-
-
Landing Page
-
Generating Drug Candidates
-
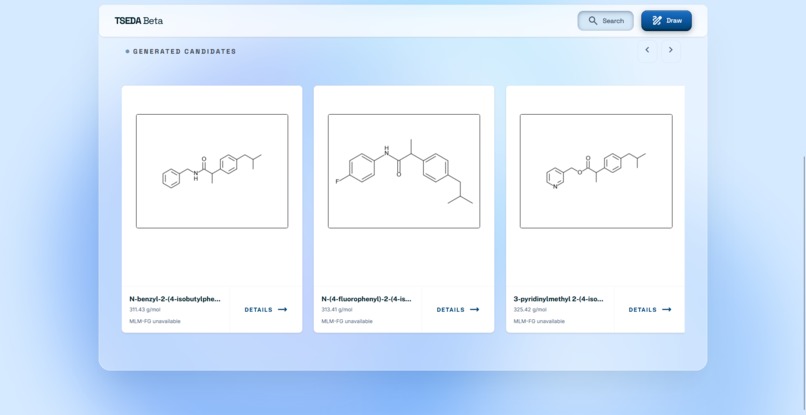
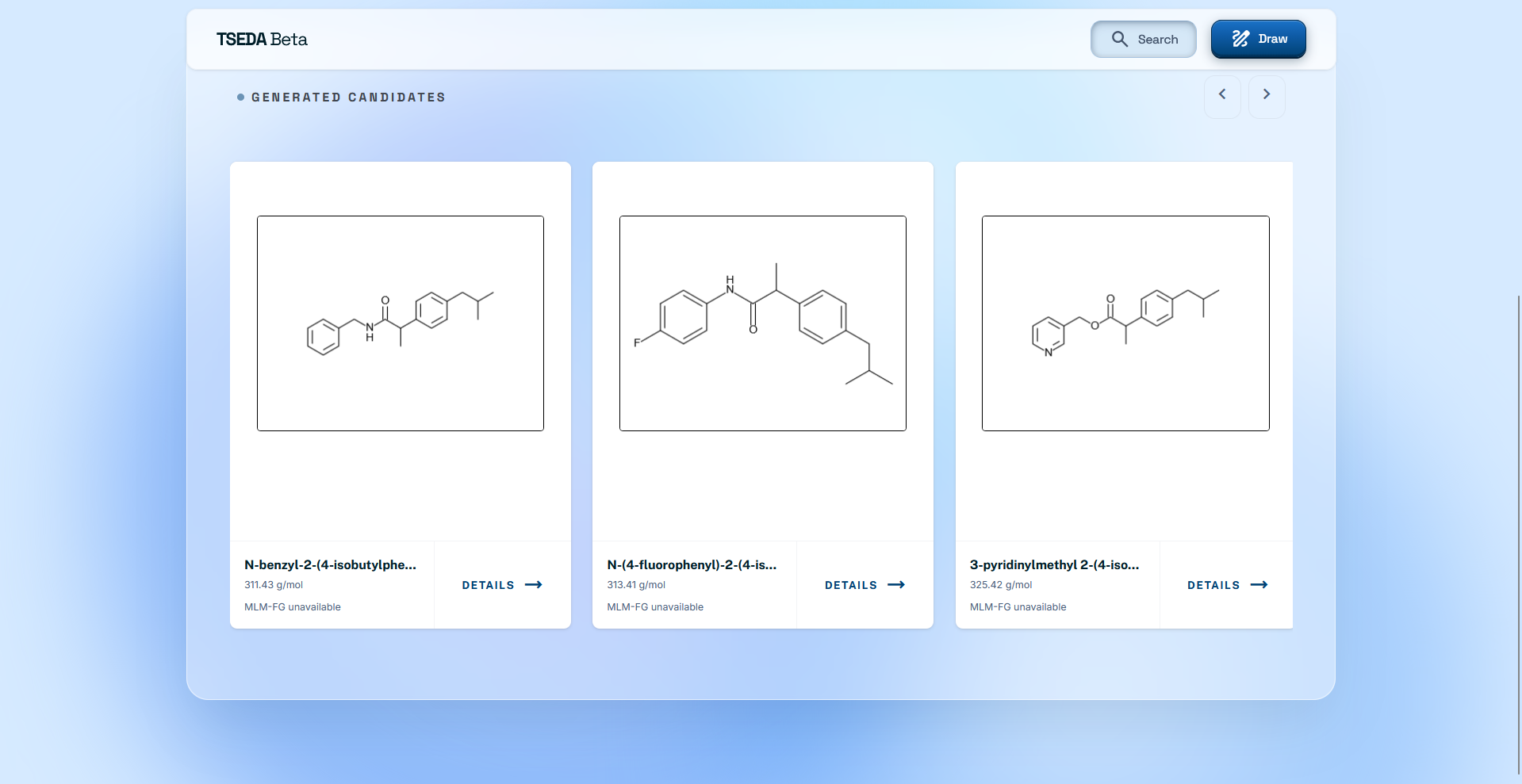
Generated Candidate List
-
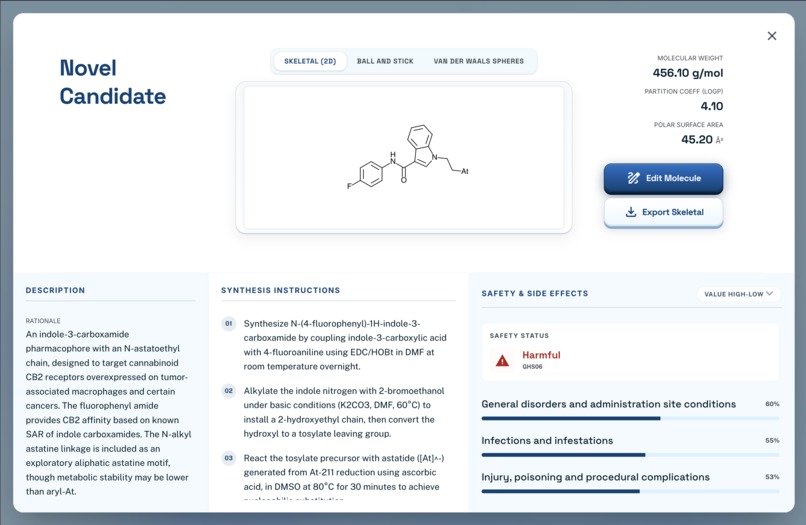
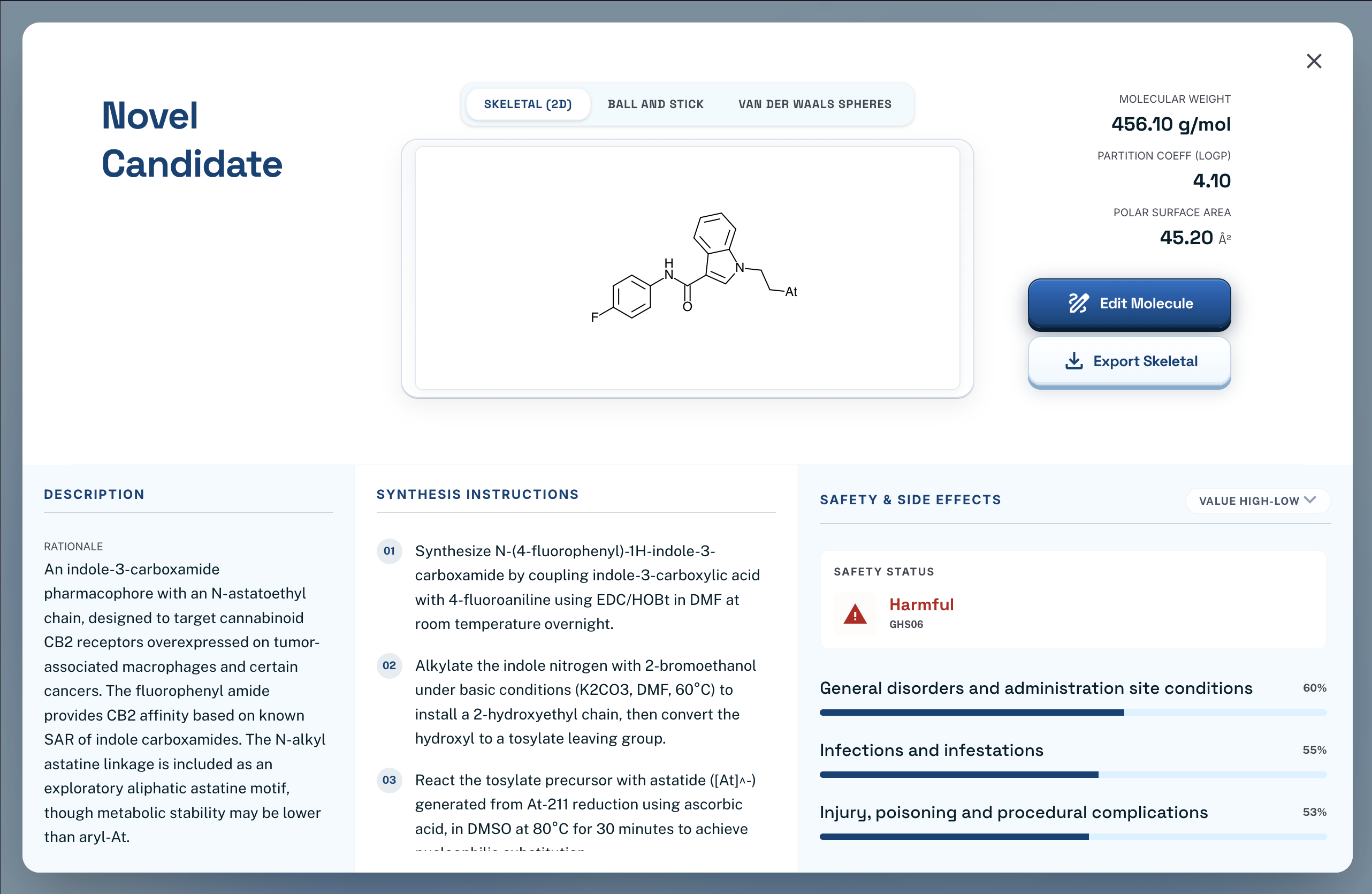
Candidate Details
-
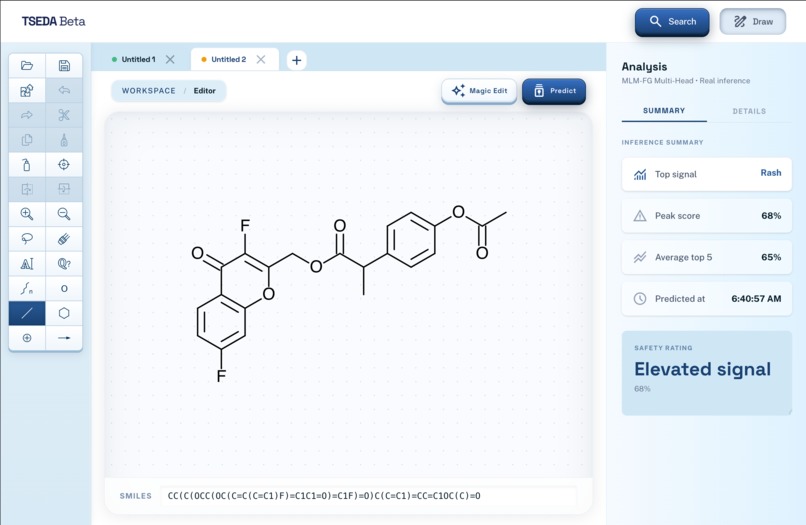
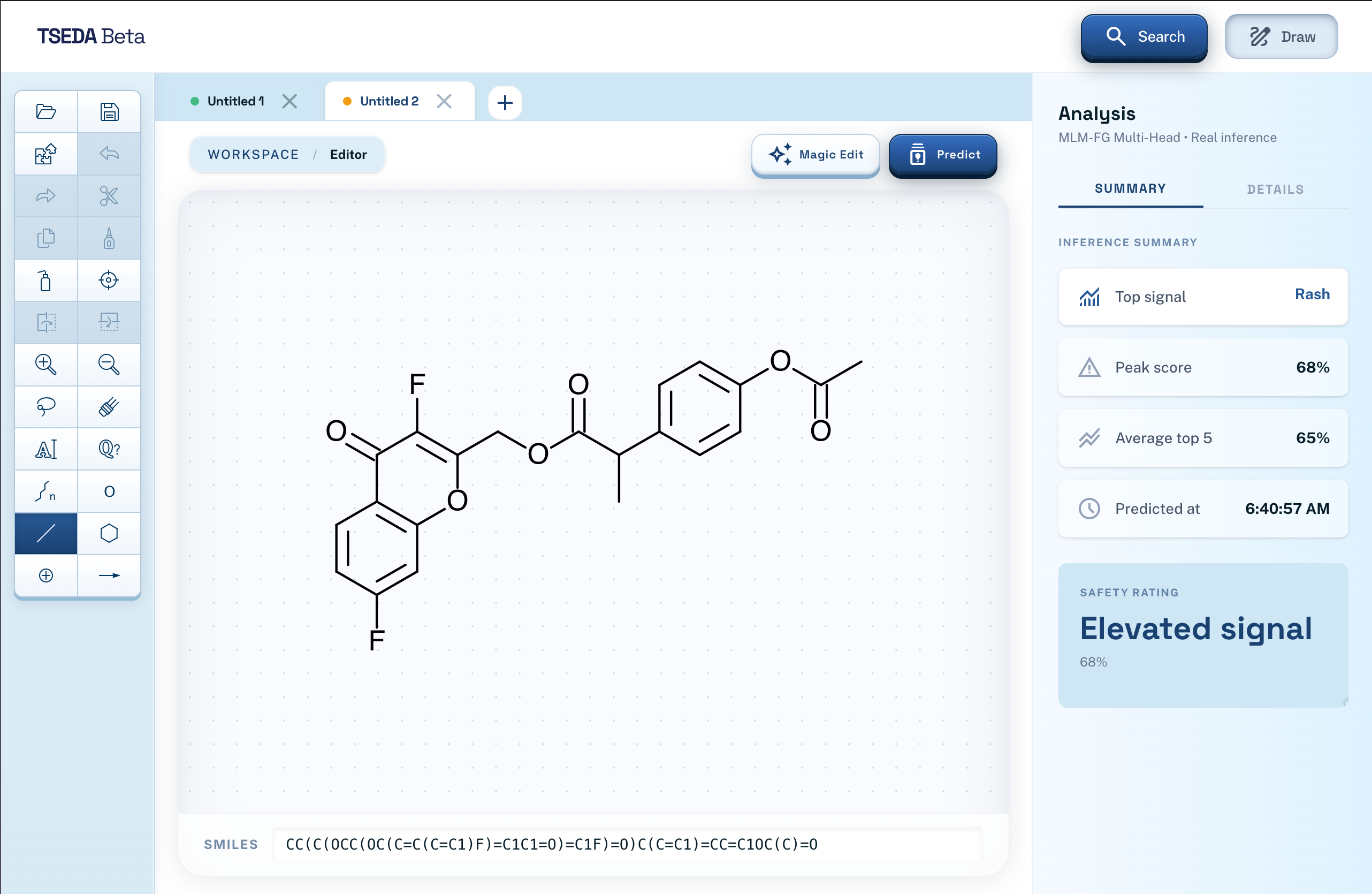
Editor
-
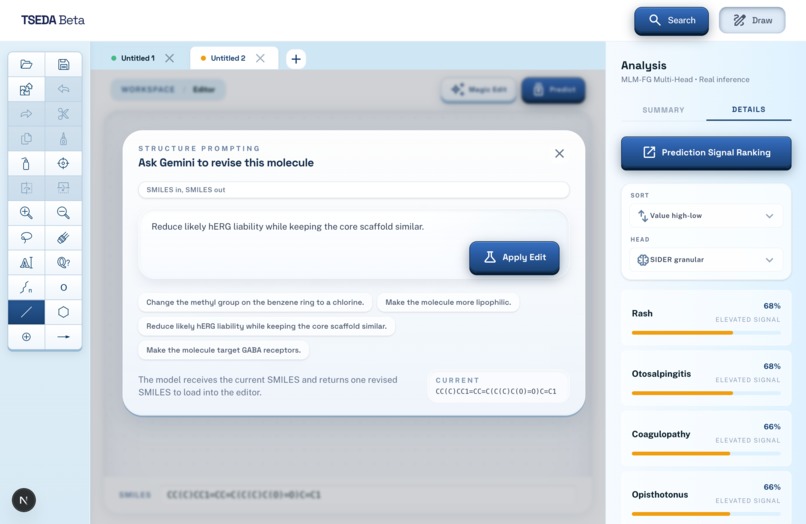
Gemini Assisted Drafting
-
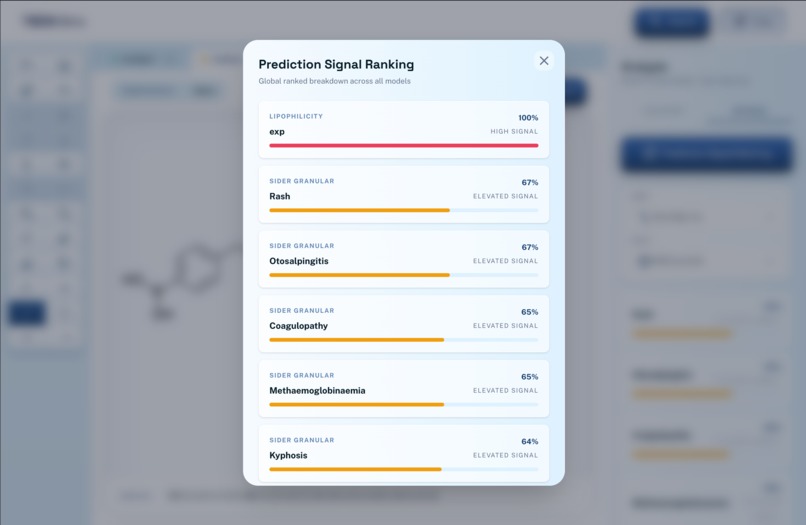
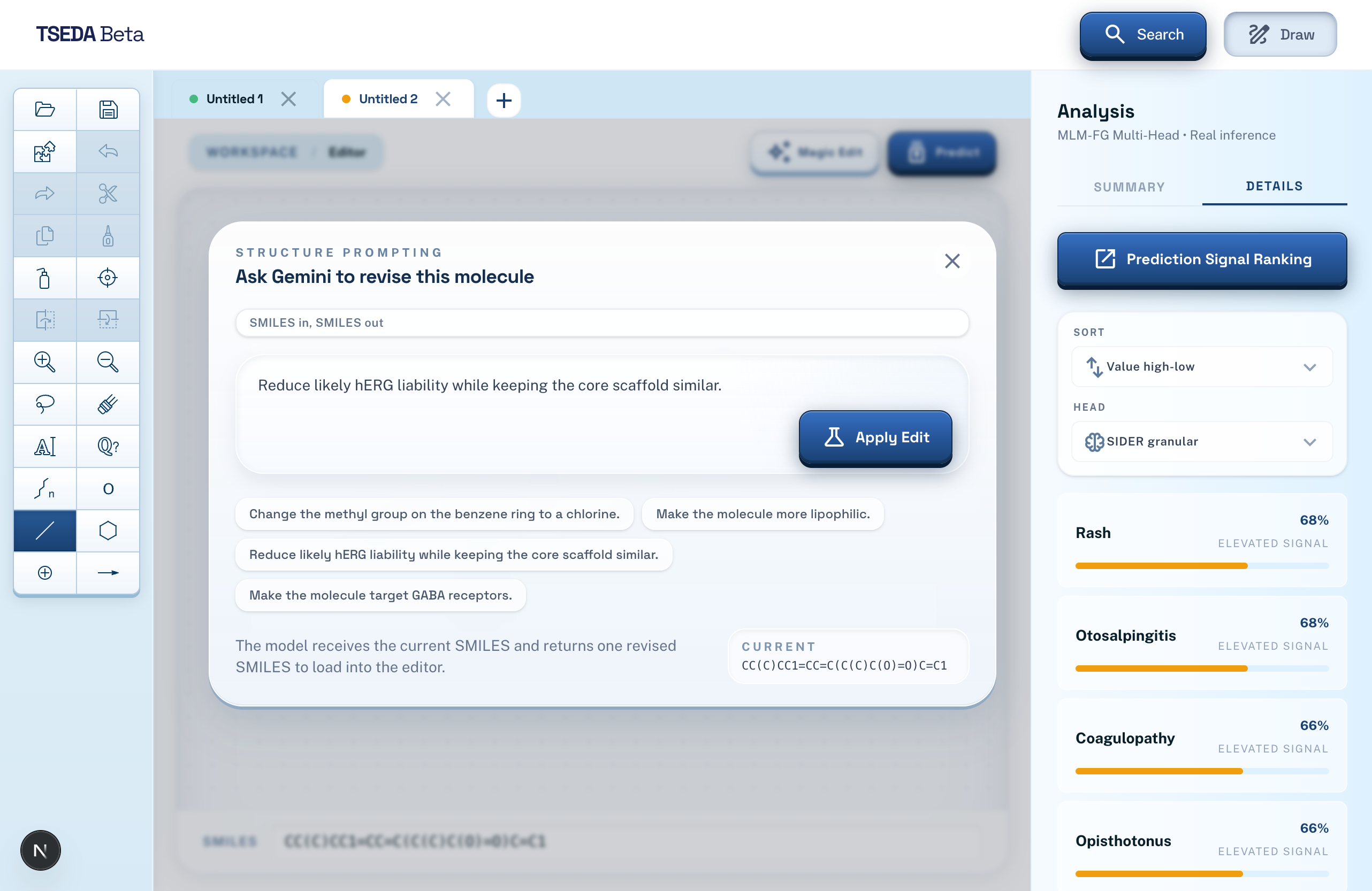
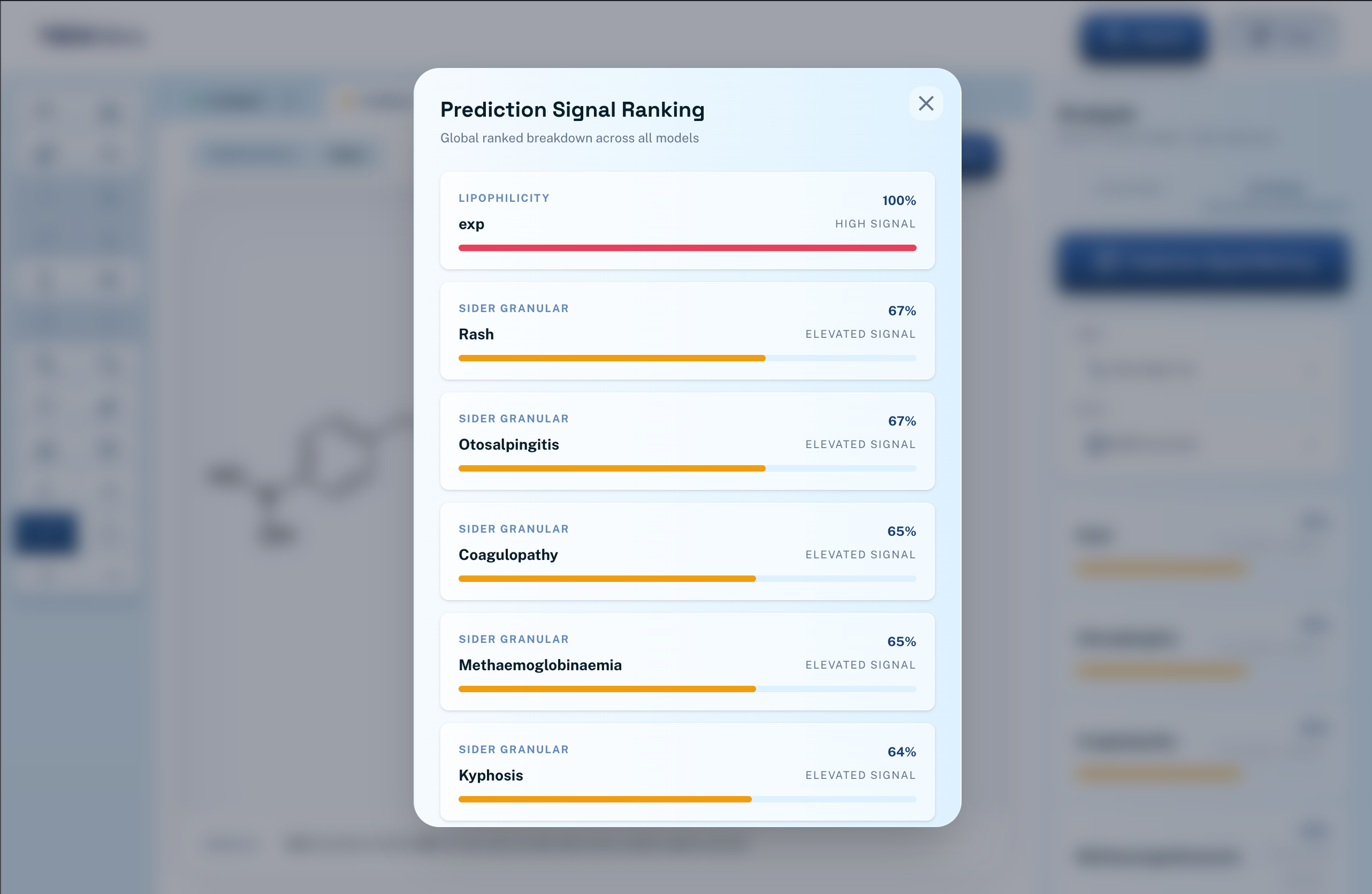
Indicators
Inspiration
A single drug (yes, just one) can cost billions of dollars and decades to bring to market. More than 1/3 of resources are allocated to preclinical trials: a long, repetitive process. Designing and synthesizing compounds are extremely time-consuming, and there is no guarantee that a given drug candidate is useful. Recent innovations in AI have revolutionized almost every industry, and we want to explore its potential for expediting the pre-clinical drug discovery process.
What it does
There are two main features. The first allows the user to describe a chemical/drug/disease that they want to focus on. A language model will evaluate this, and generate potential candidates that are similar to the compound or treat a specific disease. These candidates are all unknown/unpublished compounds, and the user will be given information about what it is, how to synthesize it, and the ability to edit it manually further. The second feature evaluates the potential of a compound (either generated or manually drawn through the ChemDoodle canvas), using a fine-tuned ML model (MLM-FG) to predict its features, risks, and potential effects on humans.
How we built it
We utilized existing libraries, APIs, and machine learning models. Anthropic API powers the generation of new compounds, and Google Gemini assists in drafting compounds when prompted. ChemDoodle allows the user to draw chemical models, import MOL files, etc. for evaluation. MLM-FG evaluates candidates for risk signals. The app is built on React, Next.js, and Tailwind. We used a variety of tools, like Google Stitch for UI design, Codex/Gemini/Claude for coding support, Claude Code for agentic training of the ML model.
Challenges we ran into
Some challenges we ran into were the models not working as we expected or planned. For example, we initially planned to use the ChemBERTA ML model. However, that model did not directly give the indicators that we needed, and we would've had to layer it with another custom classification layer after training. Instead, we were able to find a pre-training method, MLM-FG to provide us with the indicators. There were also various challenges with the implementation of existing libraries into our code - ChemDoodle's mouse event handler was overlapping with other systems, and did not trigger properly for a long time until we figured it out.
Accomplishments that we're proud of
We are most proud of our UI design, which underwent multiple iterations and reviews from all team members. It is something that we had in mind since the very start, and we just constantly tried to improve upon it. Another accomplishment we are proud of is getting everything done in a cohesive manner, as many of us have never done anything complex regarding ML if at all.
What we learned
We learned a lot about how to work together in the age of AI, where changes happen very quickly and are hard to track. Good communication ensured that we always knew what had happened if something had gone wrong, and we could investigate at the site of incidence or revert without delaying.
What's next for Tseda
The next step for Tseda is to train the model and fine tune it well, as due to time and compute constraints of the hackathon we are not able to have the most accurate inference. Additionally, generation occurs fairly slow (again due to compute mainly), but we have ideas to implement things like caching, optimizing prompts or using specialized models for generation. Further down the line, we plan to build automated workflows that integrate with current drug discovery technologies to better support researchers.
Built With
- chemberta
- chemdoodle
- claude
- gemini
- mlm-fg
- next.js
- python
- react
- stitch
- typescript









Log in or sign up for Devpost to join the conversation.