-
-
HomePage
-
AboutPage
-
OpenSourcePage
-
TermsAndConditionPage
-
PrivacyPolicyPage
-
ContactPage
-
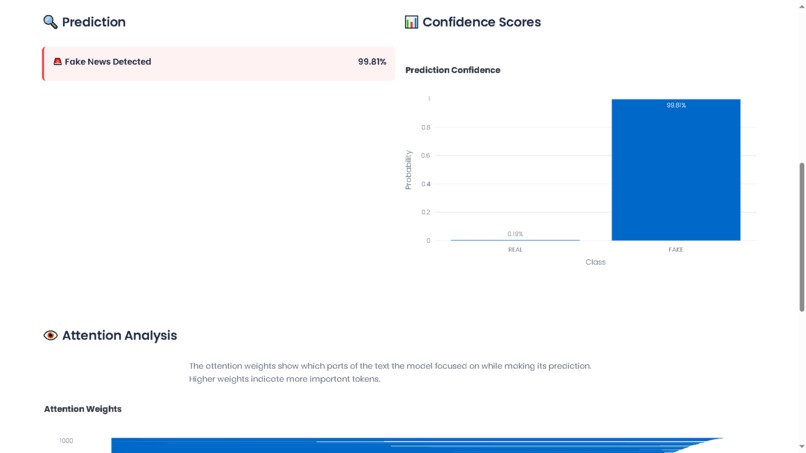
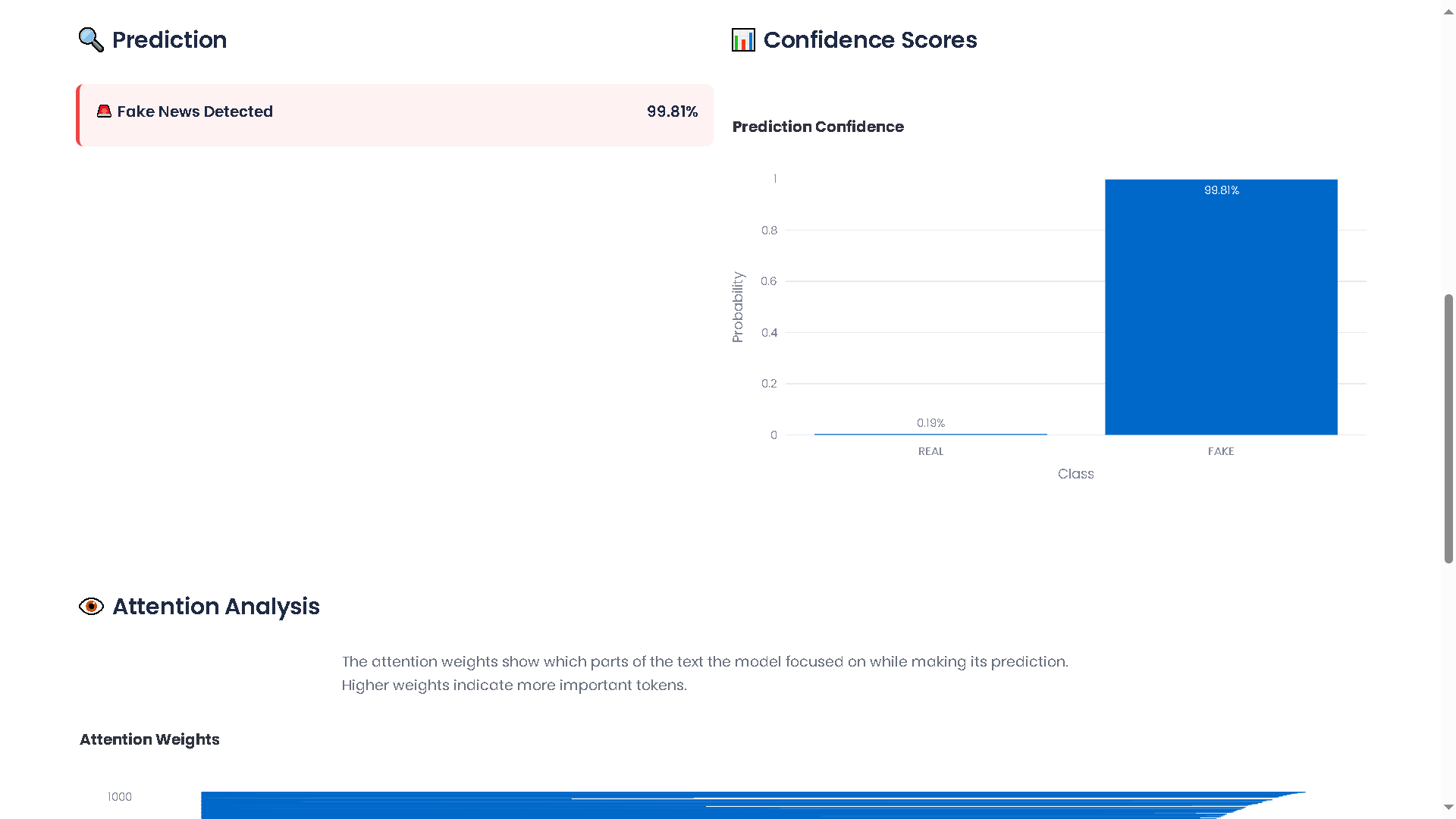
FakeNewsDetection
-
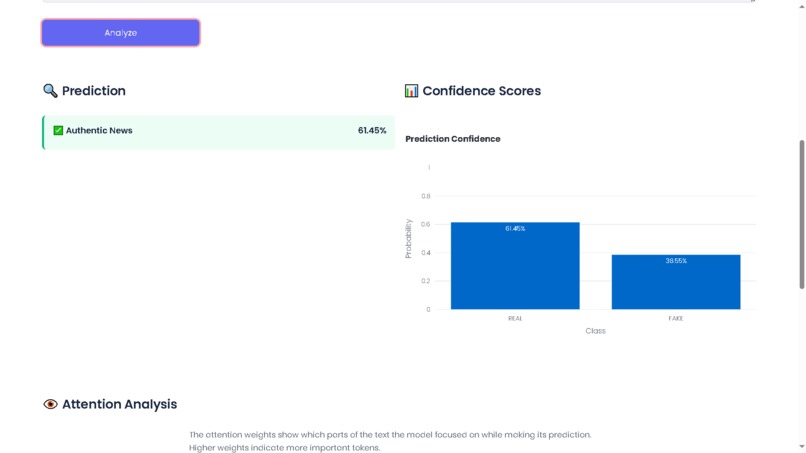
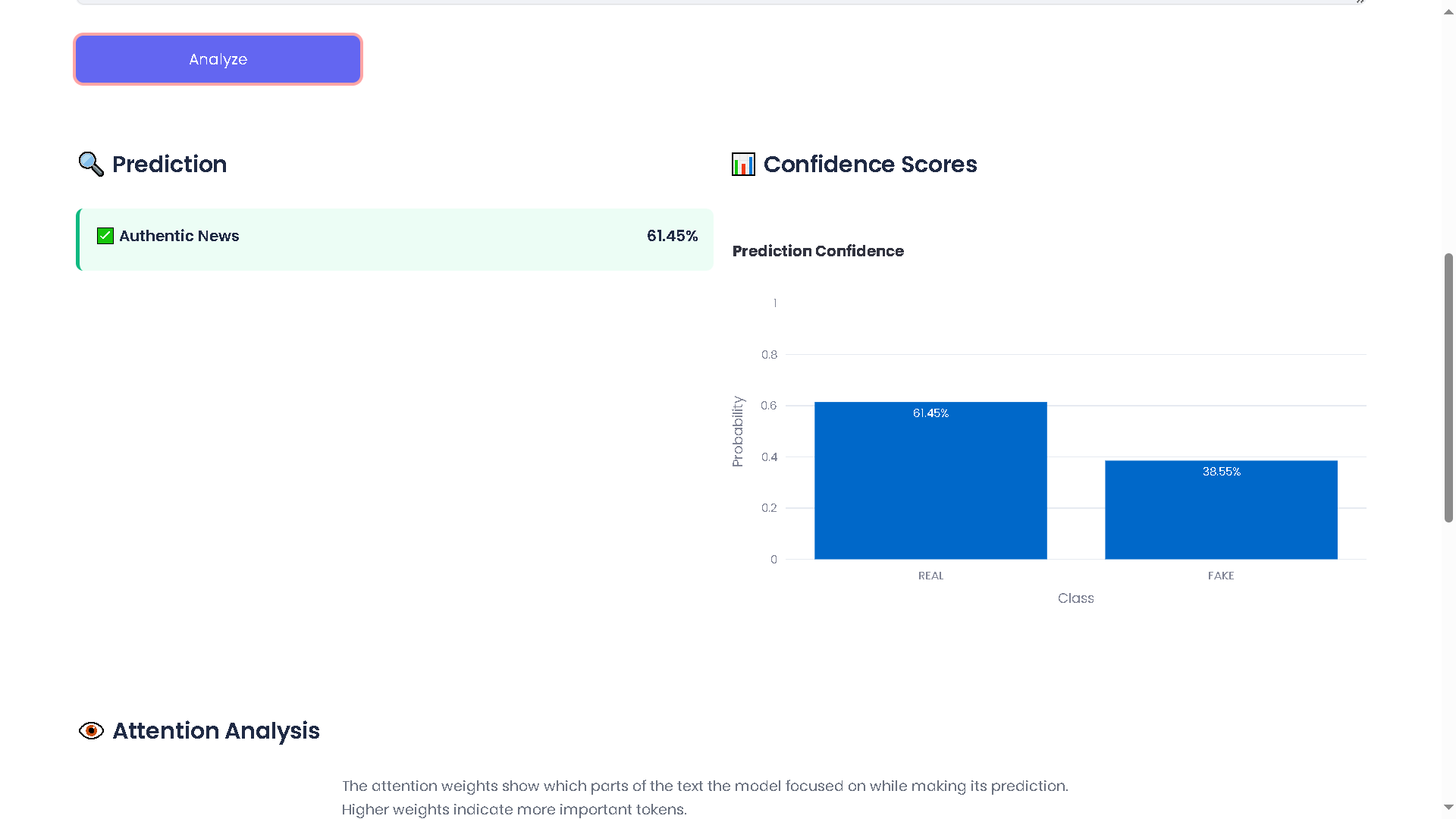
AuthenticNews
Inspiration
The rise of misinformation and fake news has become a global challenge, impacting societies, democracies, and individual lives. Inspired by the need for trustworthy information and the power of open-source AI, we set out to build TruthCheck—a transparent, reproducible, and community-driven solution for fake news detection.
What We Learned
- Natural Language Processing (NLP): We deepened our understanding of transformer models, especially BERT, and how transfer learning can be leveraged for text classification tasks.
- Open Source Best Practices: We learned the importance of clear documentation, reproducibility, and proper crediting of datasets and code.
- Deployment: We gained hands-on experience deploying machine learning models as interactive web apps using Streamlit and Hugging Face Spaces.
- Collaboration: Working as a team, we improved our skills in version control, code review, and collaborative problem-solving.
How We Built It
- Data: We combined two open datasets: the Kaggle Fake and Real News Dataset and the LIAR dataset, preprocessing and merging them for robust training.
- Model: We used the pre-trained BERT-base-uncased model as our foundation, adding a BiLSTM and attention layer for enhanced context and interpretability. All layers were fine-tuned on our dataset.
- Training: The model was trained using PyTorch, with careful attention to validation, early stopping, and metric tracking (accuracy, precision, recall, F1).
- Web App: We built an interactive Streamlit app, allowing users to paste news articles and instantly receive a fake/real prediction, with a clean and user-friendly UI.
- Open Source: All code, training scripts, and deployment instructions are open and available in our GitHub repository.
Challenges We Faced
- Data Quality & Balance: Merging datasets with different formats and label distributions required careful preprocessing and validation.
- Model Size & Deployment: Handling large model files and ensuring smooth deployment on resource-limited platforms like Streamlit Cloud and Hugging Face Spaces.
- Dependency Management: Ensuring all dependencies were compatible and could be installed in cloud environments without compilation errors.
- Reproducibility: Making sure every step—from data download to model inference—could be reproduced by anyone, anywhere.
Math & Model
We leveraged the power of transfer learning, where a pre-trained model ( f_{\text{BERT}}(x; \theta) ) is fine-tuned on our dataset:
[ \text{Prediction} = \text{Softmax}(\text{Attention}(\text{BiLSTM}(f_{\text{BERT}}(x; \theta)))) ]
where ( x ) is the input text and ( \theta ) are the BERT parameters, all of which are updated during training.
TruthCheck is our contribution to the fight against misinformation—open, transparent, and built for the community.










Log in or sign up for Devpost to join the conversation.