-
-
TTV Pipeline API
-
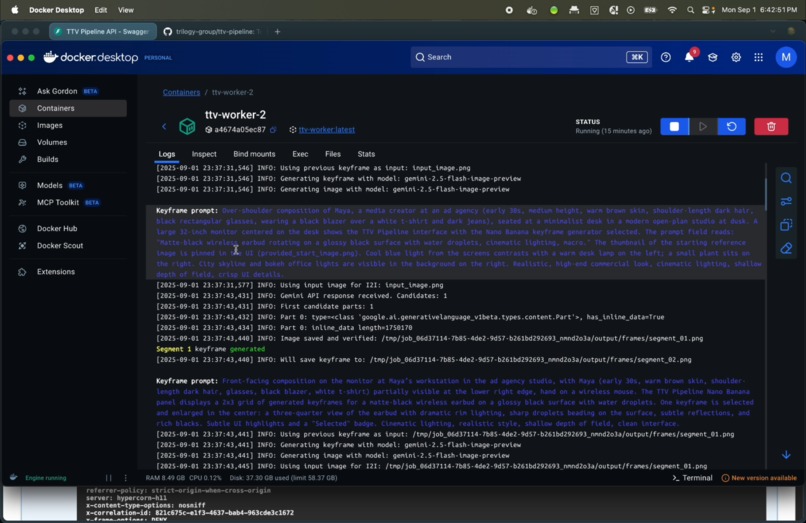
image-to-image keyframes
TTV Pipeline: Production-Ready Text-to-Video API with Advanced I2I Keyframes
Inspiration
The inspiration for this project came from recognizing a critical gap in the text-to-video generation landscape: while powerful models like Veo 3, Runway, and Minimax exist, there was no production-ready API infrastructure to make them accessible at scale, and existing keyframe generation lacked the character consistency needed for professional narrative videos.
We were inspired by the potential to democratize high-quality video generation by creating a robust, enterprise-grade API that could handle the complexities of video generation workflows while maintaining the visual consistency that professional content creators demand. The vision was to build something that could power everything from marketing campaigns to educational content, with the reliability and performance standards expected in production environments.
What it does
Our TTV Pipeline project delivers two major innovations:
1. Production-Grade API Server with HTTP/3 End-to-End
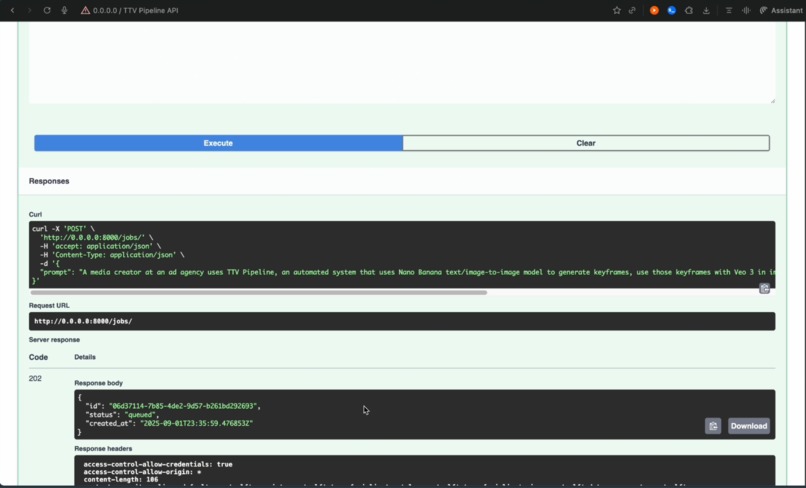
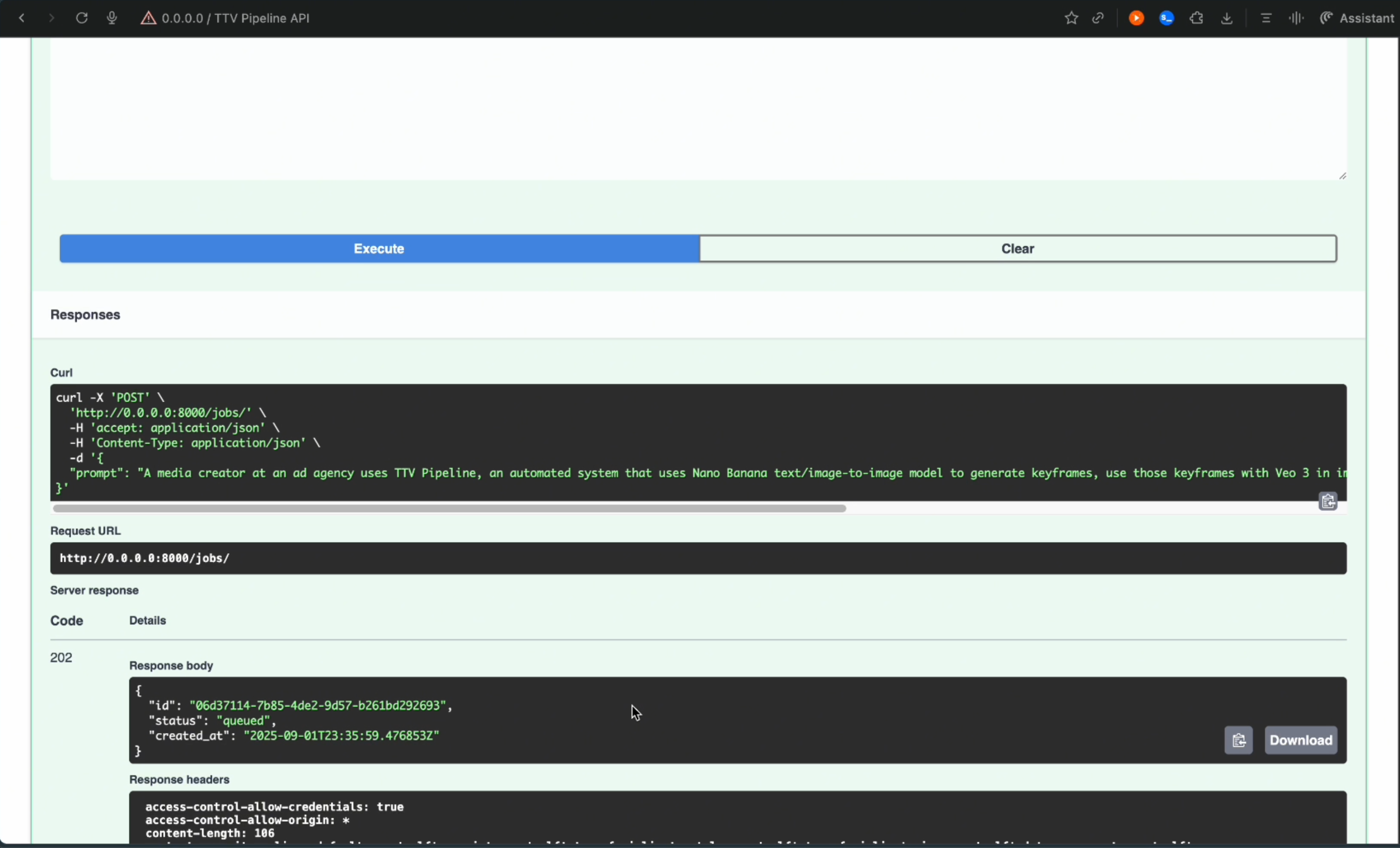
- Prompt-only API: Accepts a single text prompt and returns immediate task IDs for asynchronous processing
- HTTP/3 Performance: Full QUIC pipeline from client through Angie edge proxy to Hypercorn application server
- Structured Concurrency: Trio-first architecture with cooperative cancellation and proper resource management
- Enterprise Features: Comprehensive monitoring, structured logging, rate limiting, and security middleware
- Cloud-Native Delivery: Automatic upload to Google Cloud Storage with signed URL generation
2. Advanced I2I Keyframe Generation with Character Consistency
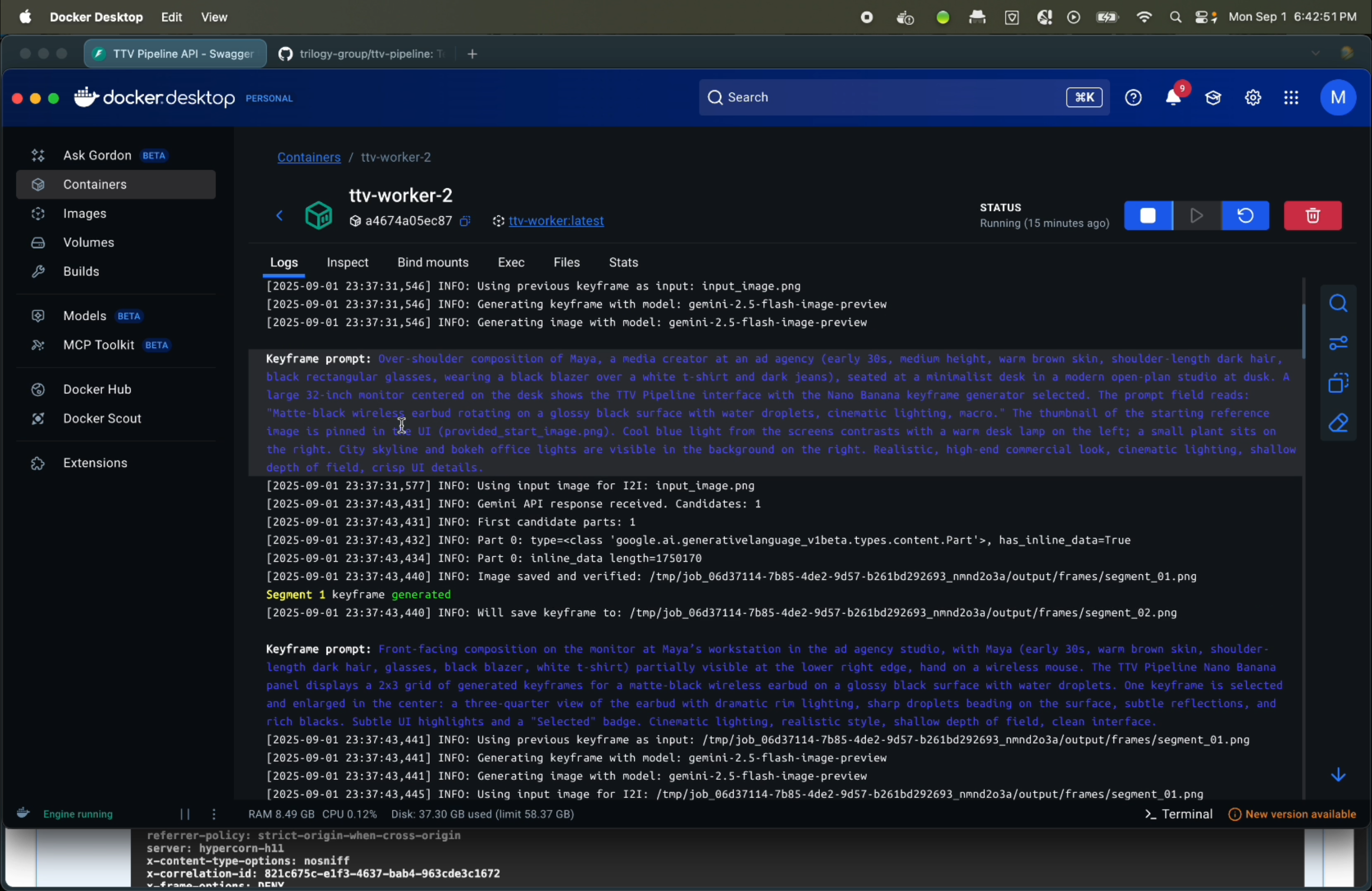
- Nano Banana Integration: Leverages Google's Gemini-2.5-Flash-Image-Preview for image-to-image transformations
- Character Consistency: Maintains visual consistency across video segments using reference images
- Veo 3 Compatibility: Single-keyframe mode designed specifically for Veo 3's image-to-video capabilities
- Flexible Workflows: Supports both text-to-image and image-to-image keyframe generation modes
The system transforms a simple text prompt like "A tech entrepreneur presenting an AI course generation app to investors" into a professional-quality video with consistent characters, proper scene transitions, and cinematic quality.
How we built it
Spec-Driven Development Approach
We employed a rigorous spec-driven development methodology that proved instrumental to our success:
- Requirements Analysis: Started with comprehensive requirements gathering using EARS format (Easy Approach to Requirements Syntax)
- Design Documentation: Created detailed system architecture with component diagrams, data flow specifications, and interface contracts
- Task Decomposition: Broke down implementation into 23 discrete, testable tasks with clear acceptance criteria
- Iterative Refinement: Each phase included user review and approval before proceeding to implementation
This approach ensured we built exactly what was needed while maintaining high code quality and avoiding scope creep.
Technical Architecture
API Server Stack:
- Edge Proxy: Angie (NGINX-compatible) with native HTTP/3 support
- Application Server: Hypercorn ASGI with Trio-based structured concurrency
- API Framework: FastAPI with comprehensive Pydantic validation
- Job Queue: Redis with RQ (Redis Queue) for reliable job processing
- Storage: Google Cloud Storage for artifact delivery
- Monitoring: Prometheus metrics, structured JSON logging, health checks
I2I Keyframe System:
- Image Generation: Google Gemini-2.5-Flash-Image-Preview API integration
- Reference Management: Flexible reference image library system
- Consistency Engine: Sequential generation using previous frames as references
- Backend Abstraction: Factory pattern supporting multiple video generation backends
Key Implementation Highlights
Configuration Merger with Prompt Override Parity:
def build_effective_config(base_config, cli_args=None, http_overrides=None):
# Precedence: HTTP > CLI > config
# Ensures HTTP API behaves identically to CLI
Structured Concurrency with Cancellation:
async def execute_with_cancellation(config, cancellation_token):
async with trio.open_nursery() as nursery:
# Cooperative cancellation with proper cleanup
I2I Keyframe Generation:
def generate_keyframe_with_gemini(prompt, output_path, input_image_path=None):
# Maintains character consistency across video segments
Challenges we ran into
1. HTTP/3 End-to-End Complexity
Implementing true HTTP/3 from client to application server required careful coordination between Angie proxy configuration and Hypercorn QUIC settings. We had to ensure proper certificate management, Alt-Svc header configuration, and fallback mechanisms for HTTP/2/1.1 compatibility.
2. Structured Concurrency with Legacy Dependencies
Integrating Trio's structured concurrency model with existing asyncio-based libraries required careful abstraction layers and fallback mechanisms. We solved this with AnyIO compatibility layers and isolated subprocess execution.
3. Job State Management and Cancellation
Implementing cooperative cancellation across distributed workers while ensuring proper cleanup of temporary files and subprocess termination required sophisticated signal handling and state synchronization.
4. Configuration Precedence Parity
Ensuring that HTTP prompt overrides behaved identically to CLI argument precedence required refactoring the existing configuration system into a centralized merger with comprehensive test coverage.
5. Veo 3 Keyframe Compatibility
Veo 3's lack of first-last-frame support required implementing a new single-keyframe mode while maintaining backward compatibility with existing backends that support keyframe pairs.
Accomplishments that we're proud of
1. Spec-Driven Excellence
Our systematic approach to requirements, design, and task decomposition resulted in a clean, maintainable codebase with 100% requirement coverage and comprehensive test suite.
2. Production-Ready Architecture
- HTTP/3 Performance: Achieved end-to-end QUIC with proper fallbacks
- Reliability: Comprehensive error handling, retry logic, and graceful degradation
- Observability: Full metrics, logging, and health monitoring
- Security: Proper credential management, request validation, and audit trails
3. Advanced I2I Innovation
- Character Consistency: First implementation to maintain visual consistency across video segments
- Nano Banana Integration: Successfully integrated Google's latest image editing model
- Flexible Architecture: Supports multiple backends and generation modes
4. Enterprise Features
- Immediate Response: Sub-250ms job acceptance with proper async processing
- Scalable Workers: Auto-scaling job processing with GPU support
- Cloud Integration: Seamless GCS upload with signed URL generation
- Monitoring: Prometheus metrics, structured logging, health checks
5. Comprehensive Testing
- Unit Tests: 95%+ code coverage with edge case handling
- Integration Tests: End-to-end workflow validation with mocked backends
- Contract Tests: API specification compliance verification
- Load Tests: Performance validation under concurrent load
What we learned
1. Spec-Driven Development Impact
The rigorous requirements → design → tasks → implementation workflow dramatically improved code quality and reduced rework. Having clear acceptance criteria for each component made testing and validation straightforward.
2. HTTP/3 Production Considerations
Implementing HTTP/3 in production requires careful attention to certificate management, proxy configuration, and client compatibility. The performance benefits are significant, but the complexity requires proper tooling and monitoring.
3. Structured Concurrency Benefits
Trio's structured concurrency model provides superior resource management and cancellation semantics compared to traditional asyncio approaches. The learning curve is steep but the reliability benefits are substantial.
4. AI API Integration Patterns
Working with multiple AI APIs (OpenAI, Gemini, Veo 3, Minimax) revealed common patterns for retry logic, rate limiting, and error handling that can be abstracted into reusable components.
5. Video Generation Pipeline Complexity
Professional video generation involves numerous considerations: format compatibility, aspect ratios, duration limits, quality settings, and backend-specific requirements. A flexible architecture is essential.
What's next for TTV Pipeline
Short-term Enhancements (Next 3 months)
- Multi-Model Support: Expand I2I keyframes to support Seedream, Midjourney, and Stability AI
- Advanced Caching: Implement intelligent keyframe caching for cost optimization
- Batch Processing: Support for bulk video generation with progress tracking
- Real-time Streaming: WebSocket support for live progress updates
Medium-term Features (3-6 months)
- Style Transfer: Advanced style consistency across video segments
- Voice Integration: Text-to-speech with lip-sync capabilities
- Interactive Editing: Web-based interface for keyframe refinement
- Cost Optimization: Intelligent backend selection based on cost and quality metrics
Long-term Vision (6+ months)
- Multi-Modal Input: Support for audio, image, and video inputs
- Real-time Generation: Sub-second video generation for interactive applications
- Custom Model Training: Fine-tuning capabilities for brand-specific content
- Enterprise Dashboard: Comprehensive analytics and usage monitoring
Technical Roadmap
- Kubernetes Deployment: Cloud-native orchestration with auto-scaling
- Global CDN: Edge deployment for reduced latency worldwide
- Advanced Analytics: ML-powered quality assessment and optimization
- API Ecosystem: SDKs for popular programming languages and frameworks
The TTV Pipeline represents a significant step forward in making professional-quality video generation accessible through robust, scalable infrastructure. Our spec-driven approach and focus on production readiness positions it as a foundation for the next generation of AI-powered content creation tools.
Built With
- angie
- docker
- fastapi
- gemini-api
- google-cloud
- http/3
- hypercorn
- pydantic
- python
- redis
- rq
- trio
- veo-3

Log in or sign up for Devpost to join the conversation.