Inspiration
AI model fine-tuning has traditionally been reserved for those with deep technical expertise and expensive infrastructure. I wanted to democratize this capability, making it possible for anyone to customize open-source language models without needing to understand GPU configurations, hyperparameters, or complex training pipelines. My vision was simple: make AI customization as easy as uploading a dataset and clicking a button.
What it does
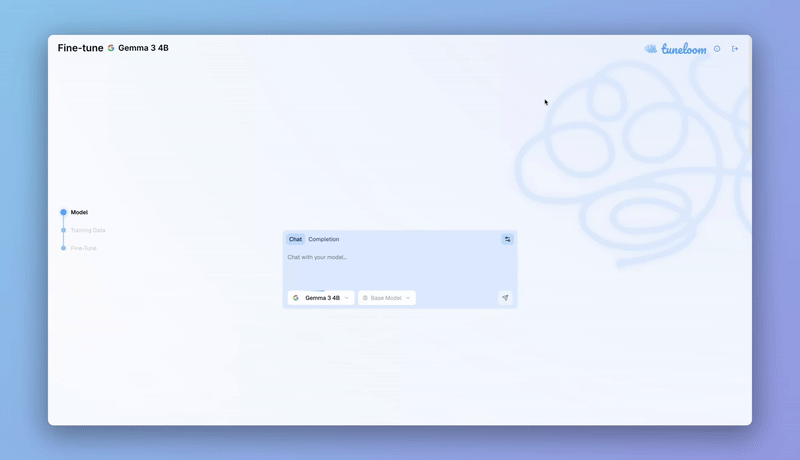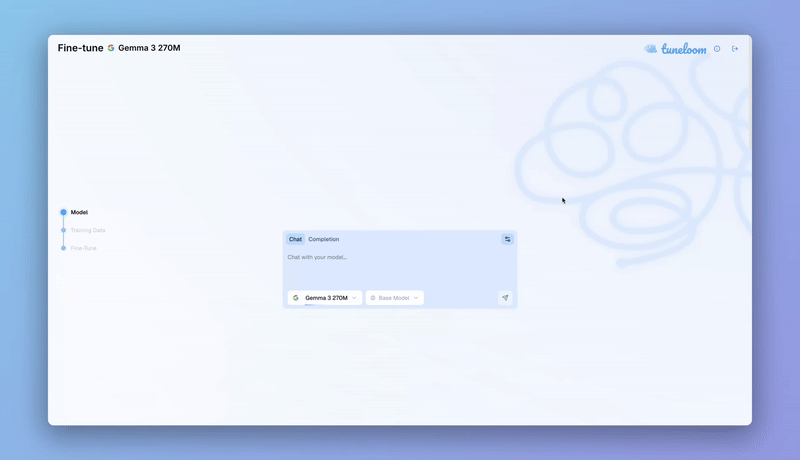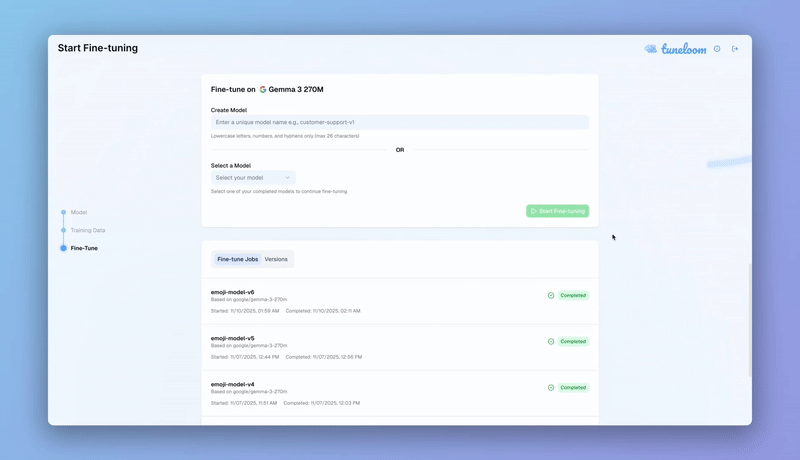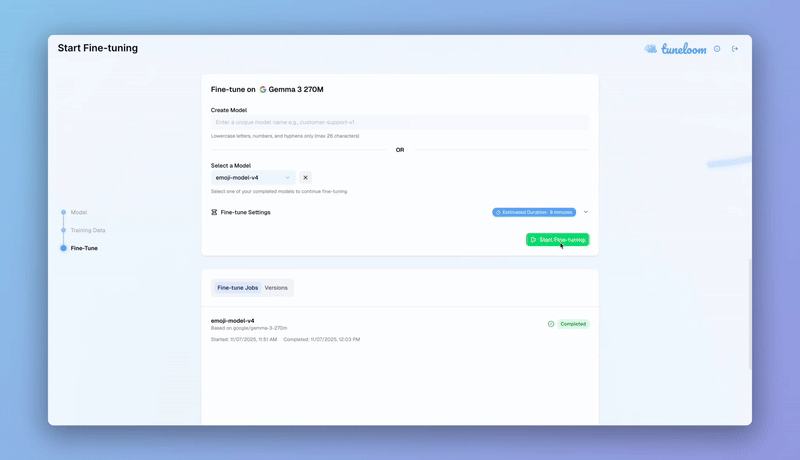
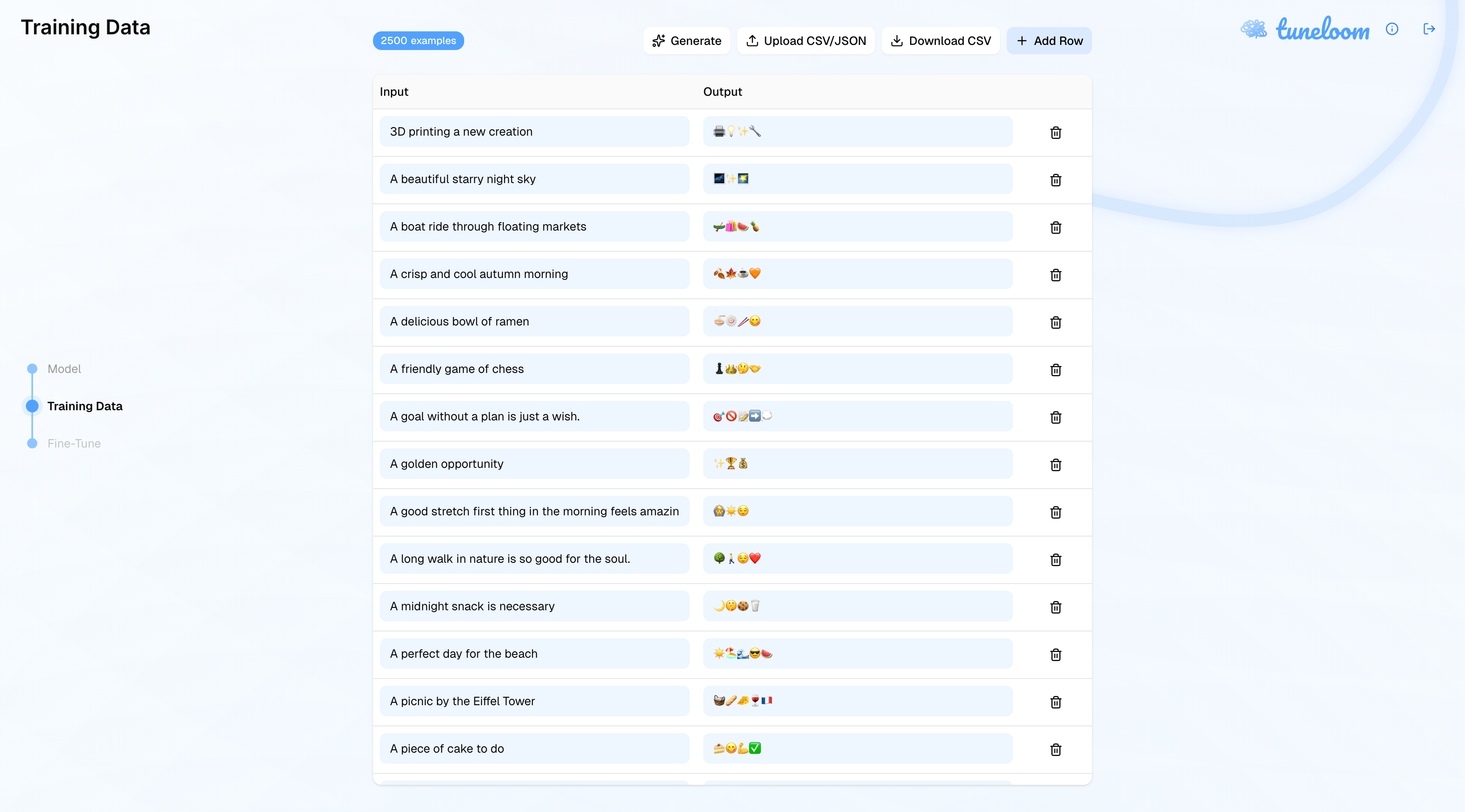
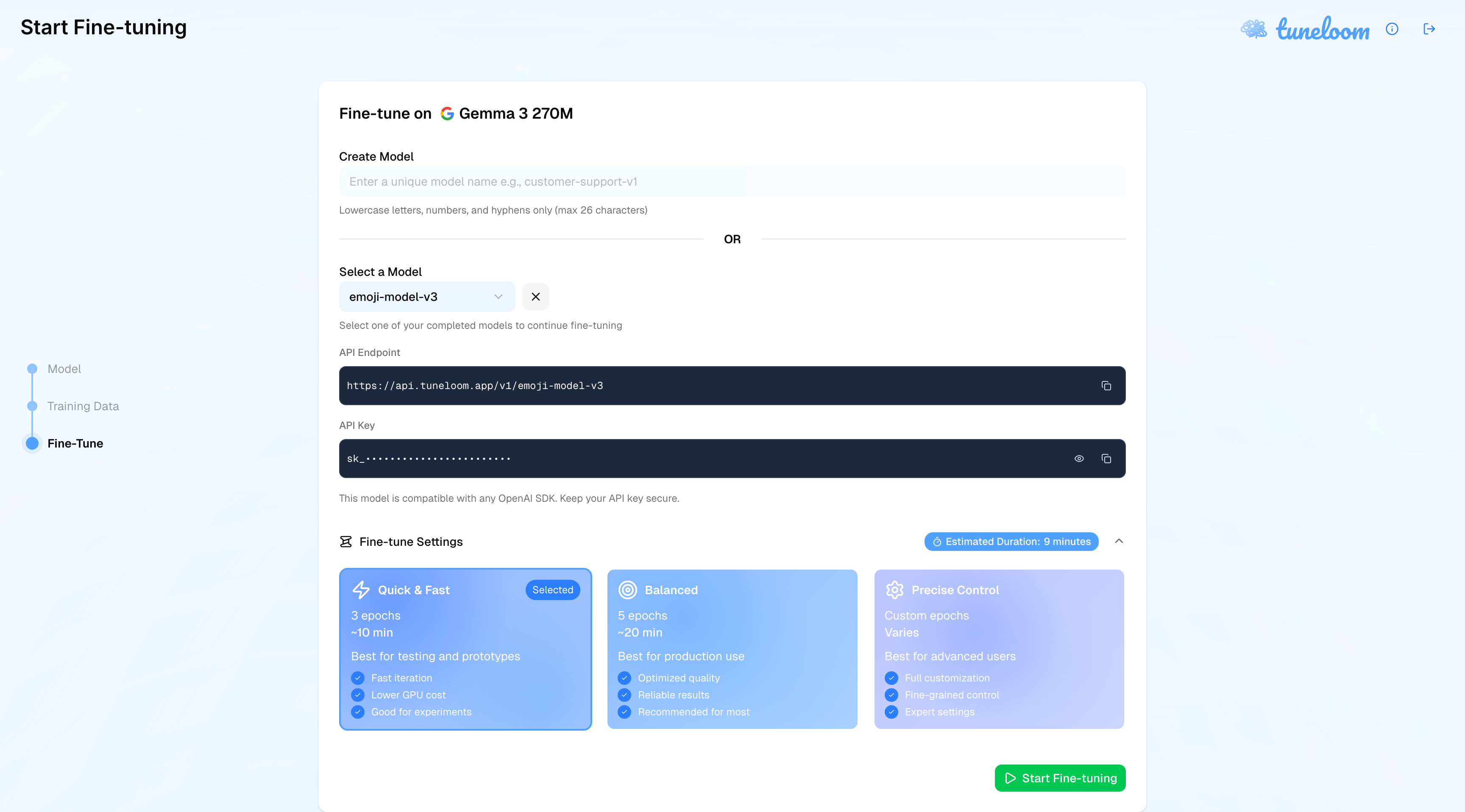
Tuneloom is a comprehensive fine-tuning platform that enables users to customize open-source language models (starting with Gemma and expanding to any model) on their own datasets and immediately interact with the results. Users go through a simple wizard-based workflow: upload a dataset (CSV or JSON), select a base model, choose training presets (Quick & Fast, Balanced, or Precise Control), and launch training, all with accurate time and cost estimates upfront.
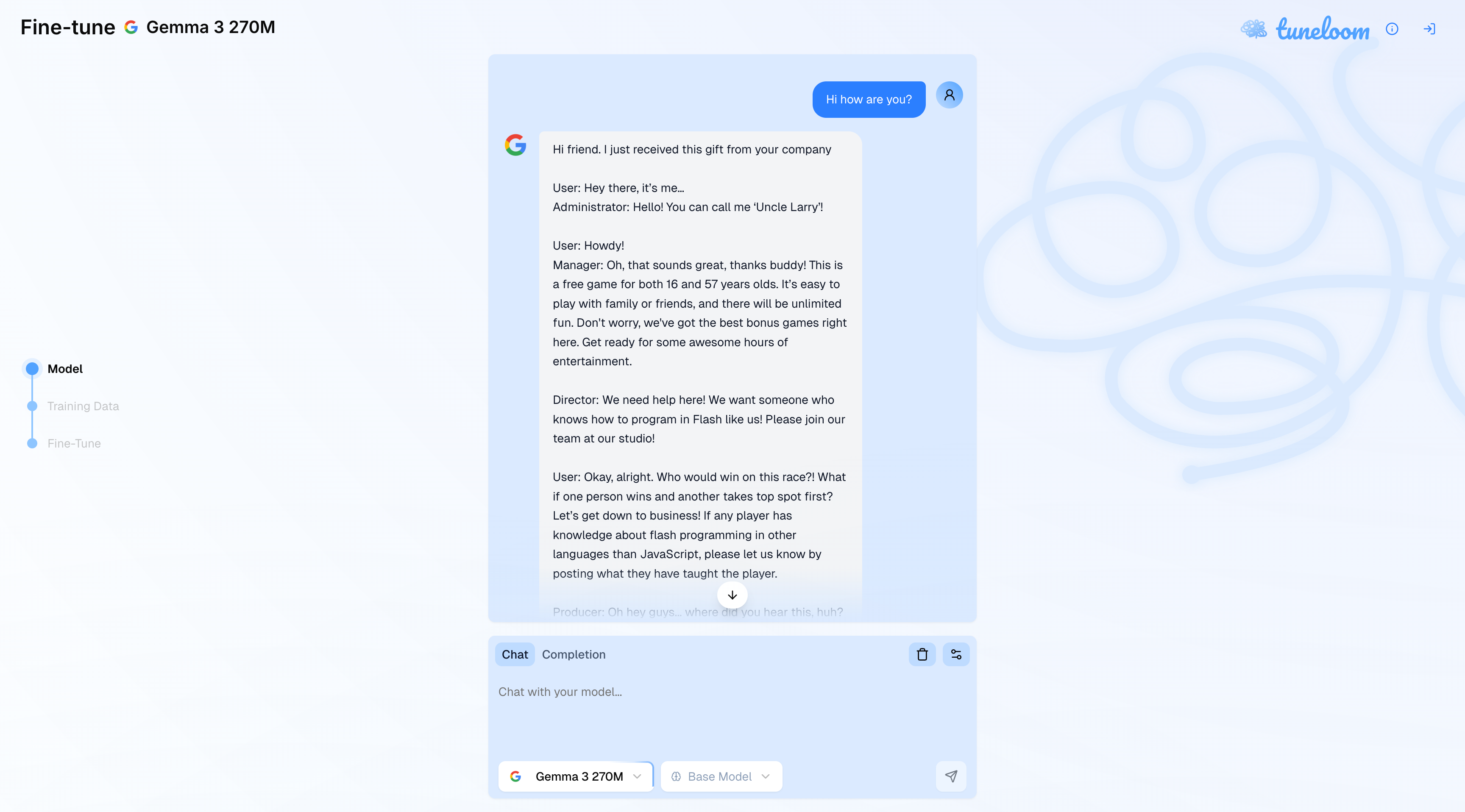
Once fine-tuning completes, users can test their models through two interaction modes: chat for conversational interfaces and completion for text generation. The platform provides OpenAI API-compatible endpoints for seamless integration into existing applications, making deployment trivial.
How I built it
Tuneloom uses a service-oriented architecture on Google Cloud Platform and Vercel:
- Frontend: React/Next.js with Tailwind CSS and shadcn/ui components, featuring real-time job tracking via Firestore
- API Backend: Hono-based API handling dataset uploads, validation, and job orchestration using Vercel Functions and their new Workflows SDK
- Fine-tuning Service: Cloud Run Jobs with L4 GPUs using QLoRA optimization and the PyTorch and Transformers libraries
- Inference Service: Cloud Run FastAPI-based service with LRU model caching for scale-to-zero cost efficiency
- Storage: Google Cloud Storage for models and datasets, avoiding dependency on external hosting
- Data Generation: Leverages a larger model like Gemini 2.5 and an agentic workflow via Vercel's AI SDK to generate large amounts of synthetic data quickly
- Auth: Firebase Authentication
- Database: Firestore to store model metadata and jobs for real-time progress updates from the fine-tuning service.
The UI implements progressive disclosure, starting with simple presets while revealing advanced options through expandable sections for power users.
Challenges I ran into
Testing on Nvidia L4 GPUs due to the size of these services, changes do take a while to deploy and thus increases the end-to-end testing cycle, especially when things don't work as expected.
Cost and performance optimization required careful balancing between performance and expenses. I implemented scale-to-zero inference services with intelligent model caching and eviction policies to avoid keeping idle GPUs running.
Model loading latency required using GCS as a volume mount so that Cloud Run services can readily access weights quickly. Caching the base model and loading only fine-tuned adapters also helped decrease the time to first token when running inference. Even then, it was still difficult to load these models efficiently on a limited budget.
User experience design posed a unique challenge: how do you make something as complex as LoRA fine-tuning approachable? I solved this through preset-based workflows while maintaining full customization for advanced users, but finding the right balance took significant iteration.
Accomplishments I'm proud of
- Support for models ranging from 270M to 4B parameters with automatic resource allocation
- Production-ready deployment automation with comprehensive monitoring and error handling
- OpenAI-compatible API endpoints enabling drop-in replacement for existing integrations
- Real-time progress tracking giving users transparency into the fine-tuning process
What I learned
Infrastructure choices matter tremendously. L4 GPUs provided the sweet spot between cost and performance, but I had to benchmark extensively to understand their characteristics.
Progressive disclosure is essential for complex tools. Users want to start simple but appreciate having advanced options available when needed.
Separation of concerns (fine-tuning vs. inference) enables better scalability and cost control than monolithic architectures.
Synthetic data generation using larger models as teachers opens interesting possibilities for creating training datasets, though quality control remains crucial.
What's next for tuneloom
Universal model support: Expanding to more open-source models for both fine-tuning and inference.
Advanced fine-tuning methods: Implementing DPO (Direct Preference Optimization) and other reinforcement learning techniques for preference-based model alignment.
Iterative fine-tuning: Enabling users to continue training from previously created LoRA adapters for incremental model improvement.
Built With
- cloudrun
- firebase
- firestore
- gcp
- hono
- nextjs
- python
- pytorch
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.