-
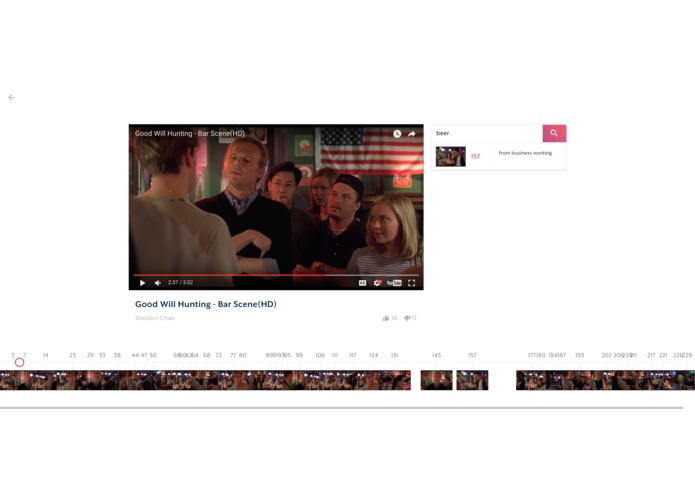
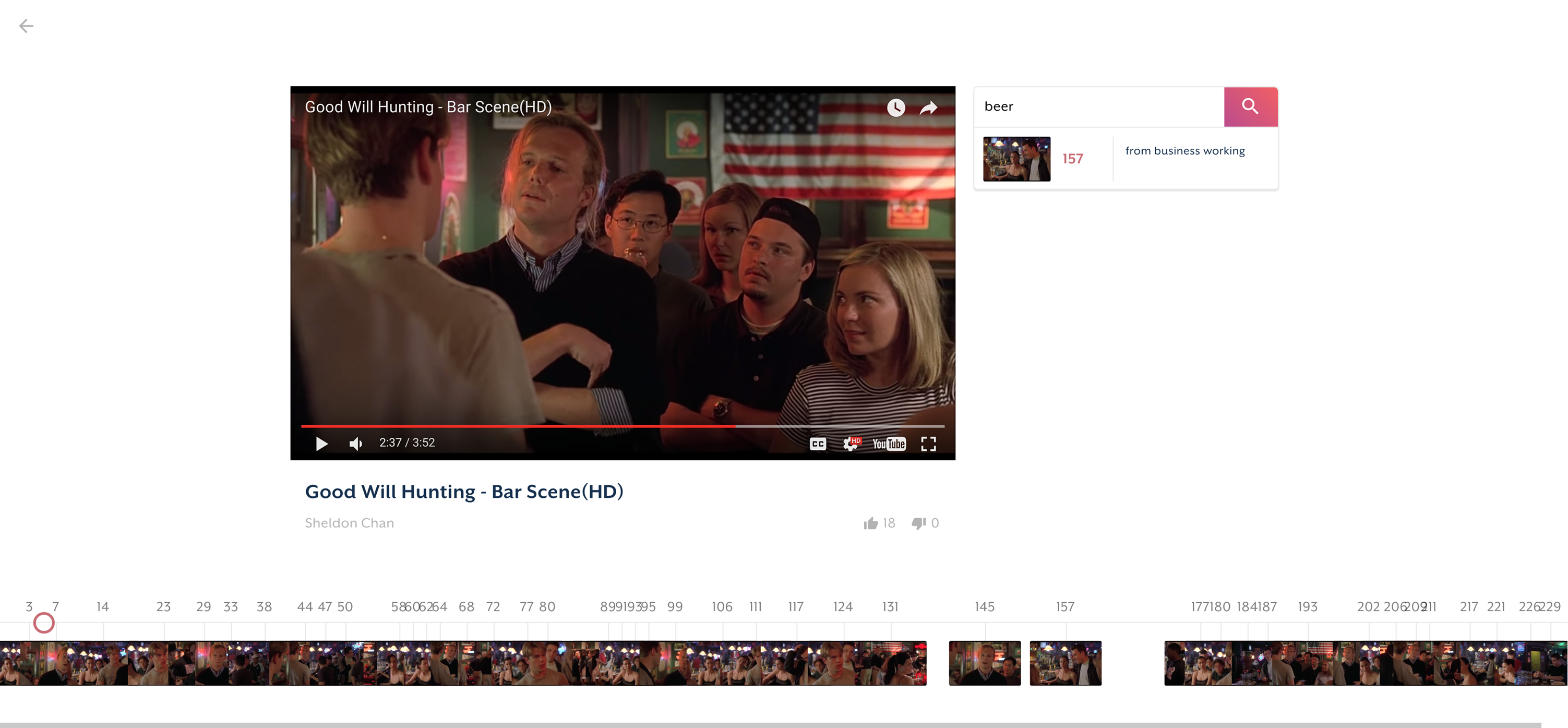
Finds a scene with beer (guy in the back drinking beer in the next few seconds)
-
Main page
-
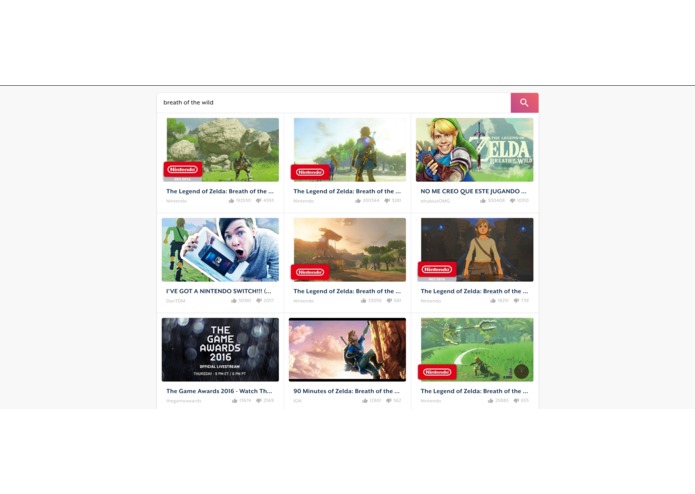
Finding a video
-
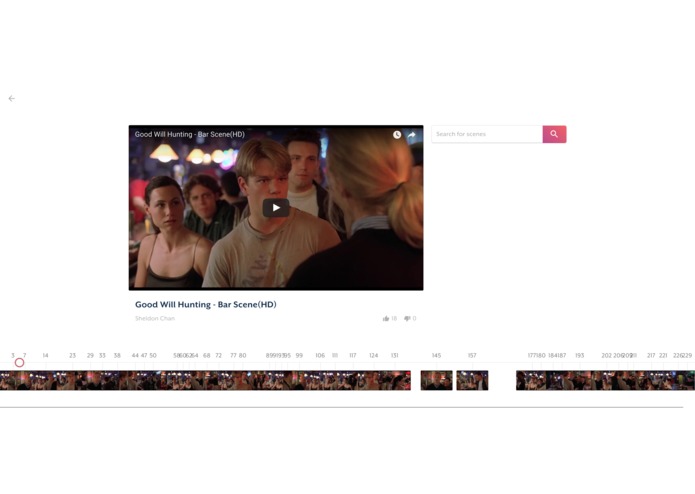
Video loaded in, scene segmentation at the bottom.
Inspiration
Machine learning and AI is the future. By applying it to various aspects of our lives, we can improve and enhance the experiences that we have.
And yet, certain aspects of watching videos are still as tediously ordinary as ever. You find a video, click play and watch.
I often find myself searching through a video to find that one funny scene. Or having to watch an entire videtho, when all I really care about is a specific scene somewhere scene.
With TubeAI, these problems are no more. TubeAI improved the video watching experience by comprehensively showing the scenes of a video and allowing users to search within a video to find the right scene.
What it does
TubeAI enhances the video watching experience by allowing users to see the scenes of a video and search through them.
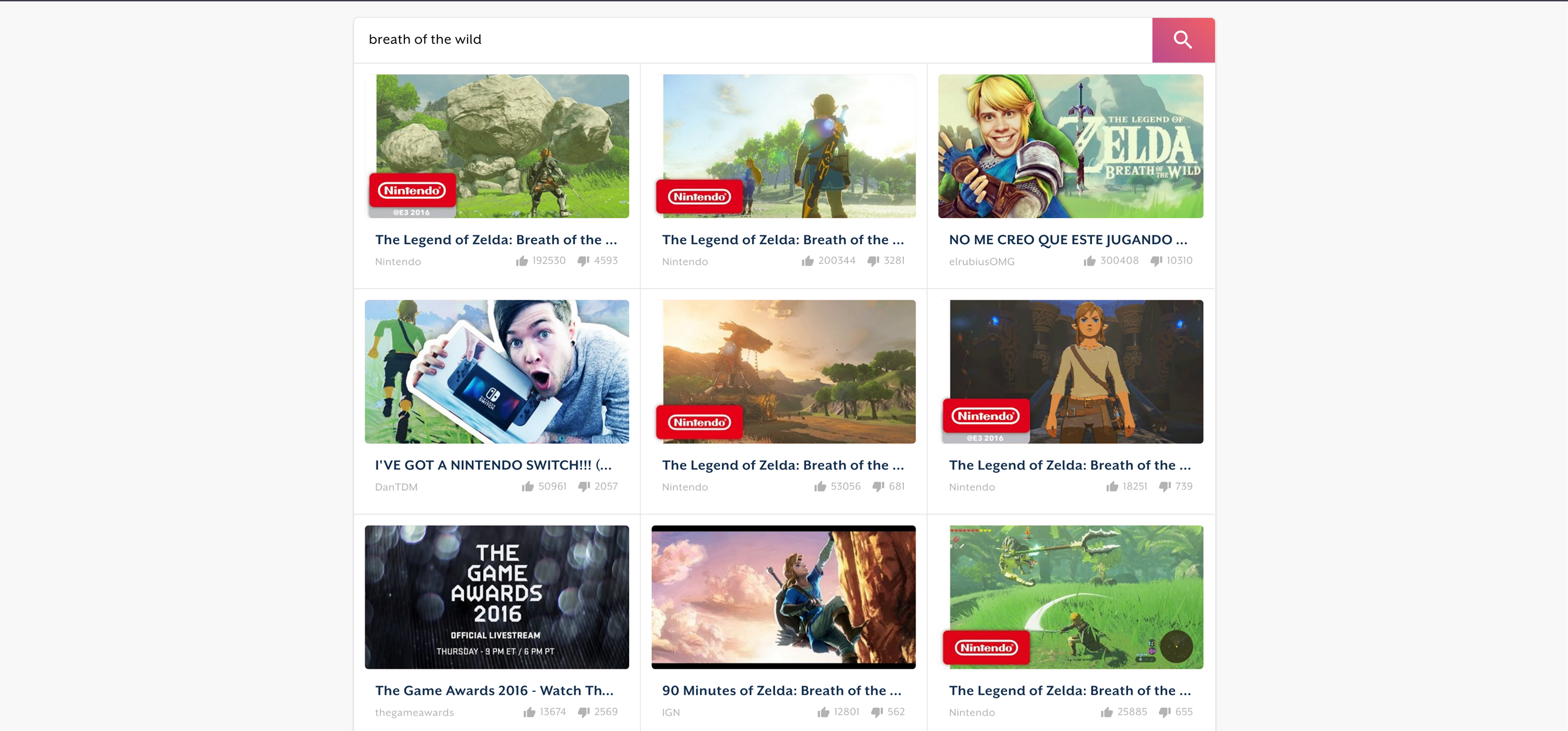
Imagine you were watching a long video and you wanted to find the scene with the big dog. You remember that it was towards the middle of the video (or was it closer to the beginning?) but you're not sure where it is. With TubeAI, you simply search for "dog" and find the right scene!
How it works
Once you've selected a video that you want to watch, the URL is sent to our Azure server and we download the video for analysis.
We split up the video into frames and pass each frame into a trained Inception v3 model, to retrieve the predictions. We run the model on our server and multithread the requests to it in order to get the predictions as soon as possible.
We simultaneously use the scenes and try to detect significant cuts/scene breaks in the video using an optical flow algorithm. This is the basis for our scene segmentation.
Then, we bring everything together by assigning both tags and captions to scenes. This allows us to build a data structure that allows us to use search terms to identify the relevant scenes.
Upon receiving a search term, TubeAI uses NLTK's WordNet, to build up terms that are closely related to the video. We then retrieve all of the relevant timestamps (using the aforementioned data structure) and return them to our front-end.
Challenges we ran into
It was difficult to deploy the trained Tensorflow model and prepare it for inference. However the speed improvement that we got made the trouble worth it.
Accomplishments that we're proud of
We're proud of the entire application! We brought together many challenging and independent ideas to create a useful and effective product.
What's next for TubeAI
Given that this is a hackathon, we passed on many potential improvements to our pipeline.
Ultimately, it would be most effect to fine-tune the model with video frames (it was initially pre-trained by Google on the MSCOCO dataset) to make our tags more relevant.
We intend to continue working on this, and one of the key improvements to make will be using word/phrase embeddings to search in vector space rather than using synonyms.
Conclusion
We built something really cool and are really proud of it! Come check it out to see a demo! We can also improve our predictions by using context (i.e., use the predictions on the previous frames when running the inference for the current frame).
Built With
- aiohttp
- azure
- heart
- machine-learning
- natural-language-processing
- nltk
- opencv
- python
- react
- redux
- tensorflow
- youtube



Log in or sign up for Devpost to join the conversation.