-
-
Landing Page
-

Loading Page
-

Constellation
-
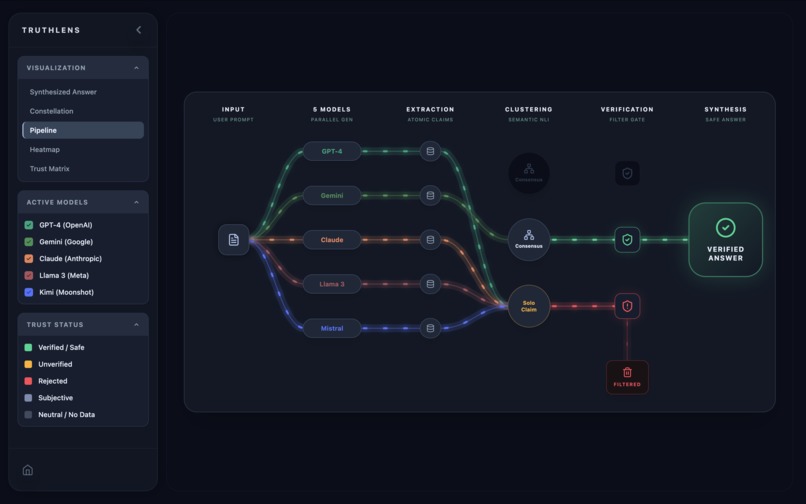
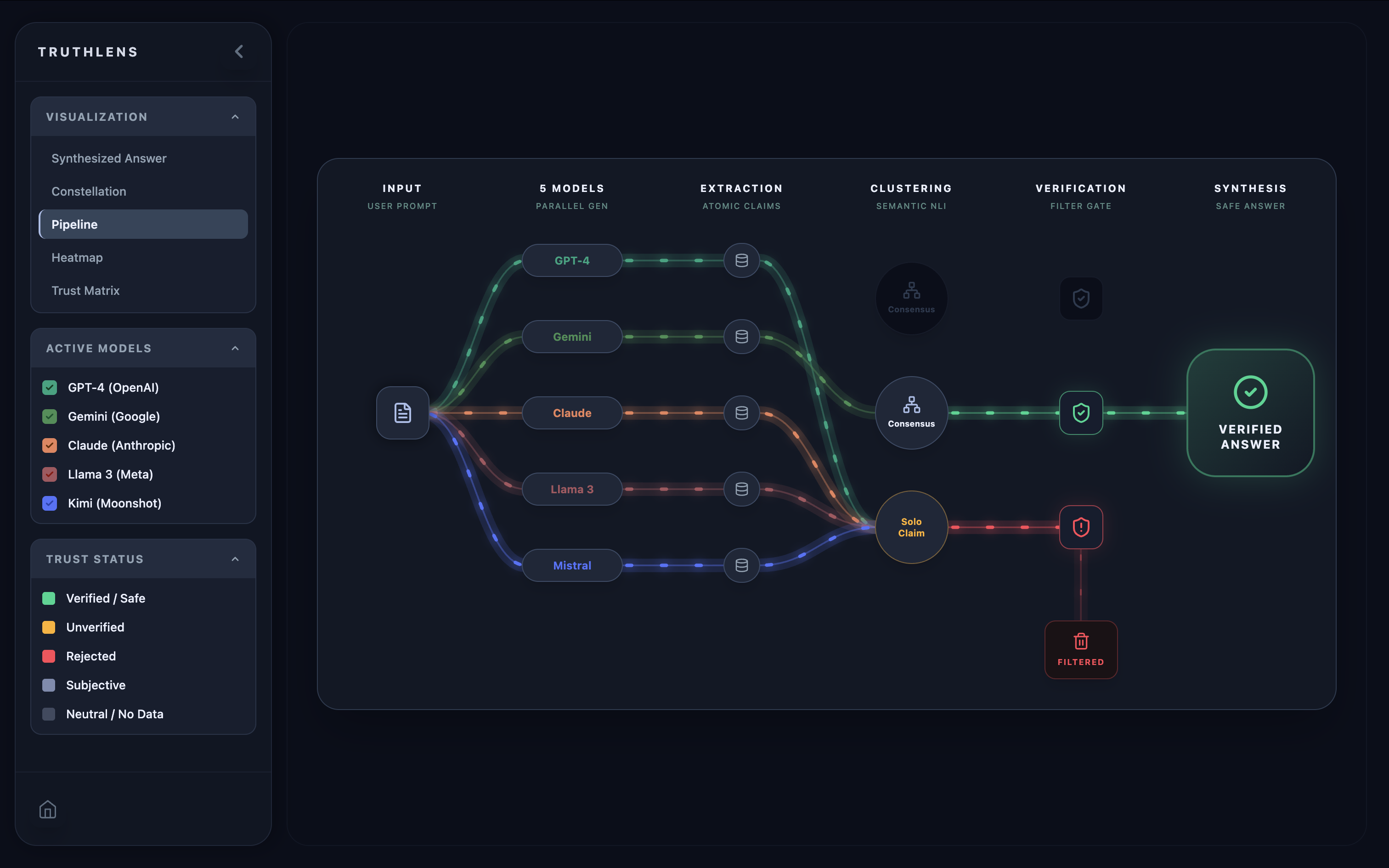
Pipeline


Inspiration
We've all asked AI a question and gotten a confident answer and just... believed it. The problem isn't that AI models lie, it's that they sound confident no matter right or wrong. A single model cannot assess the trustworthiness of its own answer. So, instead of asking 1 model, we asked 5 simultaneously.
What It Does
TruthLens is an AI Trust Intelligence Platform. Enter a question or article and get: Multi-Model Consensus Analysis: Five LLMs (GPT-4, Gemini, Claude, Llama 3, and Kimi) respond simultaneously. Every response is decomposed into atomic claims, clustered by semantic meaning, and scored on 3 axes: agreement, evidence verification, and model independence. Trust Scoring: Each claim receives a composite score, which is then labeled as Verified, Unverified, Rejected, Subjective, or Neutral. Safe Answer Synthesis: The final answer is built from cluster verdicts/scores produced by the scoring stage 3 Visualization Modes:
- Claim Constellation (3D): Claims plotted in 3D space via UMAP Projection.
- Pipeline Flow: A left-to-right diagram showing claims flowing through extraction, clustering, verification, and synthesis.
- Trust Matrix: A 2D scatter plot mapping Model Consensus vs. Verification Confidence, with glowing nodes and visual "Danger" and "Safe" zones.
How We Built It
- (Frontend) Designed UI in Figma and built the frontend to handle real-time visualizations, including mapping the high-dimensional claim embeddings into 3D space using UMAP.
- (Backend) Built a proxy server in FastAPI to manage orchestration. It starts the Modal pipeline and uses WebSockets to stream live analysis stages back to the client in real-time.
- (ML) Deployed machine-learning workloads on Modal's serverless GPUs, using GPT-4o-mini to extract atomic claims from structured outputs of 5 different LLMs. We then embedded those claims using bge-large-en, clustering them semantically.
- (Verification) Used DeBERTa-v3, a Natural Language Inference (NLI) model, to mathematically score whether the claims were correct.
Challenges We Ran Into
- Getting 5 different models to work correctly was a major hurdle. We had to build an extraction layer to force their outputs into deterministic, atomic claims before they could be graded
- Gap Between 3D Map and UI Layout was a large challenge due to having to make calculations to determine what orbs go where and how to scale. Also had to ensure that the visual wouldn't lag.
Accomplishments That We're Proud Of
- Creating the pipeline (React -> FastAPI Orchestrator -> Concurrent APIs -> Serverless GPUs using Modal for heavy ML extraction and NLI scoring)
- Built an actual mathematical heuristic for trust scoring, independently weighing multi-model consensus against hard textual entailment from live web data
What We Learned
Data visualization is certainly... hard! But visualization is the product; showing data matters as much as the data itself. It's the central design constraint that shapes every technical choice made throughout this project. Trust requires independence, meaning it's not enough for multiple models to say the same thing, but it's better to know whether or not they said it independently.
What's Next for TRUTHLens
more visualizations!!! knowledge deck & evidence mapping
Github Repo: https://github.com/willhatfield/truth-lens


Log in or sign up for Devpost to join the conversation.