-
-
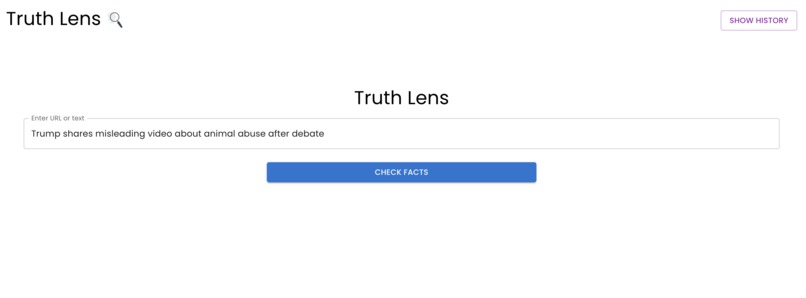
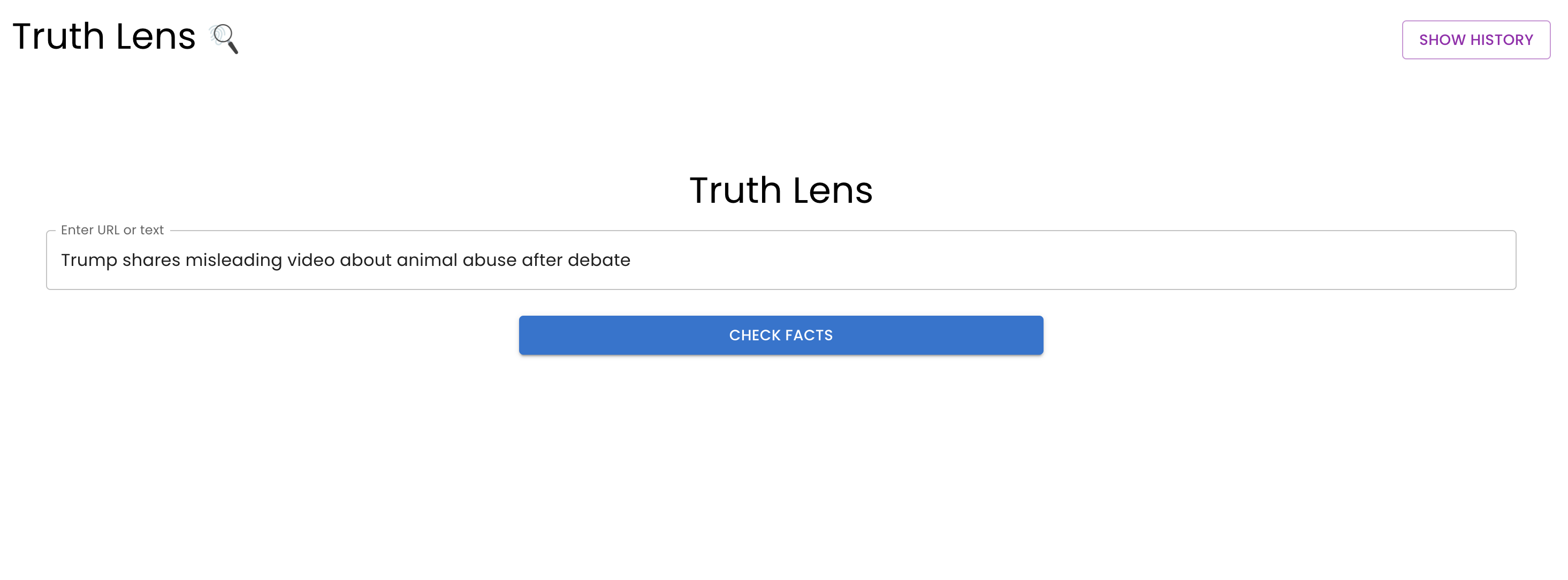
our web app at work verifying facts
-

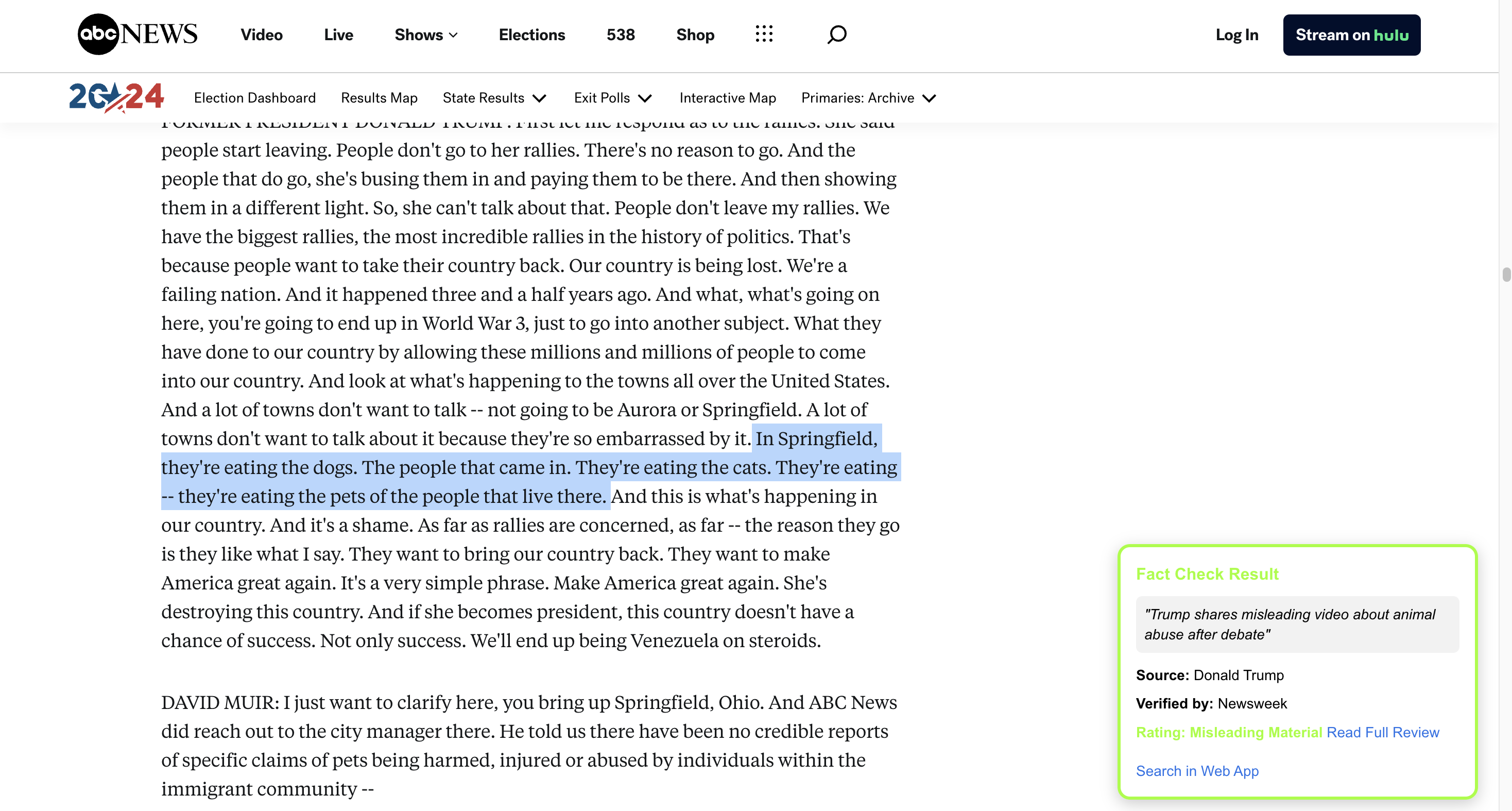
our chrome extension at work on a news article
-
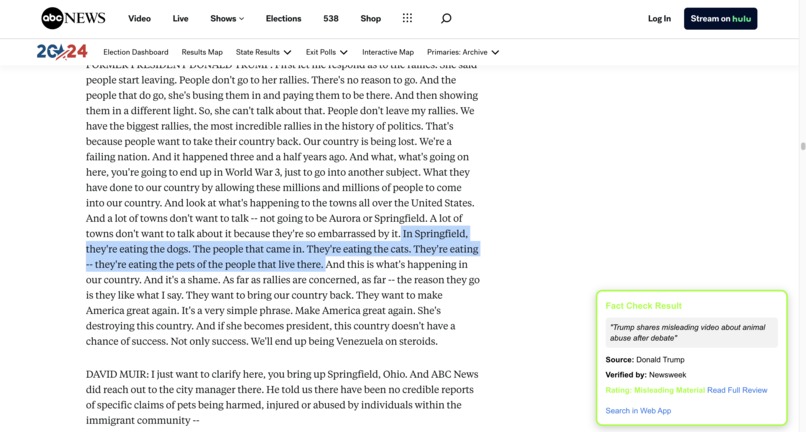
our chrome extension at work on a news article
-
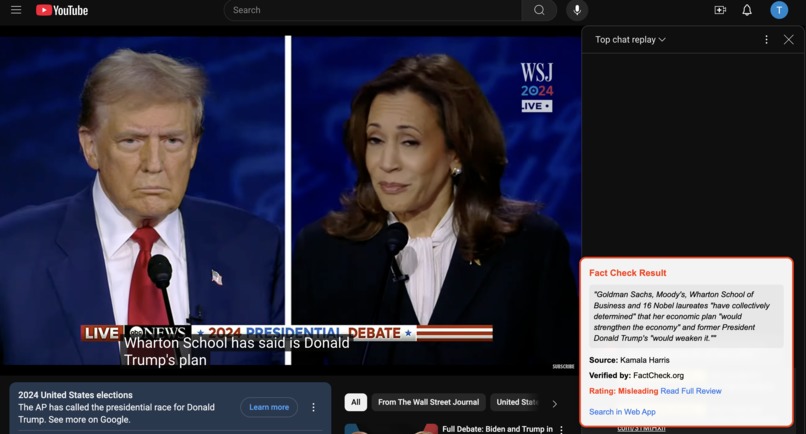
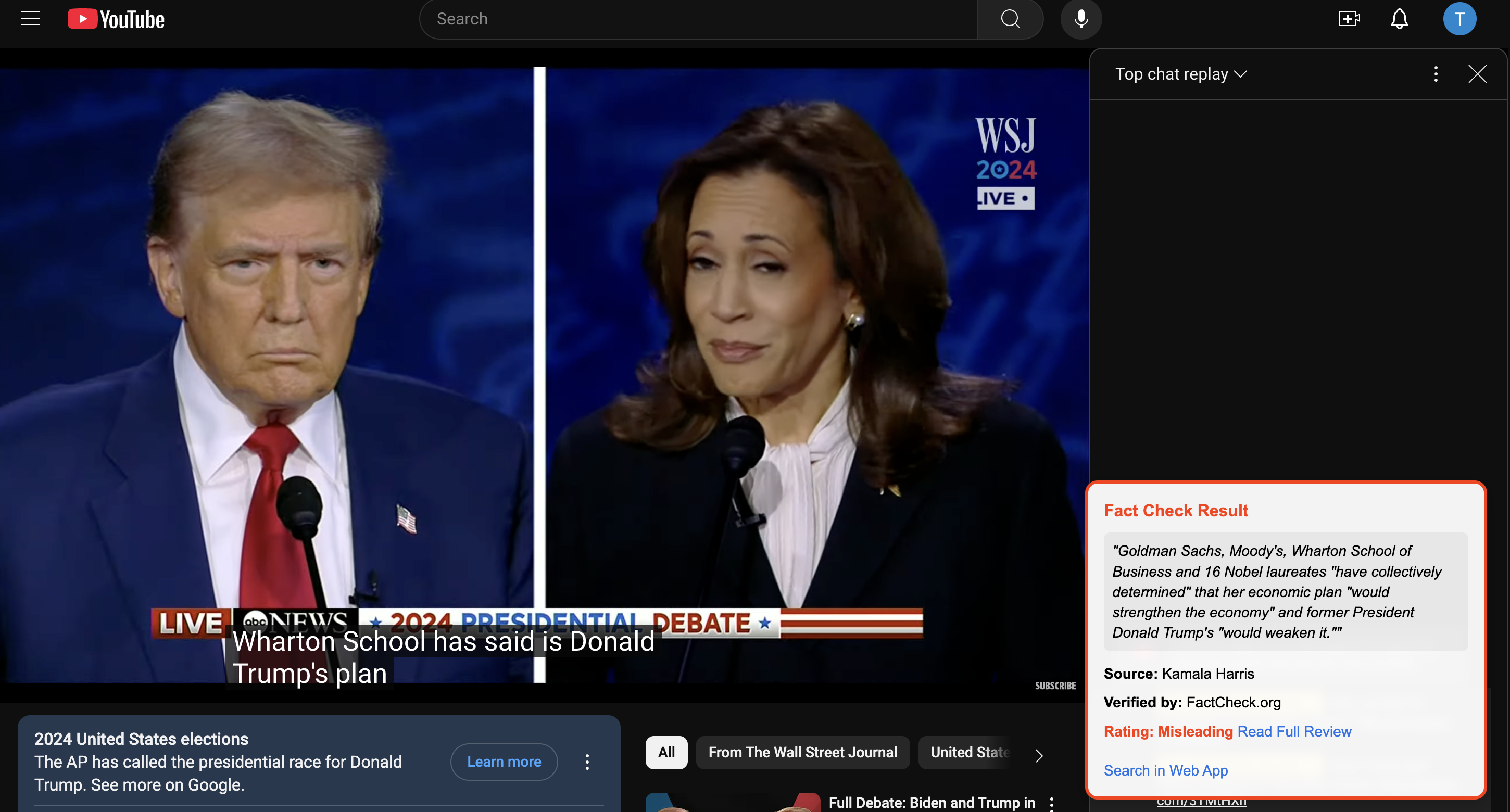
our chrome extension at work on a youtube video
-

Inspiration 🌐
With the rise of misinformation online, it’s challenging to verify claims quickly. We wanted a tool that empowers users to fact-check content on YouTube and blogs in real-time, promoting digital literacy and accountability.
What it does ✅
TruthLens is a fact-checking browser extension, built with the intention of convenience. While reading a blog or watching a YT video, if you're confused about something, why go through the added headache of researching and fact checking a claim? Instead, users can highlight claims within videos or articles, and TruthLens checks the accuracy by searching reliable sources. It outputs a true/false score and provides related references, giving users verified information within seconds.
How we built it 🛠️
Our components were built using the following technologies:
- Front-end: Web-app/Browser extension
- JavaScript
- React
- Tailwind
- Material UI
- Back-end:
- Server: Flask that hosts multiple APIs (Python)
- Model:
- LLMs (Mistral via OLlama)
- RAG
- In-Context Learning
- Few-shot prompting
- External sources queried:
- Google FactCheckAPI
- ClaimBuster FactChecker
- DuckDuckGo API for web scraping
- YouTube API (for captions and video data)
- Deployment
- Deployed to .tech domain, hosting our web app for public use
- Docker containers are used to package the backend, making it portable and scalable across different environments.
- GitHub Actions automates testing, deployment, and continuous integration.
We developed fact-checking APIs hosted on a backend server that queries this LLMs and RAG model, and directed the result of our model to the front-end. We built a browser extension frontend, that communicates with fact-checking APIs, and our model to fetch verified information. The extension monitors selected text and video captions, processing content in real-time to support fact verification.
Challenges we ran into ⚠️
Understanding how to use LLMs and RAG methods to perform FactChecking. We read a lot of research papers to understand which methods performed well, and which don't. In building the app, synchronizing live captions for accurate fact-checking was complex, as was managing real-time data requests to avoid delays. Handling various content formats (text, video captions, social media) and optimizing API response speed were significant hurdles.
Accomplishments that we're proud of 🏆
Creating a seamless fact-checking experience that works across multiple platforms feels like a big win! Even though this started out as a possibility, the fact that this app works on both youtube videos and blogs is a proud feat. The ability to verify information with a single click empowers users to make informed decisions. Building a functional prototype that effectively filters misinformation is a huge accomplishment.
What we learned 📚
We gained insights into natural language processing, managing asynchronous data requests, and creating a responsive, user-friendly UI. We also learned about real-time data processing challenges and the intricacies of integrating with fact-checking APIs.
What's next for TruthLens 🚀
- Extending to multiple platforms: We want to extend to instagram reels and tiktok videos. Since these sources contain a lot of misleading information, it would be very helpful to identify "factually-correct" influencers, so that people can decide who to follow.
- We plan to use an enhanced method to identify claims within transcripts, so that we intelligently check for factuality. Our goal is to bring TruthLens to mobile and any source of information (blogs, reviews, twitter, reddit, etc), making fact-checking accessible anytime, anywhere.
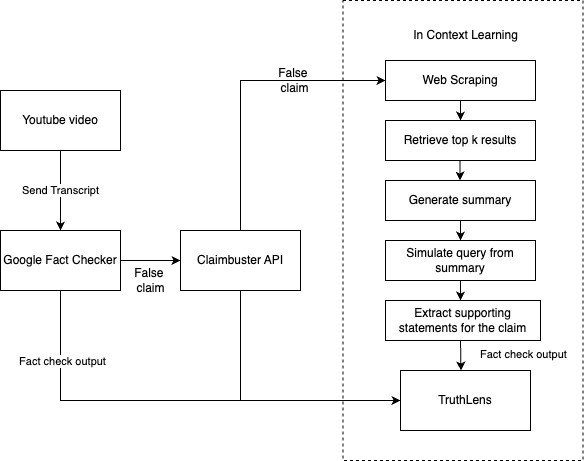
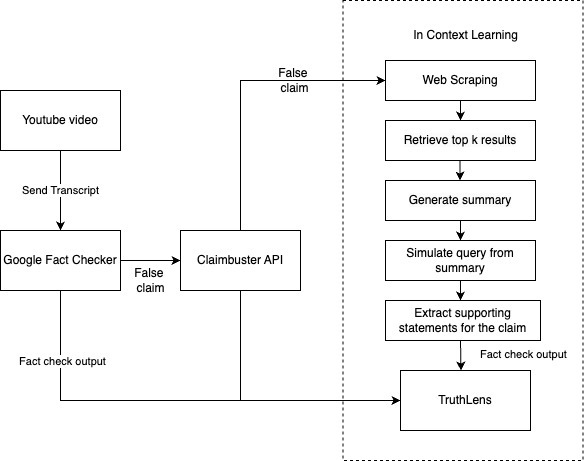
End-to-End Flow of our Model 🛠️
TruthLens follows a modular architecture, focusing on separation between the frontend, backend, and the AI/ML component. Step 1: Claim Submission: A claim is submitted via the frontend (either user selects a statement from a blog, or inputs his own statement, or claim-checked from a youtube video).
Step 2: Web Crawling: The backend crawls the web to gather relevant information. We fetch up to 5 documents that might contain valuable context regarding the claim.
Step 3: Extract relevant details from the documents: The retrieved documents are then analyzed to extract the most pertinent details related to the claim.
Step 4: Question Generation: Questions are automatically generated based on the summarized content to better understand the context and verify the claim, via In-Context Learning, by prompting Mistral-7B model.
Step 5: Information Extraction: The system analyzes the documents, identifying sections from the documents that may provide answers to the generated questions.
Step 6: Refutation/Acceptance: Using both Google Fact Checker, ClaimBuster API and the Ollama model, the backend evaluates the claim against the gathered and processed data, and then returns whether the claim is true or false.
Features ⚡
Real-Time Fact-Checking: Highlight claims in videos, articles, or social media content, and get an instant true/false score based on reliable sources. Cross-Platform Support: Works across YouTube, TikTok, Instagram Reels, and blogs. References: Provides users with a list of credible sources supporting the fact-checking result. Easy-to-Use UI: Users can simply highlight claims and click to get verified information. Language Translation: Future plans to support multi-language fact-checking.
Built With
- css3
- javascript
- llm
- material-ui
- python
- react
- tailwind




Log in or sign up for Devpost to join the conversation.