-
-
Landing page
-
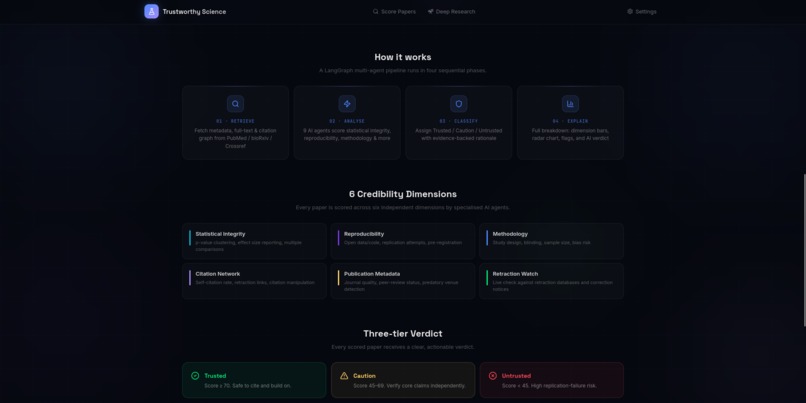
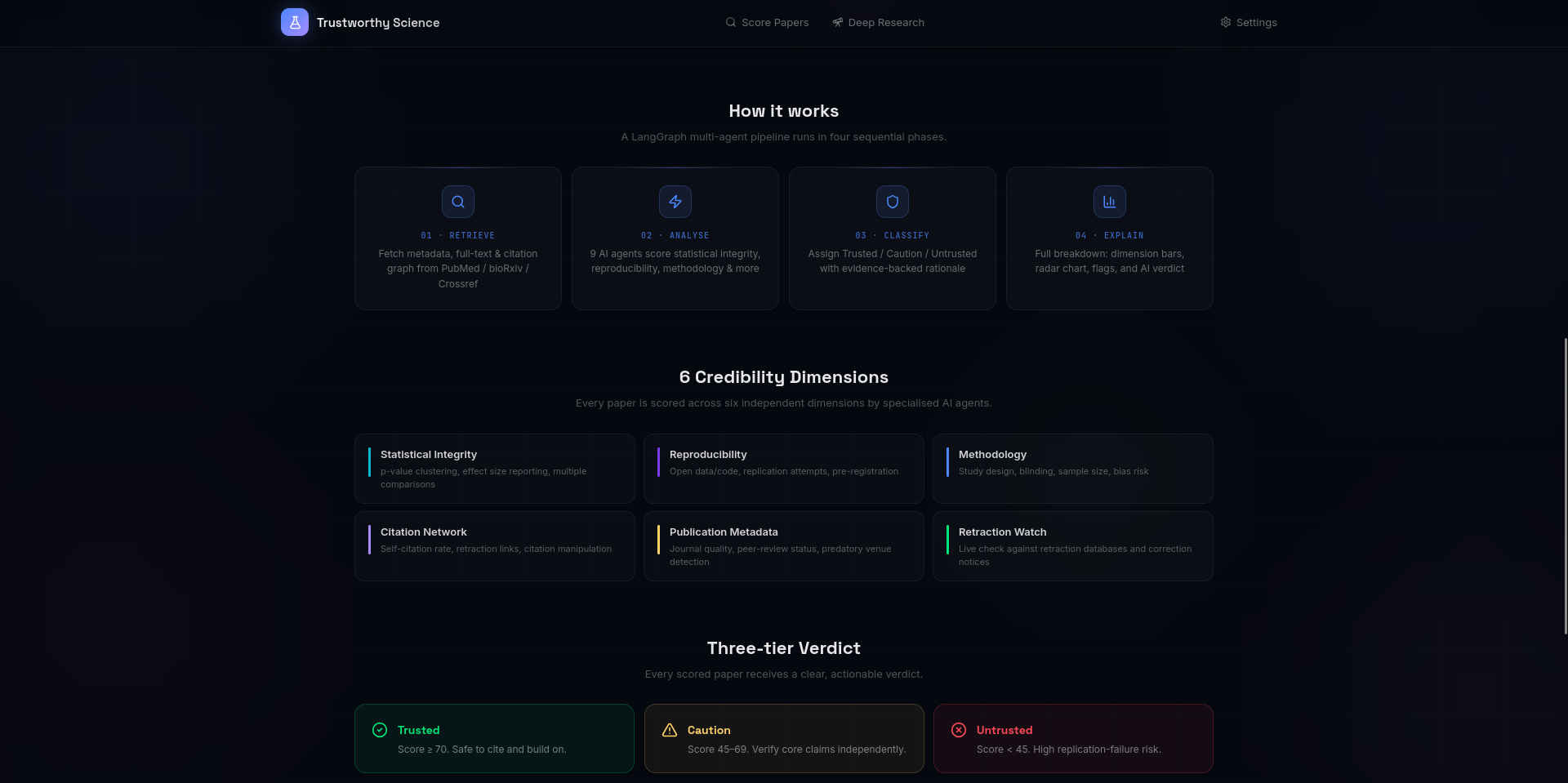
Feature List
-
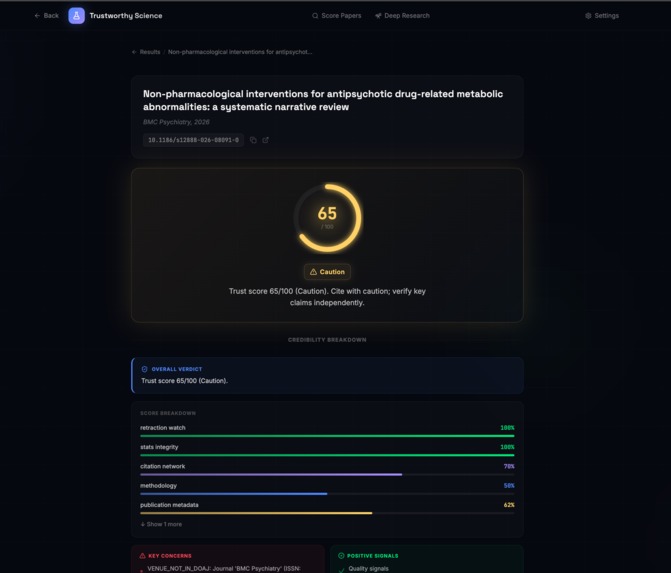
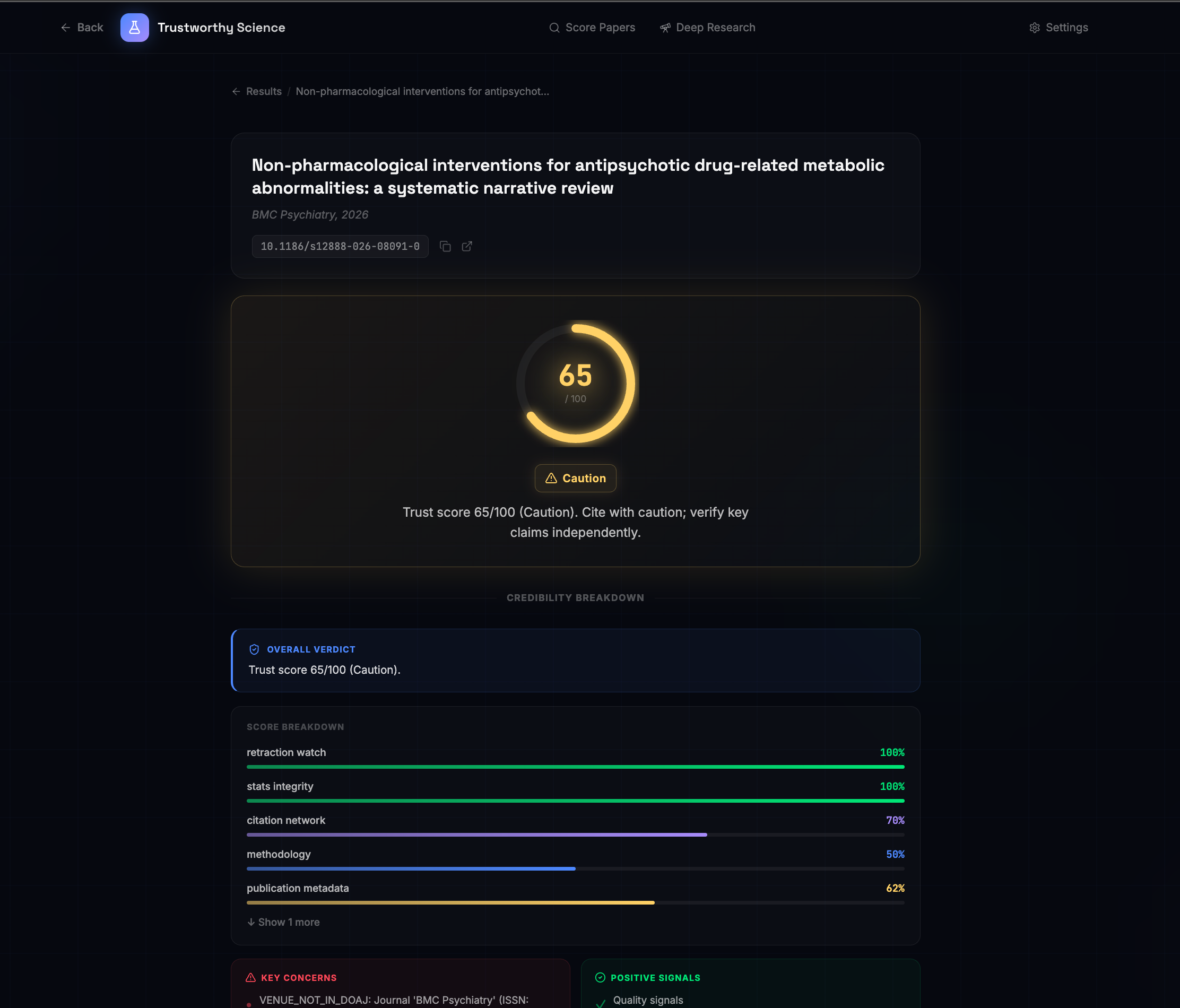
Scoring for a paper
-
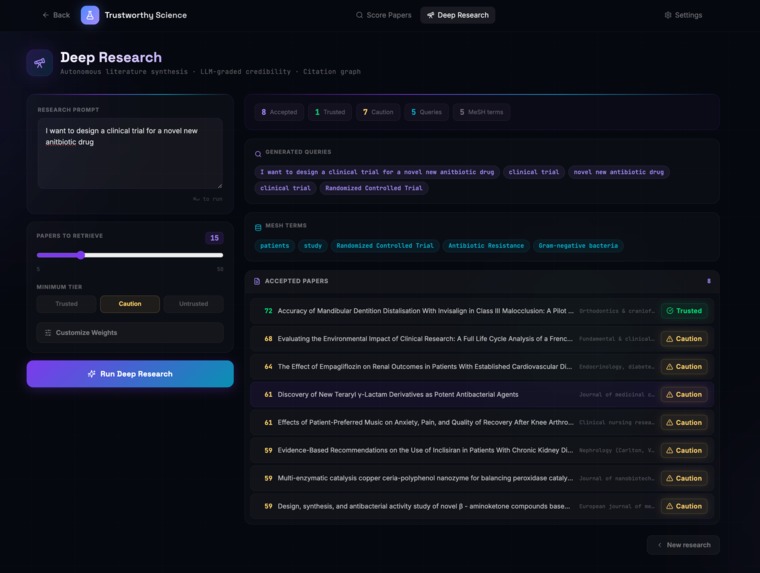
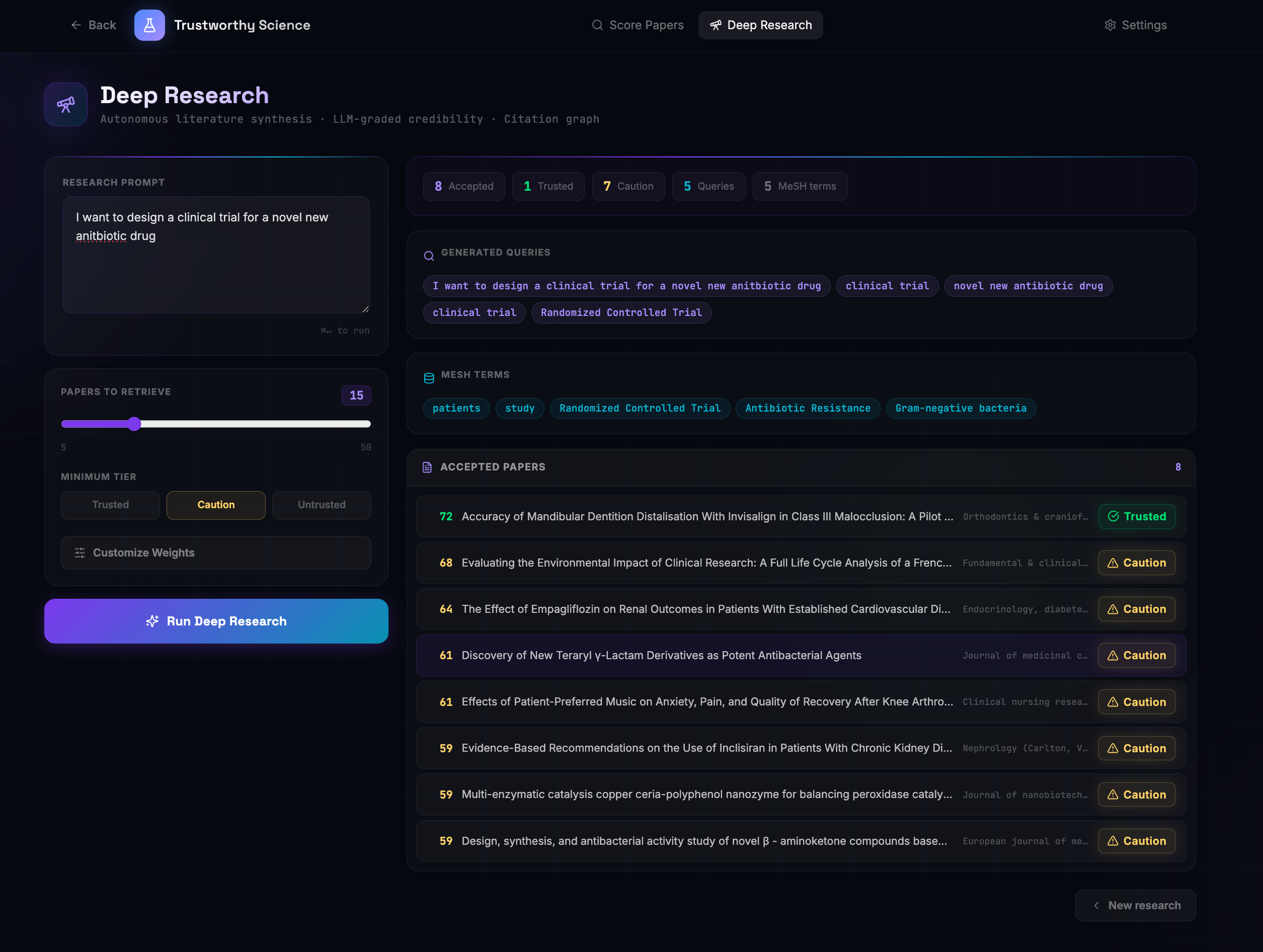
Deep Research Results
Inspiration
Every drug that reaches a patient starts the same way: a researcher reads the literature. But that process is broken in ways most people outside biomedical science don't realize.
The field has a fraud problem. A large-scale retraction study found that 67.4% of retracted papers were pulled due to misconduct — 43.4% for fraud or suspected fraud, 14.2% for duplicate publication, 9.8% for plagiarism. These aren't edge cases. They're papers that got through peer review, got cited, and quietly shaped the direction of downstream research.
It also has a reproducibility problem. 72% of biomedical researchers say the field is in a crisis. Replicating published findings fails often, wasting months of lab time and sometimes sending entire research programs in the wrong direction.
The cost isn't just scientific. It's measured in years. A single systematic literature review takes an average of 26.9 hours just for the search and vetting phase. And that's before anyone has run a single experiment. We built this tool because we think AI can do better than reading uncritically. Rather than summarizing whatever it finds, it should ask the same questions a rigorous scientist would: Is this paper's statistics clean? Has anyone replicated it? Who funded it, and does that matter? Getting those answers right at scale, automatically could meaningfully compress the time between a research hypothesis and a treatment that actually works.
What it does
We built is a multi-agent verification system that takes into account a number of hard and soft metrics to rate the reliability of a publication and provide rationale behind each metric
To help researchers who are in the early stage of a project, we provide a deep research mode that can look for a variety of adjacent literature and present ones that are reliable and useful
How we built it
1) The Multi-Agent Orchestrator We used LangGraph to design a stateful, non-linear workflow. Instead of a single prompt, the system routes tasks through a network of specialized agents.
Conditional Handoffs: If the Retraction Watch Agent identifies a retracted paper, the system short-circuits the audit and sends it straight to the "Untrusted" tier, saving resources.
Parallel Execution: We parallelized independent audit nodes—such as the Methodology, Citation Network, and Publication Metadata agents—allowing them to analyze different dimensions of a paper simultaneously before converging at the final scoring node.
2) The "Truth Filter" Mechanism is our auditing pipeline that processes every paper through a gauntlet of credibility checks:
Statistical Integrity Agent: This agent performs automated "forensic" checks. It uses Benford's Law to detect potential data fabrication and extracts p-values to identify signs of "p-hacking" or statistical anomalies in the abstract.
Methodology Auditor: A specialized agent that classifies the study type (e.g., RCT vs. Case Study) and audits the design. It looks for "Hard Flags" like small sample sizes or lack of control groups.
Publication Vetting: We integrated a Metadata Agent that cross-references journals against Beall's List of predatory publishers and assigns tiers to venues based on their historical impact and peer-review rigor.
Weighted Scoring Engine: Unlike a simple "pass/fail," our Scoring Agent aggregates signals from all other agents. It uses a weighted formula where "Hard Flags" (like a retraction or predatory venue) result in immediate downgrades, while "Soft Flags" (like low citation counts) provide nuanced context to the final 0–100 Trust Score.
3) Integrated RAG Synthesis Once the Truth Filter has distilled the "Candidate Stubs" into a "Trusted" library, we employ a Retrieval-Augmented Generation (RAG) pipeline. We use ChromaDB with local Sentence-Transformer embeddings to ingest only the high-credibility papers, ensuring the final literature review and chatbot responses are grounded strictly in evidence that has survived our multi-agent audit.
4) UI & Deployment Our UI was built using React and Vite, and the entire stack is hosted on a Digital Ocean Droplet.
Challenges we ran into
The biggest hurdle was the "Librarian Problem", which was getting LLMs to consistently generate complex Boolean PubMed queries using specific tags like [Mesh] and [Title/Abstract]. We solved this by implementing a two-phase "MeSH Librarian" agent that first validates concepts against the official MeSH database before constructing the final search string. We also spent significant time optimizing our "Scoring Agent" to ensure that various signals (like a high citation count vs. a "Caution" venue tier) were balanced fairly in the final 0-100 Trust Score.
Accomplishments that we're proud of
The piece of this project we're most proud of is the credibility pipeline itself. It tackles something genuinely hard. Scientific misinformation is a real and growing problem. Researchers, clinicians, journalists, and even policymakers regularly cite papers that have been retracted, published in predatory venues, or riddled with statistical manipulation. Before this project, filtering for that required either expensive expert review or just hoping for the best.
What we learned
Agentic orchestration is harder than it looks. LangGraph's graph model is powerful, but managing concurrent state writes across four parallel agents required careful use of Annotated reducers and real debugging to get deterministic behavior.
LLM outputs need guardrails at every layer. For methodology assessment, report generation, and MeSH query construction, we had to handle hallucinations, malformed JSON, and partial outputs gracefully. The deterministic fallback became essential, not optional.
Domain knowledge matters as much as engineering. Which venues to trust, what self-citation ratio is suspicious, when missing preregistration is a red flag versus irrelevant — none of that can be derived from first principles. We spent real time in the reproducibility literature, not just writing code.
What's next for Trustworthy Science
- Visual Analysis: Implement multi-modal agents to analyze figures and charts for signs of image manipulation.
- Granular Stats: Add deep-dive statistical agents to perform GRIM (Granularity-Related Inconsistency Check) tests on reported means and SDs.
- Broadened Scope: Expand beyond biomedical research into social sciences and engineering by integrating ArXiv and SSRN.
- Our most ambitious goal is to act as a reliability layer for preprint archives, so that we can improve the quality of research output present on them.


Log in or sign up for Devpost to join the conversation.