Project Story
About the project
Estou construindo um agente de IA tutor, pensado para estudos. A ideia é permitir que eu suba qualquer tipo de conteúdo — artigos, papers, PDFs, anotações, datasets — e que o agente sempre fundamente as respostas com base nessas fontes. O objetivo é ter um “mentor” que não inventa, mas que referencia e explica, guiando o aprendizado com material confiável e personalizado.
O que o projeto faz
- Indexa conteúdos diversos (texto, PDFs, notas) em um banco vetorial (Qdrant).
- Executa recuperação aumentada (RAG) com ranqueamento híbrido (semântico + lexical) para buscar trechos relevantes.
- Gera respostas fundamentadas, retornando citações/trechos de origem para transparência.
- Disponibiliza uma API (FastAPI via Google ADK) e uma interface de chat (Open WebUI) para interação.
Como construí
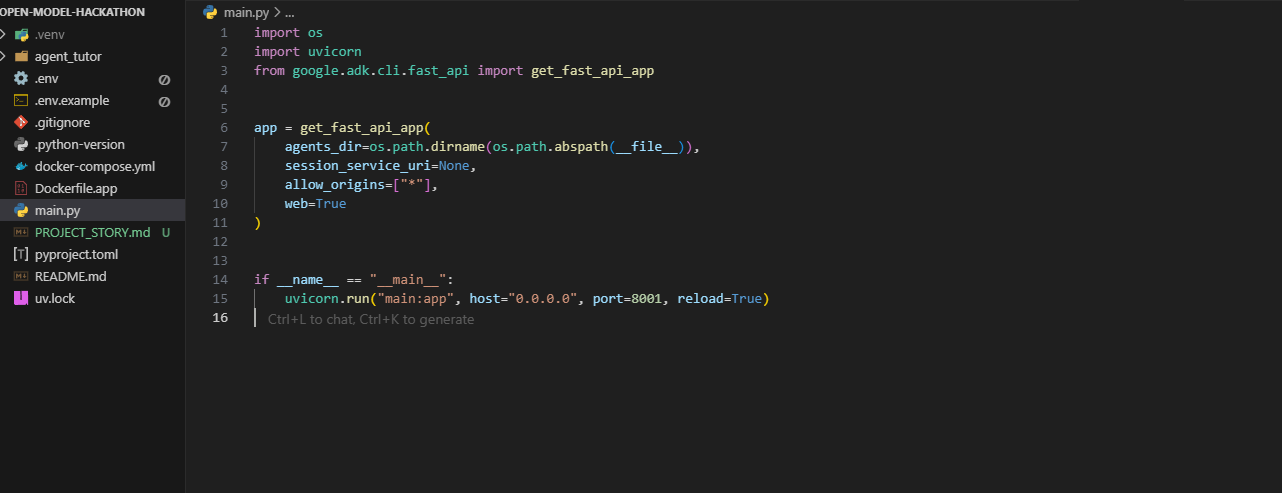
- Python 3.12 com
uvpara gerenciar dependências e execução reproduzível. - FastAPI/Google ADK:
get_fast_api_app(...)emmain.py, com servidor em0.0.0.0:8001. - Qdrant em container dedicado para armazenamento vetorial, com volume nomeado (
qdrant_data) para persistência. - Open WebUI em container dedicado para testes e experimentação via navegador.
- Orquestração via
docker-composecom três serviços (app,qdrant,openwebui), rede bridge e healthcheck no Qdrant.
Arquivos principais:
main.py: inicializa a API e define host/porta.agent_tutor/tools/qdrant_tools.py: operações de busca vetorial/híbrida.docker-compose.yml: serviços, rede e volumes (sem criar pastas indesejadas no host).Dockerfile.app: imagem da aplicação Python baseada emuv.
Desafios encontrados
- Garantir que o servidor estivesse acessível fora do container (bind em
0.0.0.0). - Controlar persistência sem poluir a raiz do projeto (uso de volume nomeado para Qdrant).
- Lidar com downloads/modelos no Open WebUI (desabilitar
hf_transferquando necessário e usarHF_TOKENpara modelos “gated”). - Ajustar o re-ranking híbrido para equilibrar compreensão semântica e termos exatos em perguntas de estudo.
O que aprendi
- Montagem de um pipeline RAG reprodutível com containers separados e comunicação por rede interna.
- Boas práticas no Qdrant (portas, volumes, healthchecks) e na exposição da API.
- Estratégias de grounding: como devolver trechos/citações relevantes melhora a confiança no tutor.
A parte de “math” da busca híbrida
Para combinar a relevância semântica (vetores densos) e a relevância lexical (vetores esparsos), uso a seguinte pontuação:
[ s_{hyb} = \alpha\, \cos(\mathbf{q}_d, \mathbf{d}_d) + (1 - \alpha)\, \cos(\mathbf{q}_s, \mathbf{d}_s) ]
Onde:
- (\mathbf{q}_d) e (\mathbf{d}_d) são vetores densos (consulta e documento),
- (\mathbf{q}_s) e (\mathbf{d}_s) são representações esparsas (pesos lexicais),
- (\alpha\in[0,1]) ajusta o peso entre semântica e léxico.
Assim, o tutor consegue equilibrar “entender o conceito” e “referenciar termos/citações exatos”, crucial para estudo.
Como rodar
- Build e subida do stack:
bash docker compose up -d --build - Endpoints úteis:
- API:
http://localhost:8001/docsehttp://localhost:8001/redoc - Qdrant:
http://localhost:6333 - Open WebUI:
http://localhost:3000
- API:
Próximos passos
- Upload amigável de PDFs/arquivos via API e extração de chunking com metadados (título, seção, páginas).
- Modo “citar sempre”: respostas com referências e links para os trechos usados.
- Métricas de estudo: registrar perguntas, fontes consultadas e progresso do usuário.
- Ajuste adaptativo de (\alpha) por tipo de pergunta (conceitual vs. factual).
Referências
- Qdrant Docker/Compose: Documentação oficial
- Open WebUI Quick Start: Documentação oficial
Built With
- google-adk
- gtp-oss
- openrouter
- openwebui
- python
- qdrant

Log in or sign up for Devpost to join the conversation.