-
-
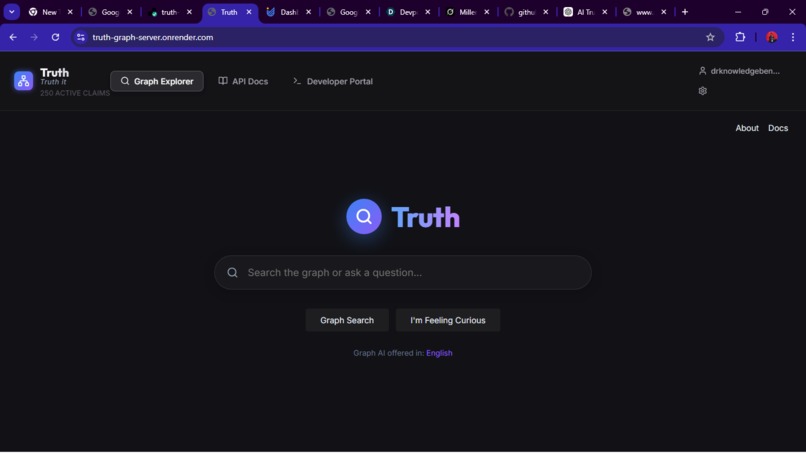
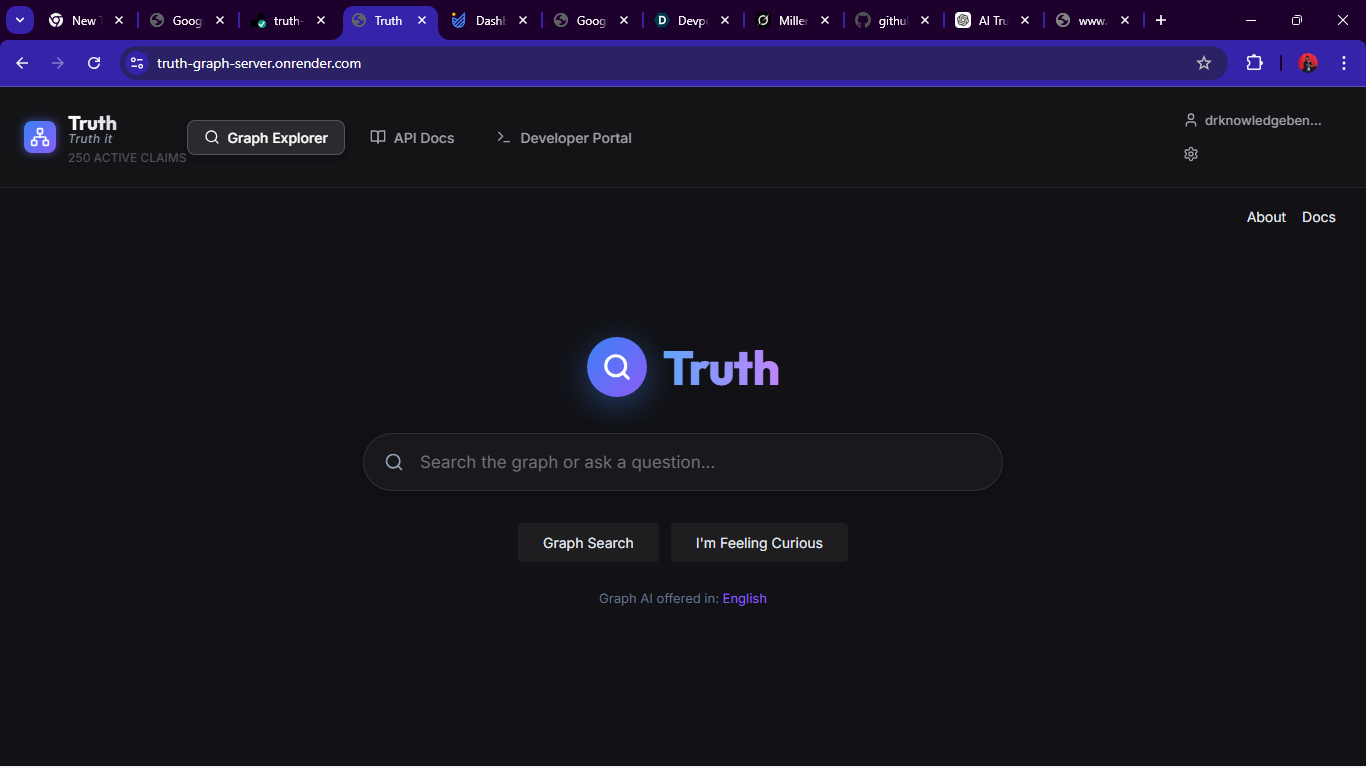
The landing Interface of the graph Frontend
-
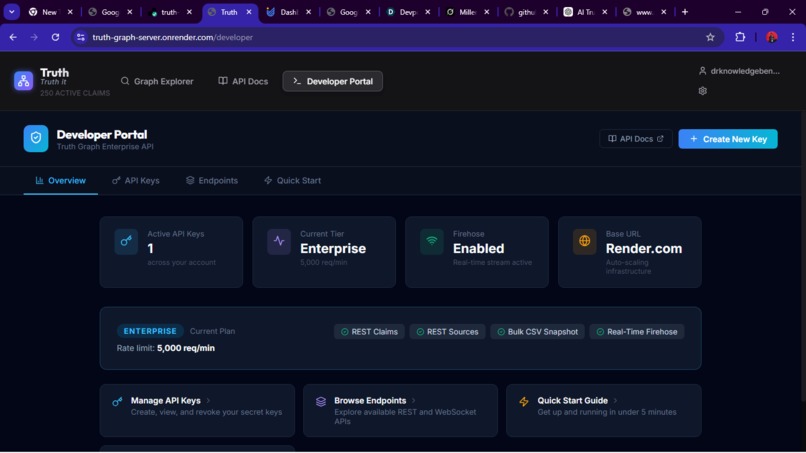
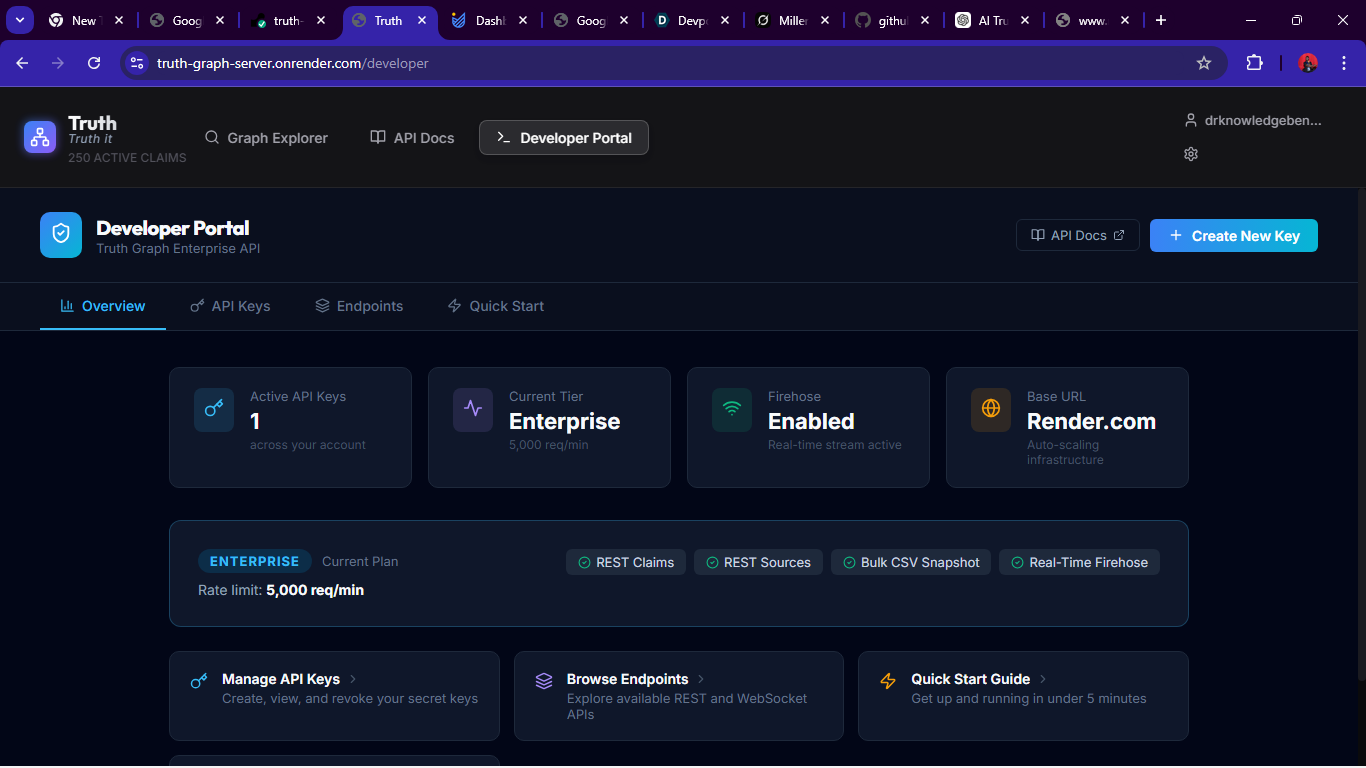
The Developer's Dashboard for API management
-
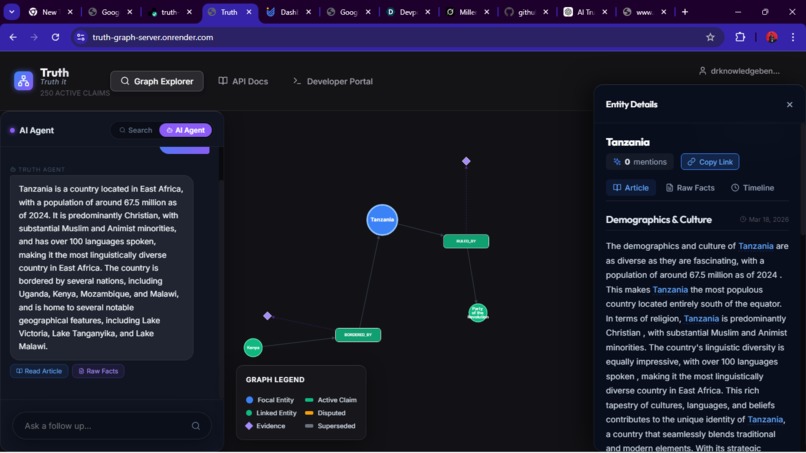
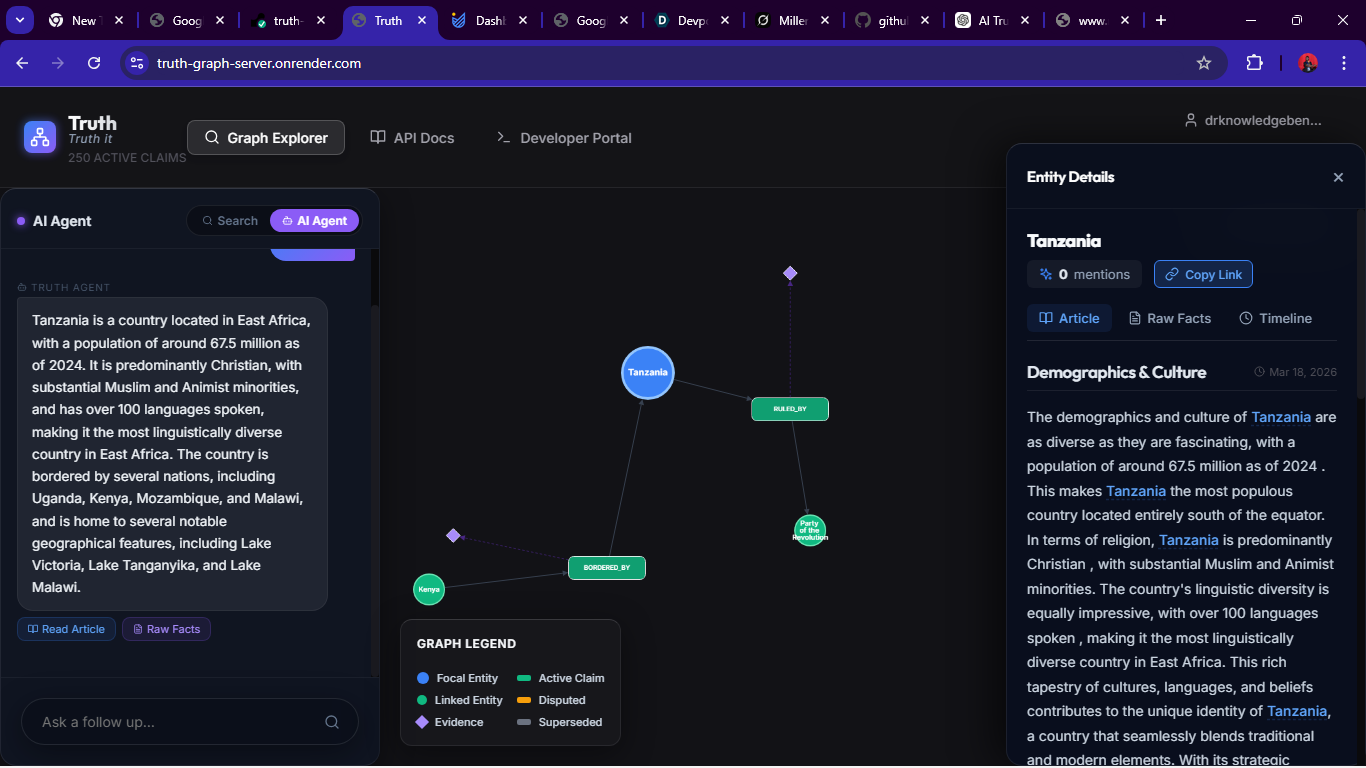
The Three column search Interface
-
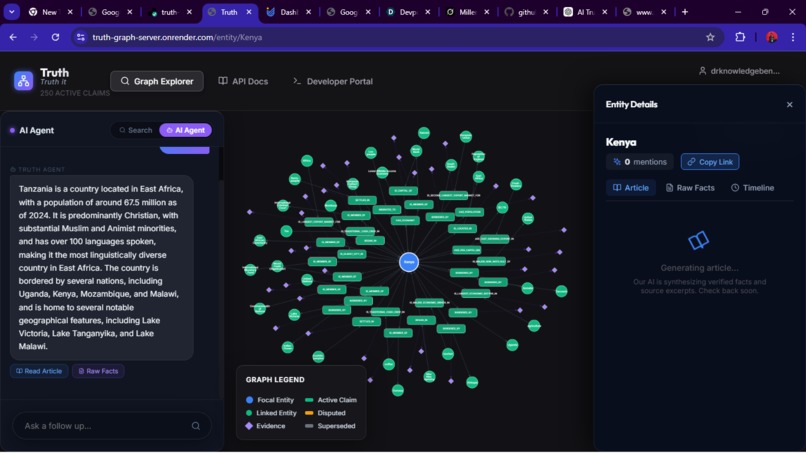
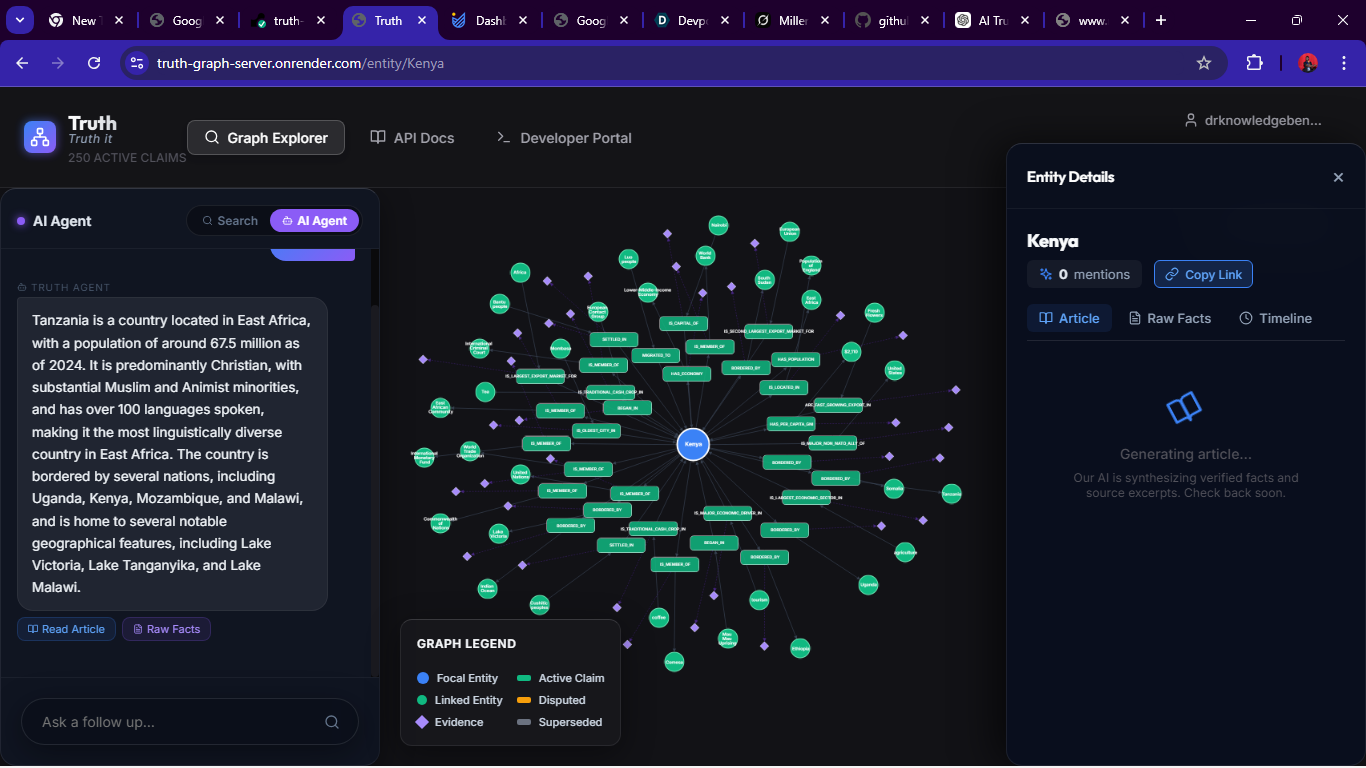
Showu=ing how the graph render's nodes
Inspiration
I have always yearned to make an impact on the world through technology, and during my first year of university (2024) I became deeply concerned by the spread of misinformation. In particular, I saw that large language models often “hallucinate” – confidently generating facts that aren’t real. Such hallucinations can present “fiction as fact,” eroding trust in AI systems and causing real harm. At the same time, I realized that news and facts lack a transparent provenance: there is no unified system tracking where facts come from, how they evolve, or if they have been debunked. In this context, building a verifiable truth system felt urgent.
Initially, I founded a small site called Nexa News Insights (https://www.nni.news) to publish carefully researched articles on major events. But writing one article took over 6 hours, which quickly proved unsustainable. The web moves too fast – a single author can’t keep up by manual reporting. I realized I needed to automate truth-finding: ingest news from many sources, cross-check claims, and build a dynamic “truth graph.” This inspired me to pivot from a static news site to Truth, an automated living fact-graph that continuously ingests information and embeds provenance at its core.
What it does
How we built it
The core of Truth is a 5-part architecture, each collaborating to ingest, validate, and serve facts:
AI Engine (Pipeline & Reasoner). This is the brain of the system: a multi-stage pipeline that ingests RSS feeds and search results, parses articles, and updates the Neo4j graph. At ingestion, raw articles are passed through a sentence-transformer model to generate an embedding $\mathbf{e}\in\mathbb{R}^d$ for each text. I compute similarity between embeddings (via $\cos(\mathbf{e}_i,\mathbf{e}_j)$) to link articles on the same topic. Next, the LLM reasoning component (using Meta’s Llama 3 family) performs tasks like extracting entities/events and even drafting short summaries or descriptions and writing inremently articles. I run both Llama-3-8B and a larger 70B variant (for more complex reasoning) via API inference. Because these models have a long 8K token context, I can feed them entire articles and even chains of reasoning. The engine also includes an article worker: whenever a new entity (node) is added to the graph, this worker uses the LLM to generate a concise “wiki-like” description of that entity, citing sources from the graph. All facts (triples) written into Neo4j carry a source attribute (URL and timestamp), implementing strict provenance. In essence, this pipeline distills unstructured news into a structured graph.
API Server. A lightweight backend (built in Node/Express) that mediates between the Neo4j graph and the frontend. It handles user queries (e.g. get graph data for entity “Climate Change”) and returns JSON from Neo4j. This ensures the front end never talks directly to the database.
Frontend Interface. I built a React web UI that feels like a Google search + chat. On a desktop view there are three columns: a chat agent on the left, a graph canvas in the center, and an article/entity viewer on the right. The chatbox is an LLM-powered agent with memory, trained to navigate the truth-graph. Users can ask it questions (“Show me the timeline of Arctic ice reports”) and it will traverse the graph to find answers. When it presents facts, those always come with cited sources from the graph. The graph canvas shows the network of related entities (like countries, companies, events); clicking nodes expands connections. The right panel lists supporting articles or notes about the selected item. This UI lets users visually explore knowledge and cross-check claims.
Search & Embedding Servers. I use two additional services (hosted on Hugging Face Spaces) to handle computations: (a) a SearXNG search server that provides web search results in real time, and (b) an inference server running sentence-transformer models for on-demand embedding. These services allow us to quickly prototype without local GPU limits.
Wayback/CC Proxy. A proxy server that takes a URL and returns the oldest archived version via Wayback or Common Crawl. This ensures that when citing a fact, I use the original publication date. if a news article has been updated, we retrieve its first archived snapshot.
Together, these components make Truth a “living graph” that continuously updates. The system is currently deployed at truth-graph-server.onrender.com. All interactions (search, chat, graph) rely on the combined AI+graph backend to ensure every statement is traceable.
Challenges we ran into
Building this system involved several technical and conceptual challenges:
Scalability and Compute: Running LLMs and embedding models at scale is heavy. Even the Llama-3-8B model requires substantial RAM/GPU. I had to run most of the pipeline on a local machine (no affordable cloud option was available) and rely on smaller models where possible and APIs. Integrating the external search and inference services helped, but I still hit limits on how much I could ingest per hour.
Data Quality and Verification: Another challenge was ensuring the graph didn’t become polluted with hallucinations. Implementing this verification logic and even periodic audits of graph edges has been tricky but necessary.
Provenance Tracking: I learned firsthand that missing provenance breaks trust. In a pilot test, one endpoint in the graph was incorrect; tracing the error backward was hard until I added timestamped source fields everywhere. Without them,I had no record of where that fact came from” and thus can’t fix downstream errors. Ensuring every node/edge includes its origin was a top priority – but it made the database schema more complex.
User Interface Complexity: Designing the UI to feel intuitive was also challenging. Balancing a search-like experience with graph exploration and chat required many iterations. I wanted the agent to be helpful without hallucinating itself, so we constrain it to only answer using data in the graph (no outside web). Likewise, rendering a live Neo4j graph in a web canvas required carefully managing state and performance.
Resource Constraints: Finally, doing all this as a solo developer meant I had to juggle roles. Time constraints limited how polished each part could be. I relied heavily on open-source tools (Neo4j, SearXNG, Sentence-Transformers) and Hugging Face hosting to accelerate development. Despite best efforts, the current deployment is “monolithic” and could be more efficient. However, these constraints also taught me to prioritize features. In our system, each article is represented by an embedding vector $\mathbf{e}\in\mathbb{R}^d$ (e.g. $d=384$). We measure similarity by cosine: [ \cos(\mathbf{e}i,\mathbf{e}_j)=\frac{\mathbf{e}_i\cdot\mathbf{e}_j}{|\mathbf{e}_i||\mathbf{e}_j|}. ] We also cluster embeddings (via K-means) to form topic groups by minimizing $\sum{i=1}^k \sum_{\mathbf{x}_j\in C_i} |\mathbf{x}_j - \boldsymbol{\mu}_i|^2$, where $\boldsymbol{\mu}_i$ are cluster centroids.
Accomplishments that we're proud of
What I learned
Through this journey, I learned both technical lessons and broader lessons about scale and trust. First, I saw that manual content curation won’t scale: at one article per 6 hours, I could never cover the flow of news in real-time. Instead, I needed automated pipelines.
Second, I learned that simply feeding all information into a machine is dangerous unless it’s grounded. In other words, we needed source attribution and verifiability for every fact.
I also learned that semantic embeddings are invaluable for news: by converting each article into a high-dimensional vector, I can measure topic-similarity directly. This lets me cluster related articles or find nearest-neighbors for recommendations. In practice, I found that a batch embedding step followed by indexing allows me to group stories by theme or retrieve similar sources efficiently.
Another key lesson was graph structuring: storing data in Neo4j enables rich relationships (source, date, topic) to be queried. I learned from Neo4j’s analysis that a “news graph” built with ML and graphs can highlight the credibility of sources by looking at connections.
Finally, I understood the importance of web provenance: the world of online news is ephemeral (pages are updated, deleted). To ensure the original context of a fact, I added a component that checks the Internet Archive’s Wayback Machine and Common Crawl. This helps us find the oldest available URL for a claim, so I can cite the original source rather than a possibly-altered copy.

Log in or sign up for Devpost to join the conversation.