-
-
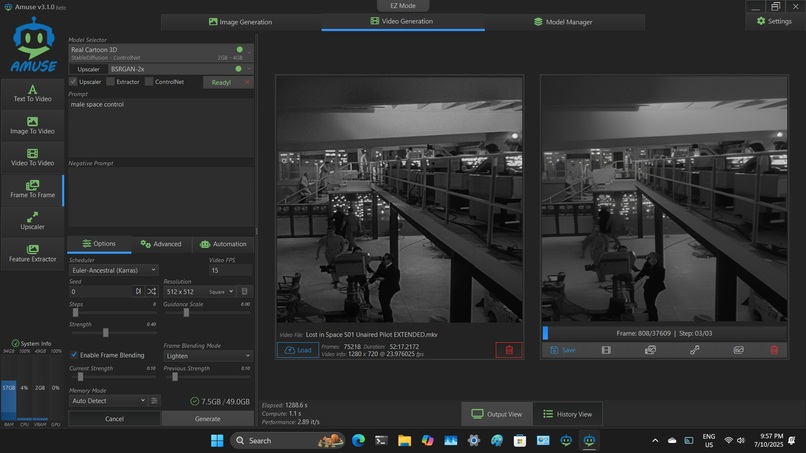
Screenshot showing 57GB RAM usage. Cartoon LCM, 2.89 it/s, includes upscaler
-
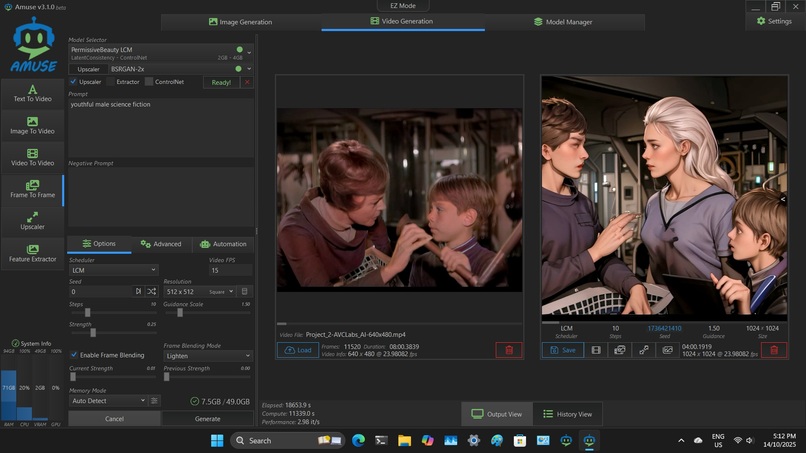
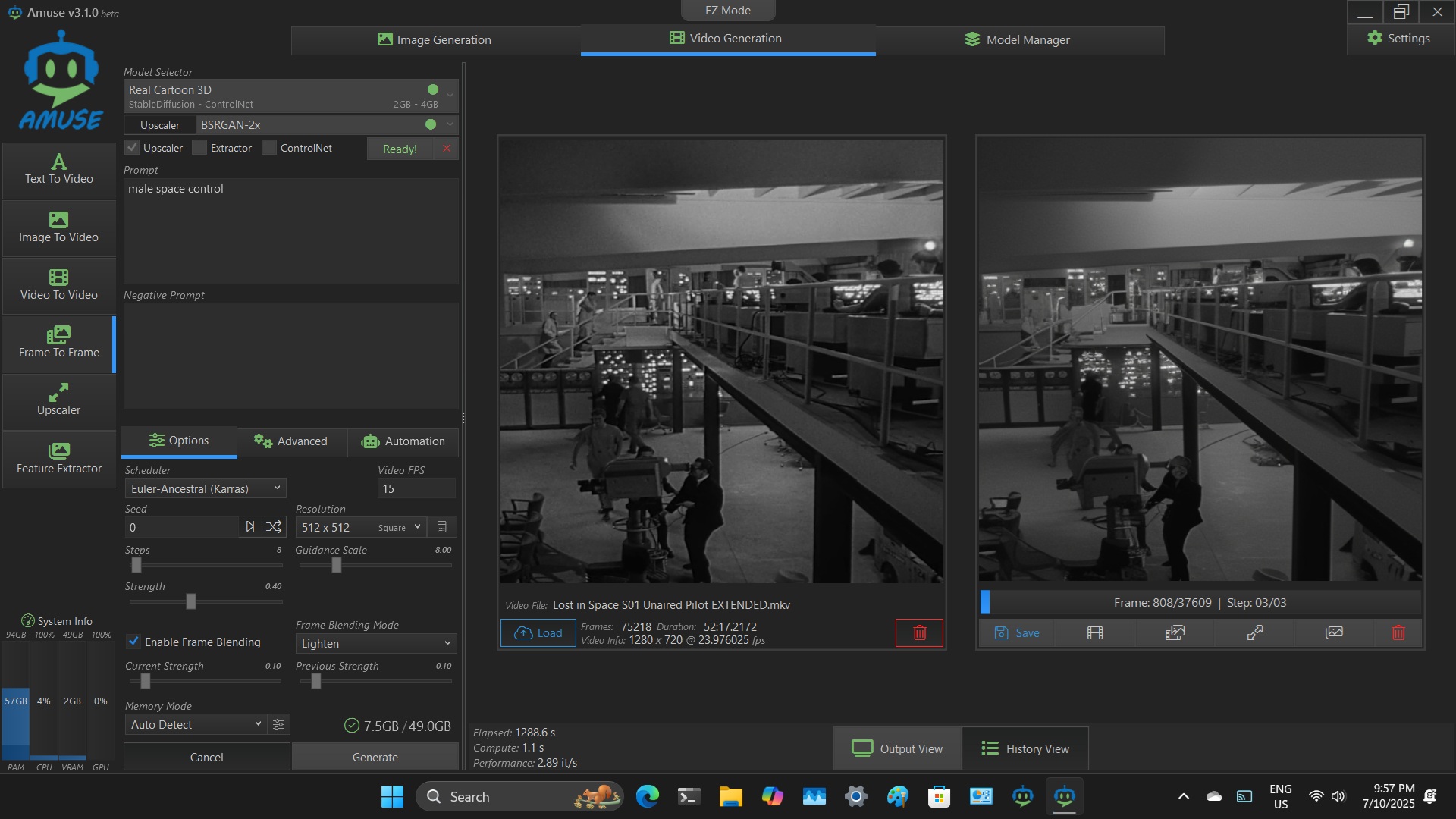
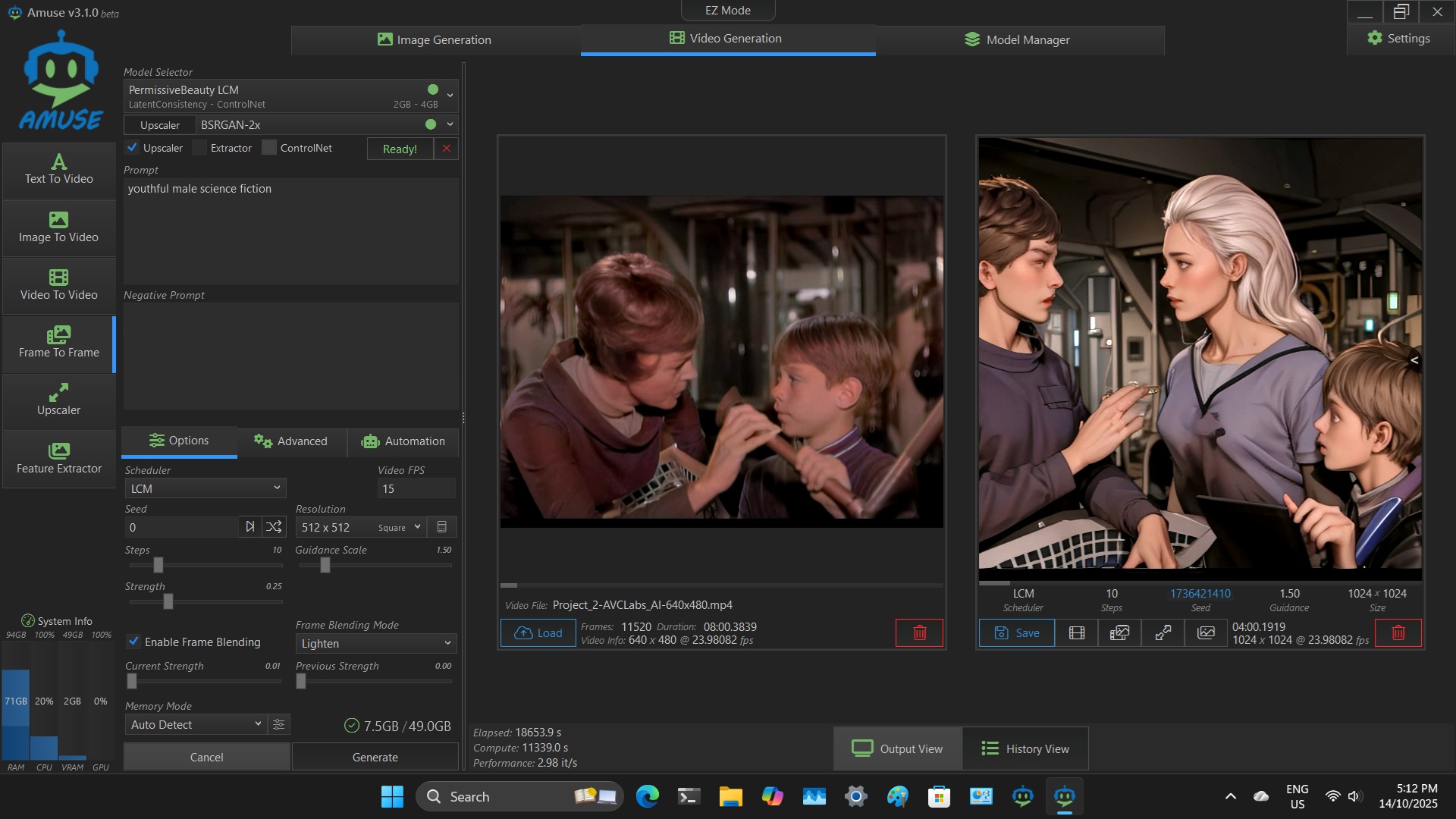
Screenshot of animation of colourised LOST IN SPACE. Permissive Beauty LCM, 2.98 it/s - no upscaler. LCM Models have different Schedulers
-
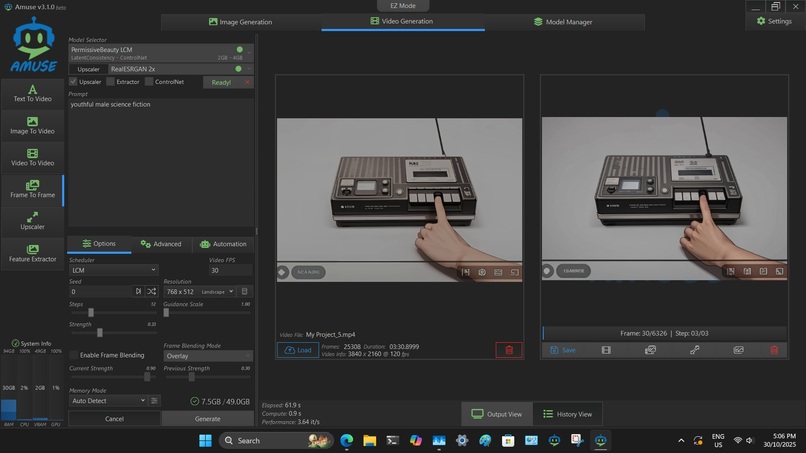
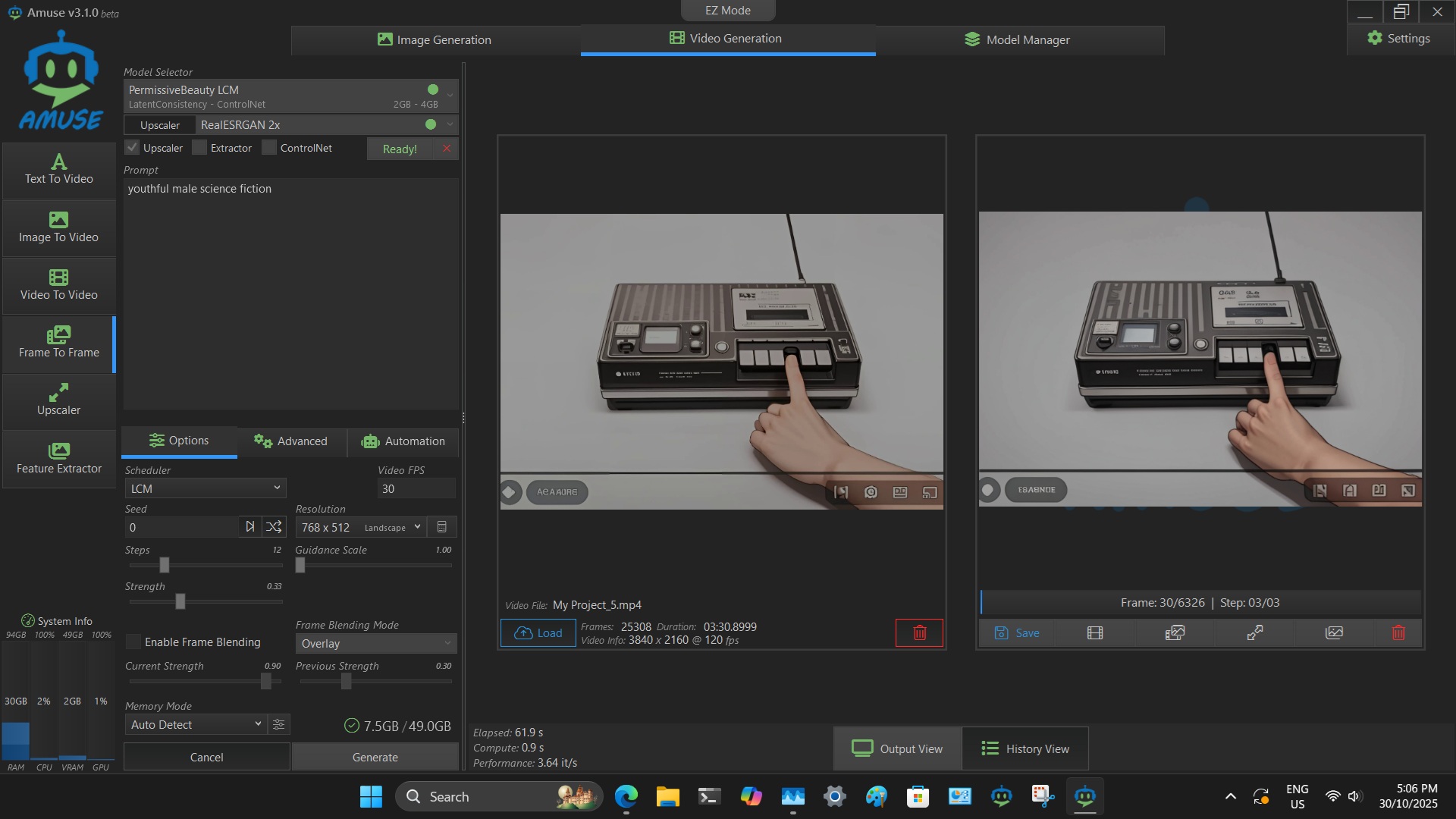
Final screenshot, Permissive Beauty LCM plus upscaler. These settings will also work on lower RAM machines at a much slower (snail) speed
-
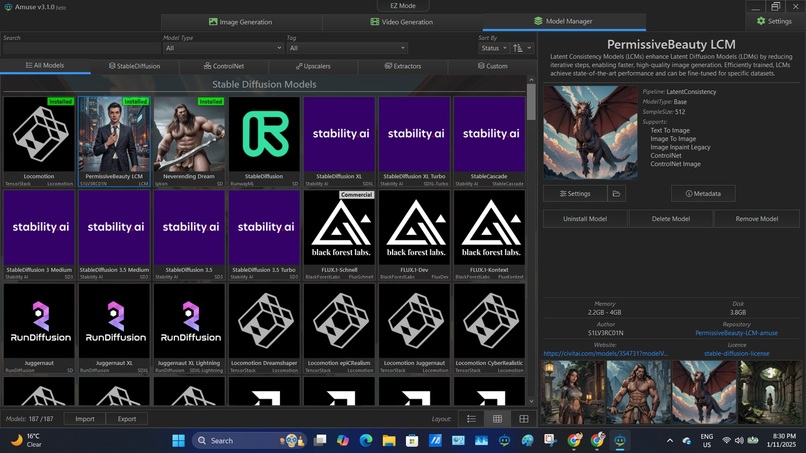
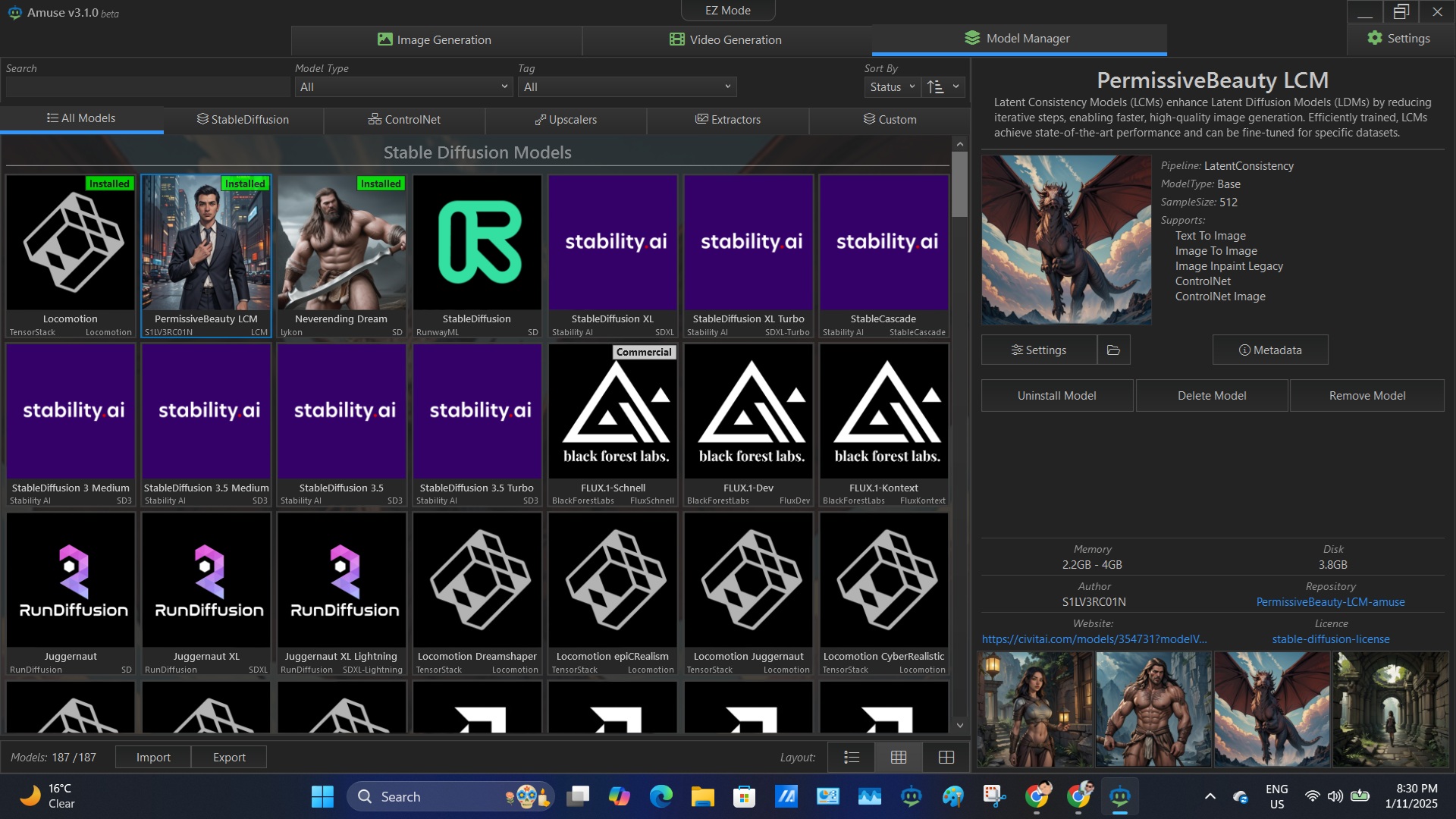
Screenshot of Library for Stable Diffusion Models
-
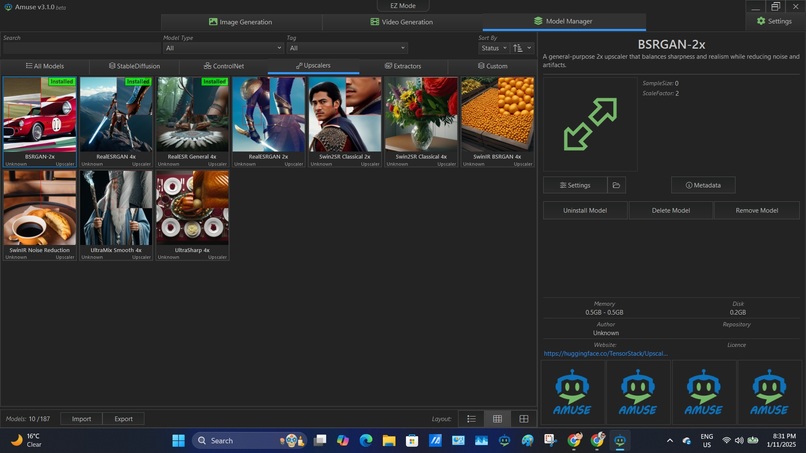
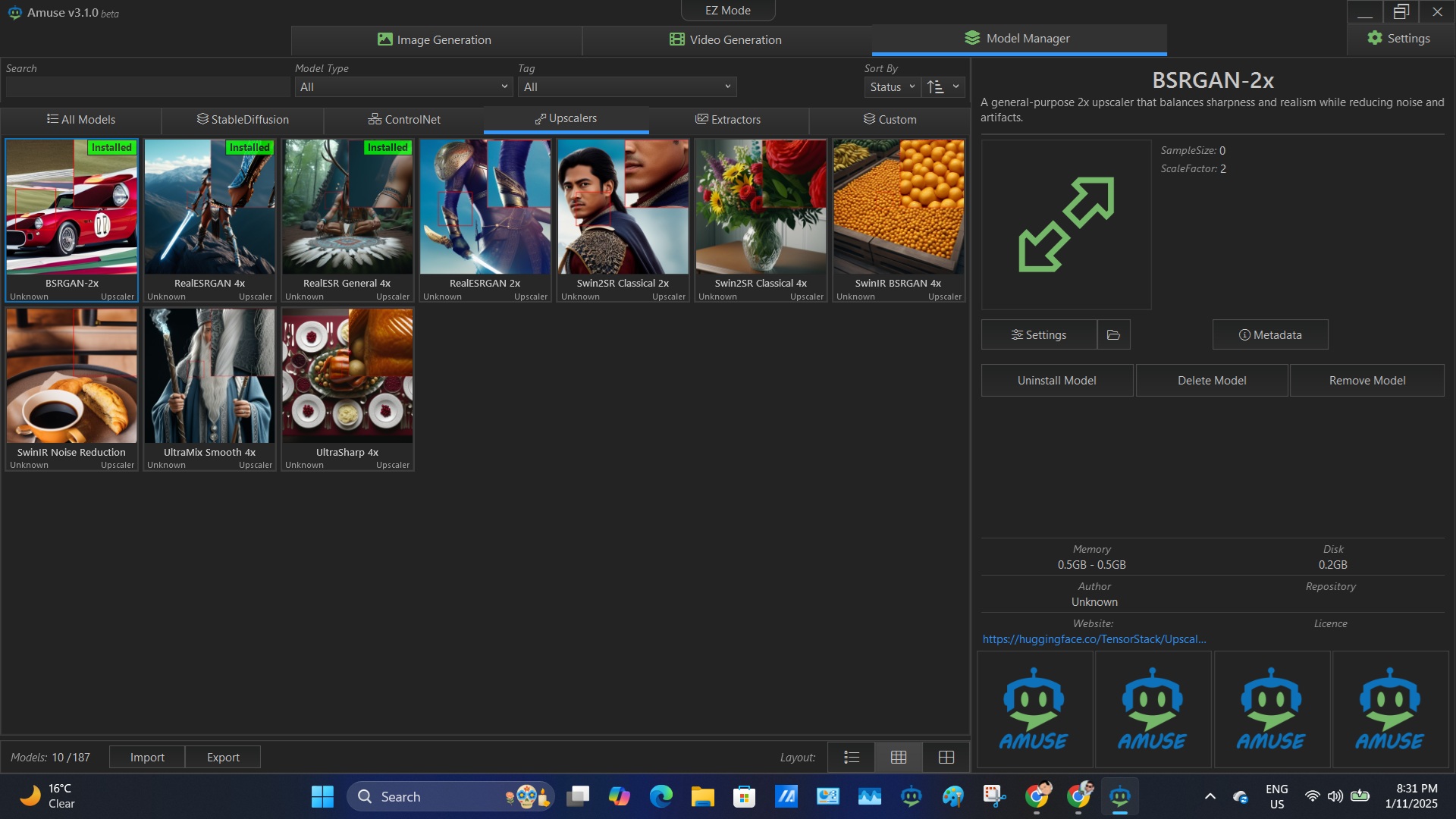
Screenshot of Library of Upscalers. Only RealESGRAN 2x works on my system & even then it is a major bottleneck
-
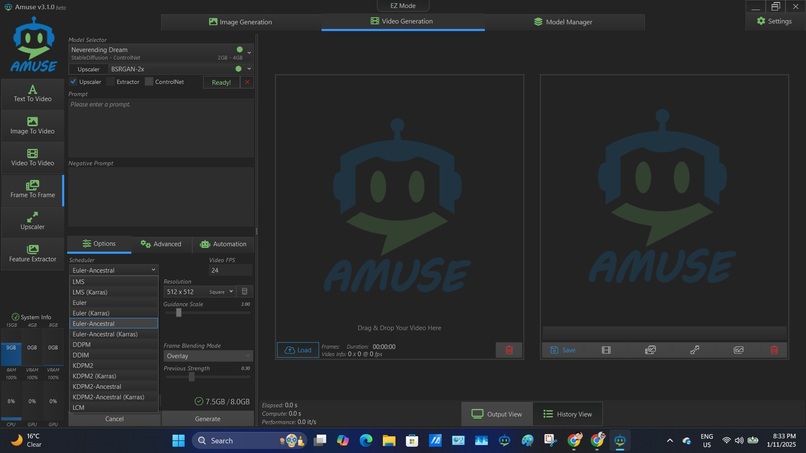
Screenshot of large number of selectable Schedulers for LCM's. Not availble for Permissive Beauty LCM
-
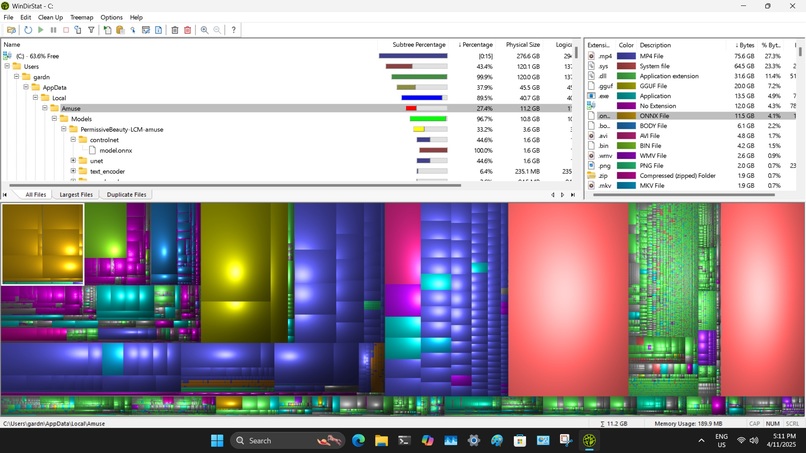
A look under the hood. The Amuse software is the bright yellow objects in the top left corner
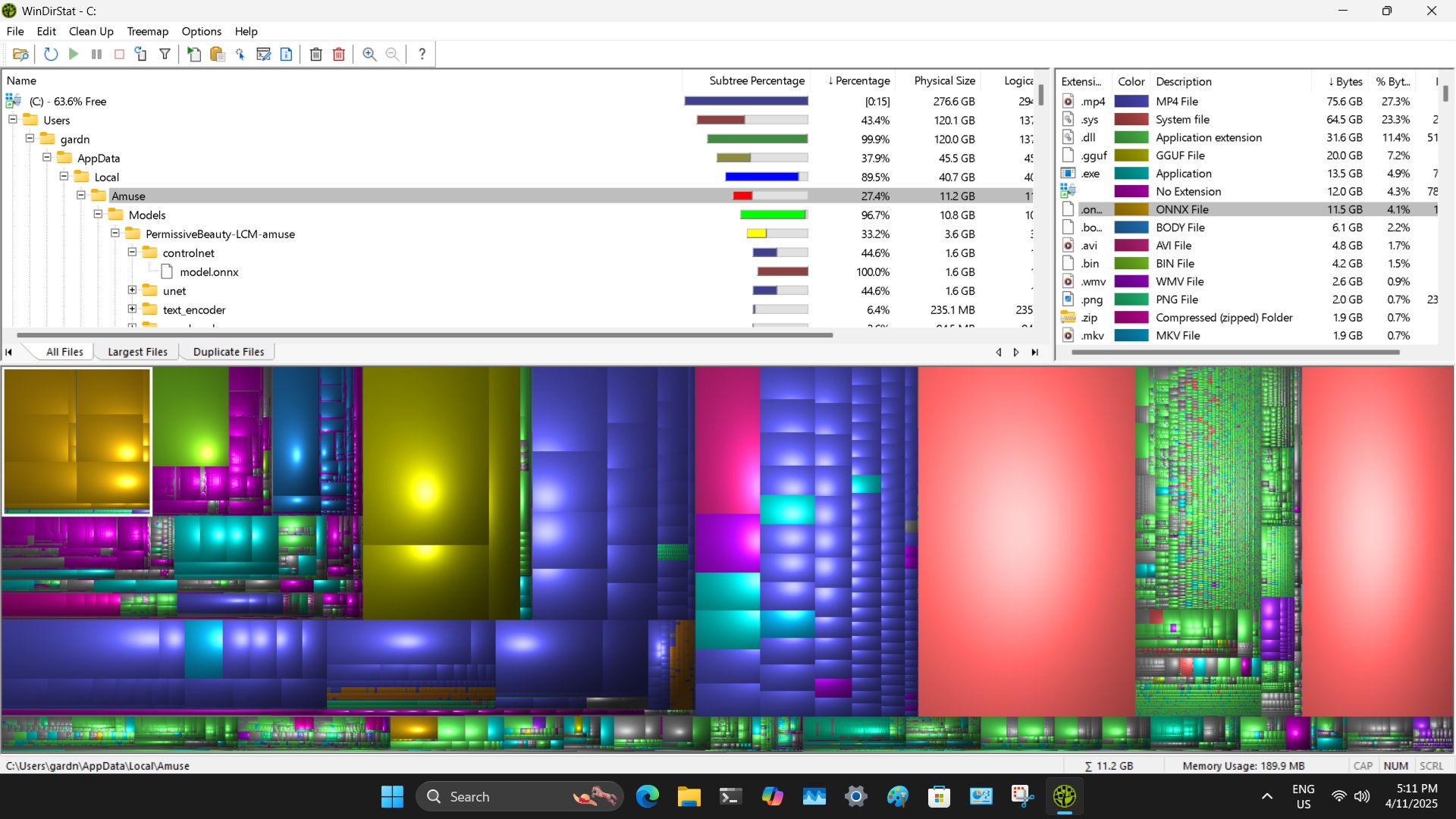
Inspiration: Began using AI. commercial video-style-transfer services in my retirement to animate short segments of old episodes of Lost in Space for fun. I researched for an affordable AI solution that I could run locally on my cheap AliExpress Mini PC purchased for under AUD$999.
What it aims to achieve: Optimized the AMD Amuse video frame-to-frame Permissive Beauty Latent Consistency Controlnet to enable output of high-quality animated video from any source for up to 10 - 15 continuous minutes.
How we configured it: Ryzen 7 (Model 255) 94GB RAM Minisforum Mini PC (Aliexpress AUD$900). One objective was to avoid the need for an expensive graphics card and utilise the low-spec integrated Radeon iGPU graphics. Also functionally fully tested on a Ryzen 9 16GB laptop (with unviable long processing times)
Major Challenges: Maintaining system stability over long processing times. Initial processing attempts produced shoddy results from extremely long processing sessions and frequent system crashes. Zoning in on the correct setting ranges for the various LCM's was initially frustrating; however, once familiarity with each LCM was gained the setting zone ranges for each model became simpler and natural.
Accomplishments: Through extensive optimization testing have increased the processing efficiency and output quality on the cheap Ryzen 7. Initial processing attempts began at unusable and unstable 0.50 to 0.80 it/s. Final optimizations have improved processing to a very impressive 5.00+ it/s. This enables a 3-5 minute upscaled video to be processed in 3-5 hours. According to Grok, this is good performance for local AI video synthesis using LCM + ControlNet. The process also surprisingly runs on a 16GB Ryzen laptop. The processing speed is 10 times slower, leading to unrealistic rendering times of beyond 5 hours on the low quality settings.
What else was learned: It is easy to include additional prompts to modify the processing further. Fun examples include changing the age, gender, or nationality of the conversion. Including prompts for "science fiction", "Astroboy", etc, enables very strange interpretations and fun outputs. This example has been left unmodified to more closely mimic the original video. The Minisforum Mini PC consumes less than 100 watts when under full load. Cost of 3-5 minutes a.i. conversion is less than a kilowatt or <AUD$0.30.
What's next for Turn any YouTube video into a full-length animated video: I am in the process of completing a full 4K colour animation of the unaired LOST IN SPACE one-hour pilot from 1965. I would then like to do a make-over of THE ROCKY HORROR PICTURE SHOW.
Further research has indicated that a simple swap-out of my Ryzen 7 for a bare-bones Ryzen 9 AI. from AliExpress for AUD$950, & by retaining my existing fast RAM & SSD will provide a cheap pathway to a vastly superior. Estimated it/s almost double my current performance limits. The more dramatic performance boost will come from accessing the R9 AI on-board neural capabilities to exploit fully the upscaling. That is a current massive bottleneck for my configuration and a drag on output quality.
This upgrade path will also provide support for future NPU software capabilities that continue to expand throughout the AI. ecosytem. The solution proves remarkable quality & cost efficiency for what it does, without a GPU and running costs of less than AUD$0.10 per hour.
Built With
- amd
- amuse
- avclabs
- clipchant
- controlnet
- pixbim
- powerdirector
- snippingtool
- upscaler


Log in or sign up for Devpost to join the conversation.