tendency of LLMs to lecture, resulting in a tool that listens more than it talks.
- Secure Persistence: Creating a seamless loop where a user can log in via Auth0 and immediately resume a teaching session from days ago.
What we learned
We learned that Active Recall is the only true metric of learning. We also discovered that memory is critical for trust; users treat the AI differently when it remembers their previous explanations. It shifts from a tool to a tutor.
What's next for Tuva
- Live Knowledge Graph: Visualizing the user's mental map in real-time as they explain concepts.
- Multiplayer Classrooms: Allowing a human professor to spectate a student teaching Tuva.
- Custom Personas: Toggling between a confused 5-year-old and a strict PhD thesis defender.
Built With
- auth0
- backboard
- css
- elevenlabs
- featherless
- gemma
- html
- javascript
- next.js
- typescript



Log in or sign up for Devpost to join the conversation.