-
-
Front Page
-
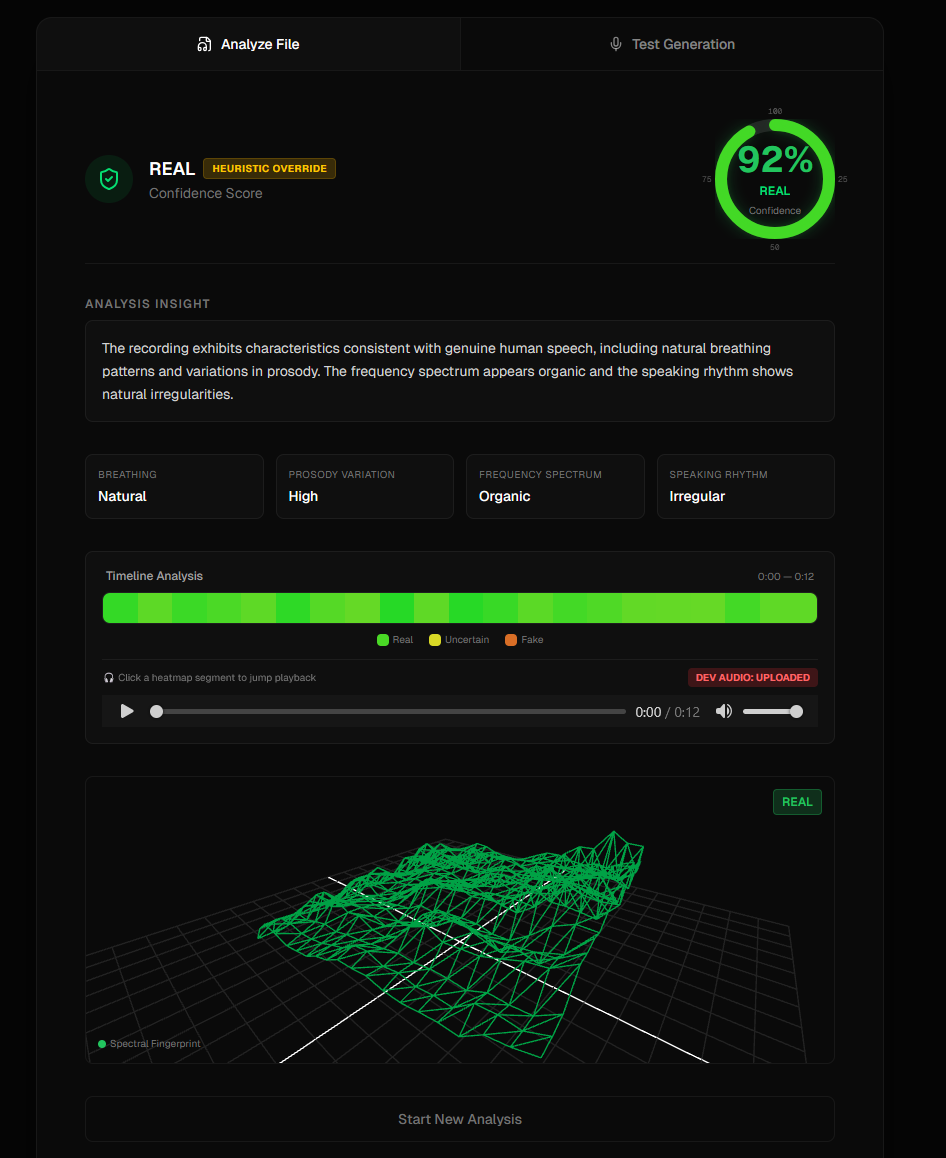
Human Audio
-
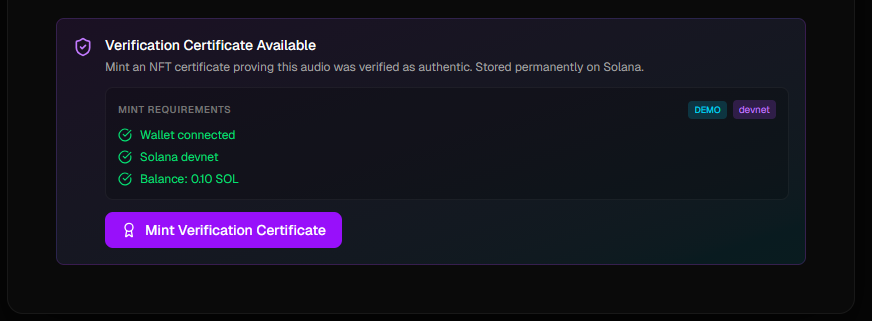
Minting
-
Minting Confirmed
-
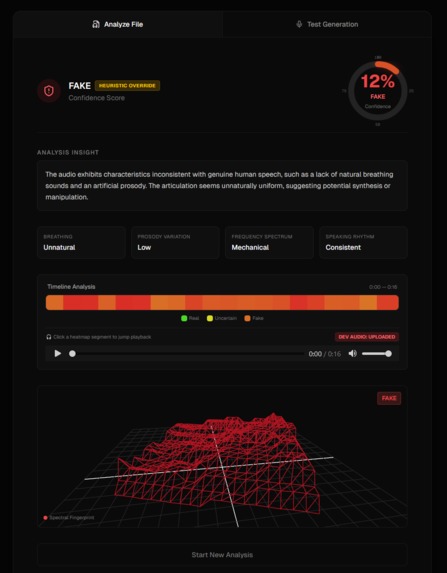
AI Audio
-

Minting Not Available
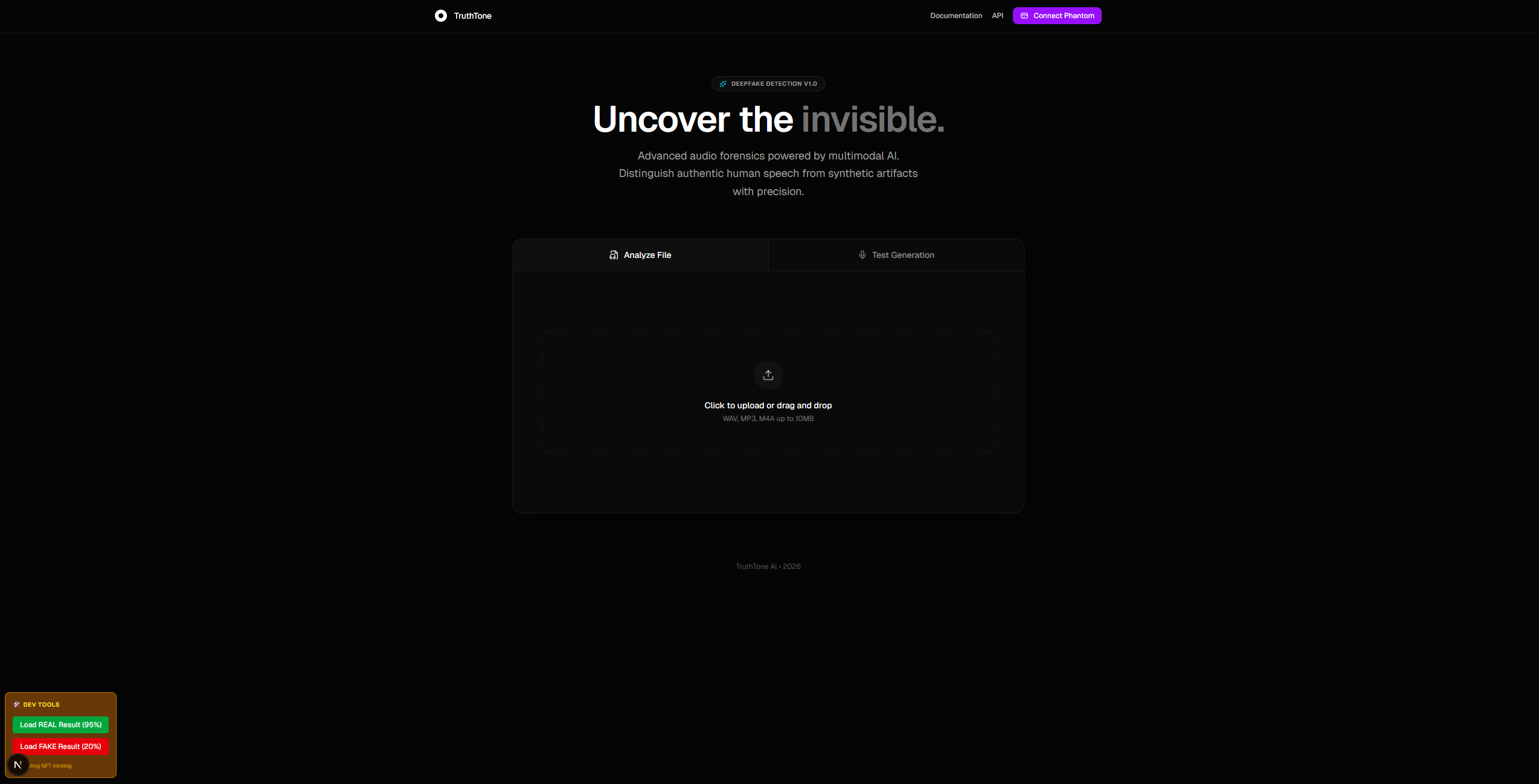

Inspiration
We were scrolling through TikTok when we saw yet another "celebrity" saying something wild - except it wasn't them. It was a deepfake. And honestly? We couldn't tell at first.
That moment hit different. With upcoming elections, AI voice cloning getting scary good (we're looking at you, ElevenLabs), and scammers stealing millions with fake CEO voices, we realized nobody knows what's real anymore.
So we asked ourselves - what if we could see the difference? Not just detect it, but actually visualize what makes AI voices different from real human speech? What if we made the invisible visible?
That's how TruthTone++ was born. We wanted to build something that doesn't just say "this is fake" but shows you why, in a way that's actually beautiful to look at.
What it does
TruthTone++ is a deepfake audio detector that makes you go "whoa, I can actually see the difference."
Here's the flow:
- Upload or record any audio clip (a voice message, political speech, podcast snippet - whatever)
- Our AI analyzes it using Gemini to detect deepfake patterns that human ears can't catch
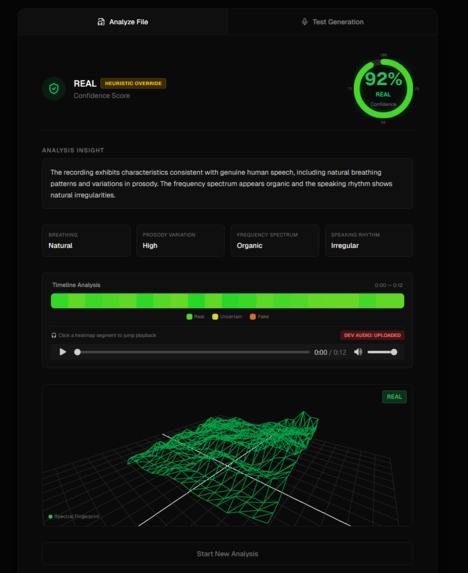
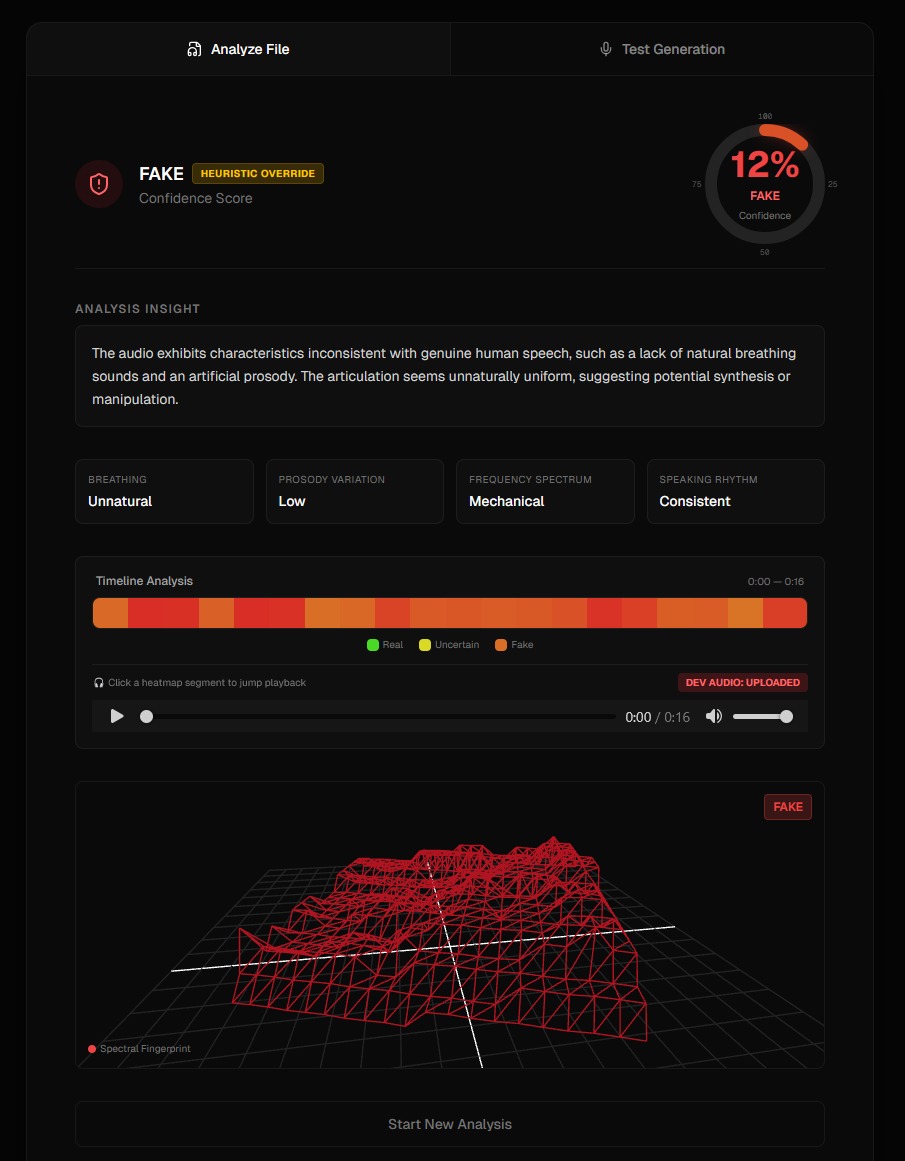
- You get a 3D audio fingerprint visualization - real human voices look organic and chaotic, AI voices look weirdly perfect and geometric
- We show you a timeline heatmap highlighting exactly when suspicious stuff happens in the audio
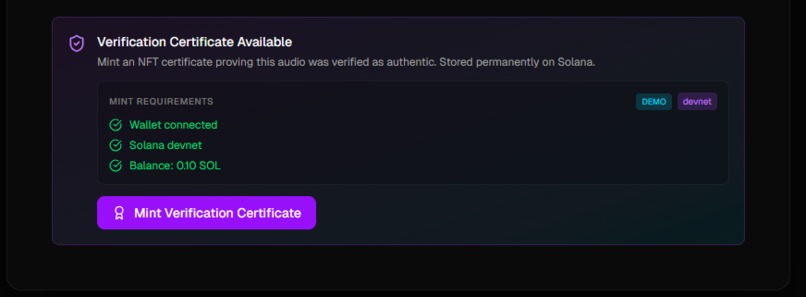
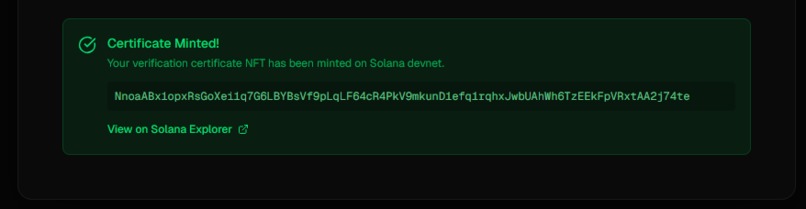
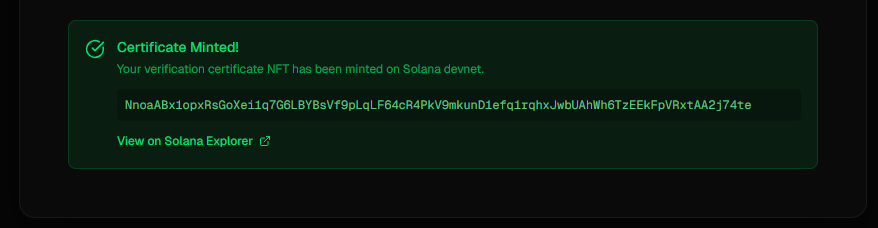
- Want proof? We can mint a verification certificate as an NFT on Solana - permanent, immutable proof that this audio was verified as real
But here's the coolest part for the demo: we can record your voice, use ElevenLabs to clone it in real-time, then show you both side-by-side with the visualizations. Watching someone see their own voice cloned and then comparing the patterns is kind of mind-blowing.
How we built it
We split into three people tackling different parts:
Backend (FastAPI + AI) We built a Python FastAPI server that does the heavy lifting. When audio comes in, we use librosa to extract features like MFCC and spectral characteristics - basically turning sound into numbers. Then we send those features plus the raw audio to Gemini with a carefully crafted prompt that asks it to analyze breathing patterns, prosody consistency, and frequency artifacts. For the comparison demo, we integrated ElevenLabs to generate deepfakes on demand.
Frontend (Next.js + Solana) The web app is built with Next.js 14, TypeScript, and Tailwind. We created an audio upload interface with drag-and-drop, a live recording mode using the Web Audio API, and connected everything to our FastAPI backend through Next.js API routes. For the blockchain piece, we used Solana's web3.js library and Metaplex to mint verification NFTs when audio passes our authenticity threshold.
Visualizations (Three.js + Chart.js) This is where things got fun. We used React Three Fiber to create 3D meshes from audio frequency data. Real audio creates irregular, organic shapes because human speech has natural variation. AI-generated audio produces these eerily symmetrical patterns. We also built a Chart.js timeline that color-codes confidence scores throughout the audio (green for real, red for suspicious).
The whole thing is deployed on Vercel with the FastAPI backend running separately.
Challenges we ran into
Getting Gemini to be consistent At first, Gemini would give us different answers for the same audio file. We had to iterate on our prompts like crazy, adding specific examples and structured output requirements. We probably went through 20+ prompt versions before it became reliable.
3D visualization performance Rendering complex 3D meshes in the browser can tank performance fast. We had to optimize the mesh resolution, implement lazy loading, and use React Three Fiber's performance helpers to keep it smooth. Still drops frames on older laptops though.
Real-time voice cloning speed ElevenLabs is amazing but it's not instant. Getting the cloning + generation pipeline down to under 20 seconds for the demo required caching voice profiles and pre-warming the API connection. We were worried it would be too slow for a live demo.
Solana devnet being temperamental Turns out devnet goes down sometimes or gets super slow. We had to add retry logic and fallback error messages. During testing, we lost like 30 minutes to a devnet outage and thought our code was broken.
Audio format compatibility People upload MP3s, WAVs, M4As, OGGs - everything. We needed FFmpeg bindings to convert everything to a standard format before analysis. Getting this working cross-platform was annoying.
Accomplishments that we're proud of
The visualization actually works We weren't sure if the 3D fingerprint idea would even be noticeable, but when you put a real voice next to an AI voice, the difference is striking. Real voices are messy and beautiful. AI voices are too clean. You can just see it.
Live demo mode We built a streamlined demo flow specifically for showing judges. Record voice, generate clone, compare both - all in under 60 seconds. It actually worked during practice runs without crashing.
Blockchain integration that makes sense A lot of hackathon blockchain projects feel forced. Ours actually solves a problem - how do you prove audio was verified at a specific point in time? NFTs are perfect for this because they're immutable and timestamped.
Clean API architecture The FastAPI backend has a clean contract that could easily plug in a custom-trained model later. We built it modular so the ML piece could be swapped out.
It works end-to-end Upload audio, get analysis, see visualizations, mint NFT. The whole pipeline actually functions. No smoke and mirrors, no "this button doesn't work yet" disclaimers.
What we learned
AI APIs are powerful but unpredictable Working with Gemini taught us that LLMs are incredible tools but you need really good prompt engineering and error handling. One poorly worded prompt and your results are garbage.
Audio processing is harder than it looks We thought "just extract some frequencies" would be easy. Nope. Audio sampling rates, bit depths, channel mixing, normalization - there's so much that can go wrong. Librosa saved our lives.
Blockchain UX is still rough Even with wallet adapters, asking users to connect Phantom, approve transactions, and understand gas fees is a hurdle. We need better abstractions.
Visualizations sell ideas We could have just shown a confidence percentage, but the 3D fingerprint makes people actually understand what we're doing. Good visuals make complex ideas click instantly.
Demo-driven development works We optimized for "what will look coolest in a 3-minute demo" and that forced us to focus on the features that actually matter. No feature creep.
What's next for TruthTone++
Train a custom model Right now we're using Gemini which is great, but we want to train a specialized model on the ASVspoof dataset. Could get better accuracy and faster inference.
Real-time detection Imagine this running live during a phone call or video chat. "Warning: the person speaking may not be who they claim." Browser extension maybe?
Multi-modal analysis Add video deepfake detection. Analyze lip-sync, facial micro-expressions, lighting consistency. Combine audio and video scores for higher accuracy.
API for developers Build a public API so journalists, fact-checkers, and platforms can integrate TruthTone++ into their workflows. Verified checkmark for real audio.
Mobile app Record audio on your phone, get instant verification. Perfect for journalists in the field or anyone getting suspicious voice calls.
Decentralized verification network Instead of trusting just our analysis, create a network where multiple independent nodes verify audio and reach consensus. More reliable, harder to game.
Education mode Show people how deepfakes work by letting them create their own (ethically) and see exactly what artifacts appear. Learn to spot fakes yourself.
The core problem isn't going away - AI voice cloning will only get better. We need tools like TruthTone++ to keep up. This hackathon project is just the start.
Built With
- chart.js
- elevenlabs-api
- fastapi
- google-gemini-api
- librosa
- metaplex
- next.js
- python
- react
- react-three-fiber
- solana
- tailwind-css
- three.js
- typescript
- vercel






Log in or sign up for Devpost to join the conversation.