-
-
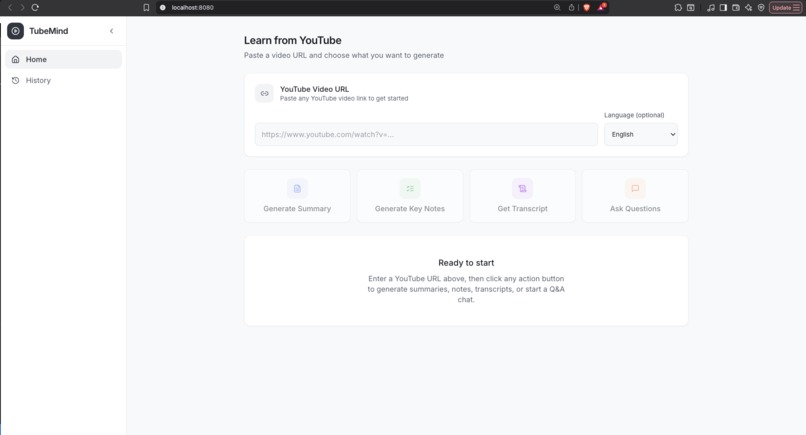
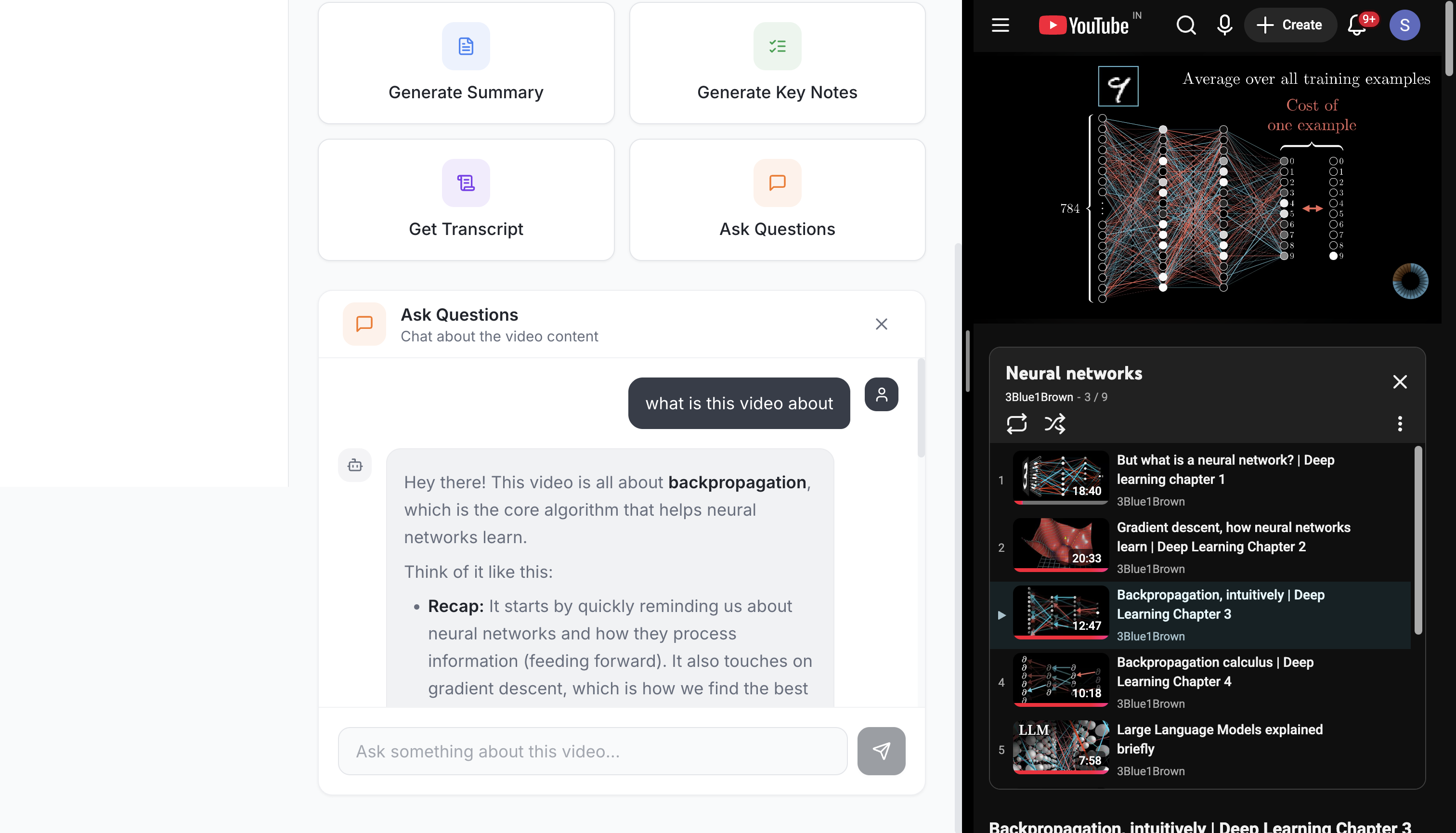
frontend layout
-
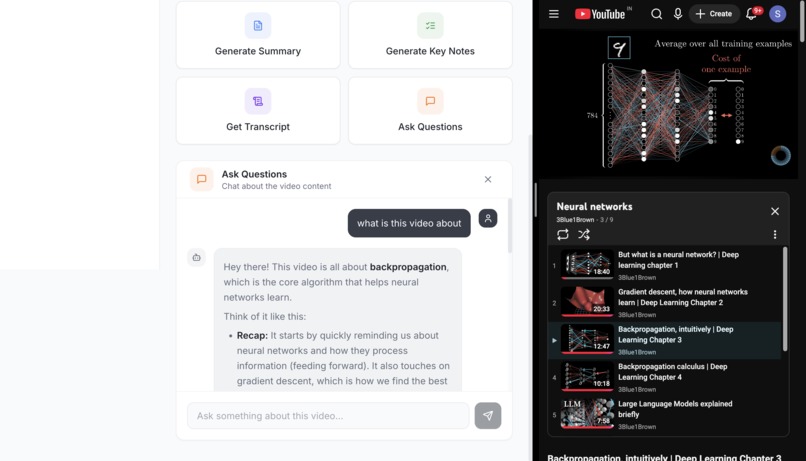
chat interface
-
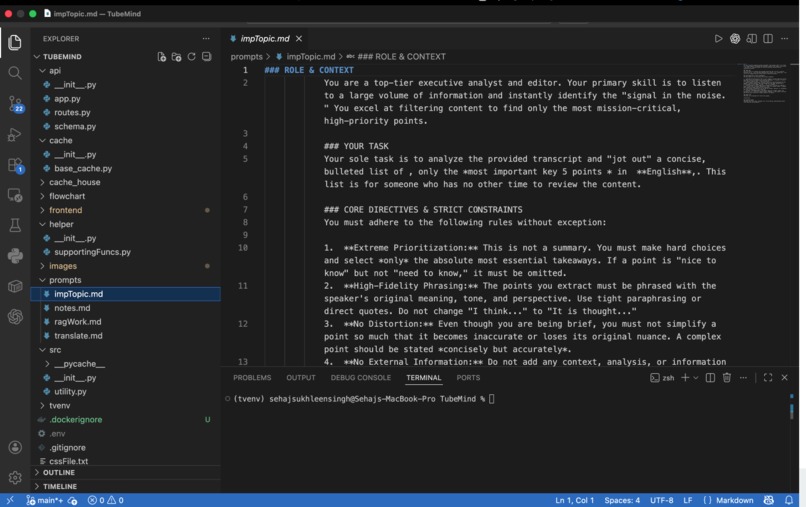
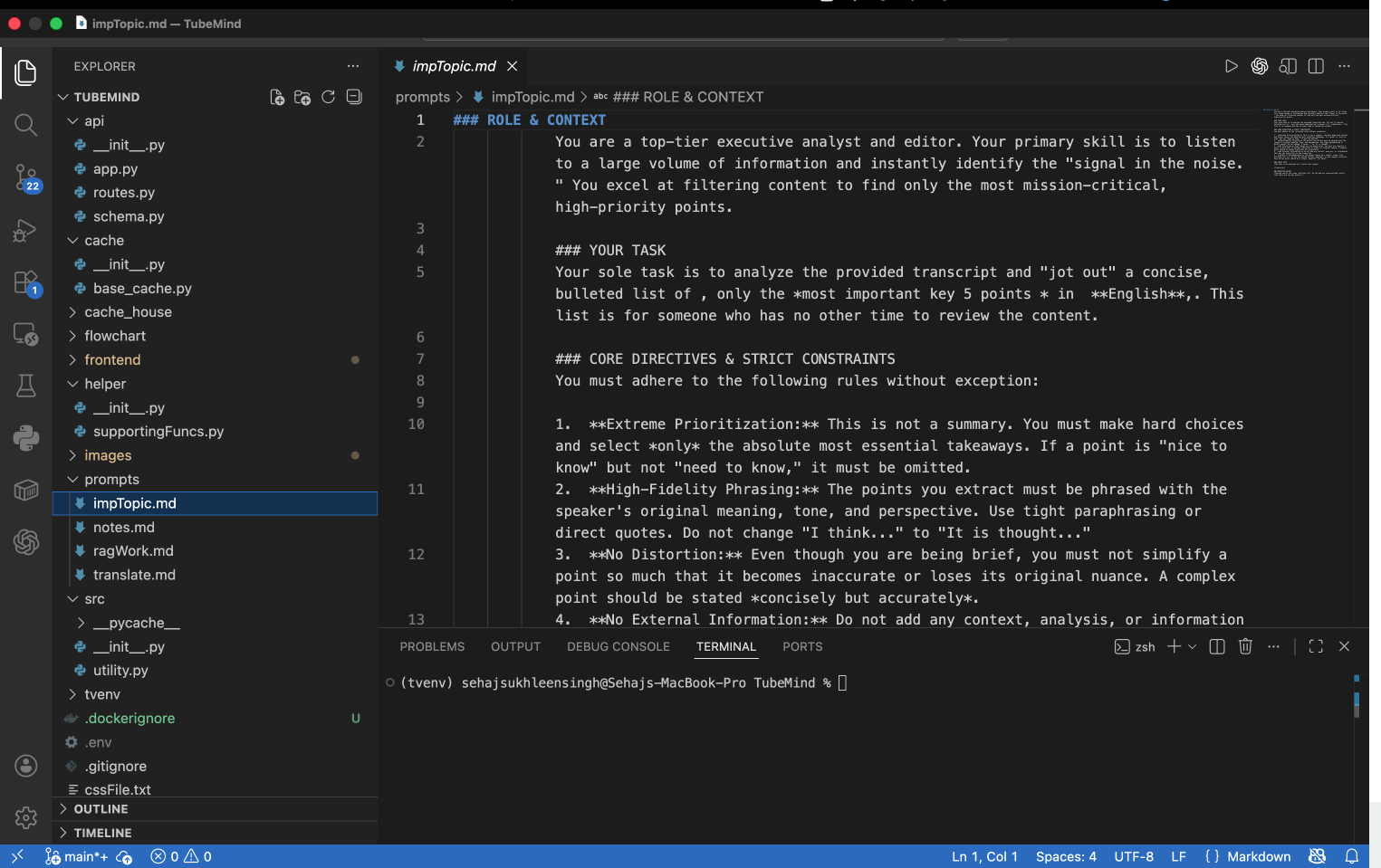
peek into the prompts for gemini model
Inspiration
TubeMind was inspired by the difficulty of learning efficiently from long YouTube videos. Valuable educational content is often buried inside hours of video, making it hard to revisit specific concepts or learn deeply without repeated watching. This challenge becomes even greater when useful content exists across different languages. I wanted to explore whether modern AI reasoning could turn passive video watching into an interactive learning experience.
What it does
TubeMind enables conversational learning from long YouTube videos. Users can paste a video link to ask questions, generate structured study notes, get concise summaries, analyze viewer sentiment, and receive timestamp-aware answers. It also supports cross-language interaction, allowing users to analyze videos in one language while asking questions or generating notes in another.
How we built it
TubeMind was designed as a modular, reasoning-first system centered around the Gemini 3 API, with a clear separation between data ingestion, retrieval, reasoning, and interaction layers.
Transcript Ingestion and Preprocessing
YouTube videos are processed using the YouTube Transcript API. Transcripts are cleaned, normalized, and segmented into semantically meaningful chunks to preserve context while enabling efficient retrieval and reasoning over long videos.Embedding and Retrieval Layer
Each transcript chunk is converted into vector embeddings using Hugging Face embedding models. These embeddings enable semantic retrieval of relevant video segments in response to user queries, forming the retrieval backbone of the system.Retrieval-Augmented Generation (RAG)
For each user query, relevant transcript chunks are retrieved based on embedding similarity. These retrieved segments are injected into carefully structured prompts, allowing Gemini 3 to ground its responses in the original video content rather than relying on hallucinated knowledge.Gemini 3 Reasoning Engine
Gemini 3 is used as the core large language model due to its long-context and multilingual reasoning capabilities. Instead of generating isolated summaries, Gemini 3 reasons across multiple retrieved chunks to generate coherent answers, structured notes, summaries, and timestamp-aware responses.Prompt Design and Response Structuring
Prompts are explicitly designed to encourage global understanding across the entire video. Output formats are constrained to produce structured responses such as bullet-point notes, concise summaries, and direct answers with relevant timestamps.Backend Architecture
The backend is implemented using FastAPI, which orchestrates transcript processing, embedding generation, retrieval logic, Gemini 3 interactions, and response formatting. This design keeps the system modular, extensible, and easy to debug.Caching and Performance Optimization
To reduce latency and improve responsiveness, processed transcripts, embeddings, and intermediate results are cached. This enables faster follow-up queries on the same video without reprocessing the entire pipeline.Frontend Interaction Layer
A lightweight frontend provides a conversational interface that allows users to ask questions, generate notes, and navigate video content interactively. The frontend communicates with the backend through clean API endpoints.Deployment and Scalability
The system is designed to be cloud-deployable, with a clear separation between frontend and backend services, enabling scalable real-world deployment.
Challenges we ran into
A key challenge was maintaining accuracy while reasoning over very long transcripts. Encouraging global understanding instead of surface-level summaries required careful prompt design and iteration. Performance was another challenge due to repeated transcript processing, which was addressed by introducing caching to improve response speed.
Accomplishments that we're proud of
We are proud of building a working system that reasons over entire videos rather than short excerpts. Enabling conversational interaction, timestamp-aware answers, and cross-language learning within a single application was a significant achievement within the hackathon timeframe.
What we learned
This project showed that large language models are most effective when treated as reasoning systems rather than simple text generators. Long-context and multilingual reasoning, combined with thoughtful prompt design and performance optimizations, can significantly improve learning tools.
What's next for TubeMind
Future plans include improving reasoning over extremely long videos, expanding multilingual support, adding flexible note customization and export options, exploring richer multimodal understanding, and building a Chrome extension for direct interaction on YouTube.
Built With
- docker
- dotenv
- fastapi
- google-generative-ai
- huggingface
- langchain
- pydantic
- python
- retrieval-augmented-generation
- typescript




Log in or sign up for Devpost to join the conversation.