-
-
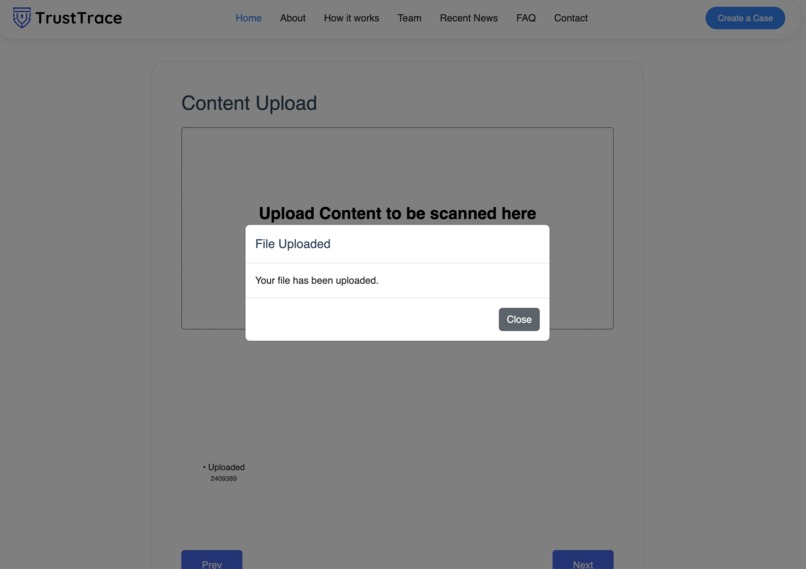
Video Uploaded
-
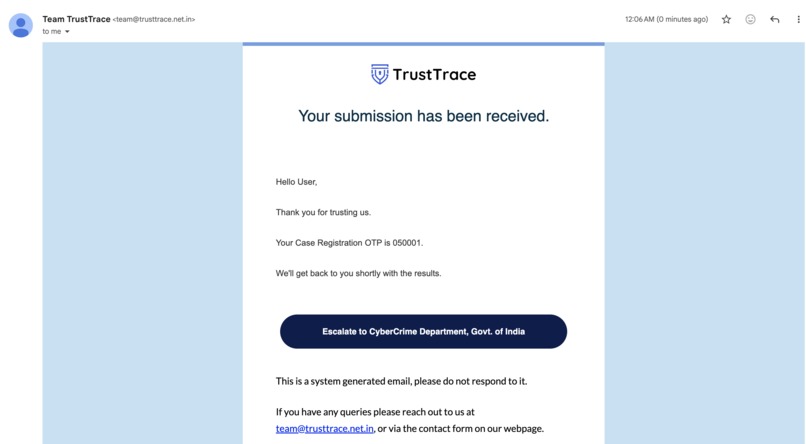
Automated Email Notification System
-
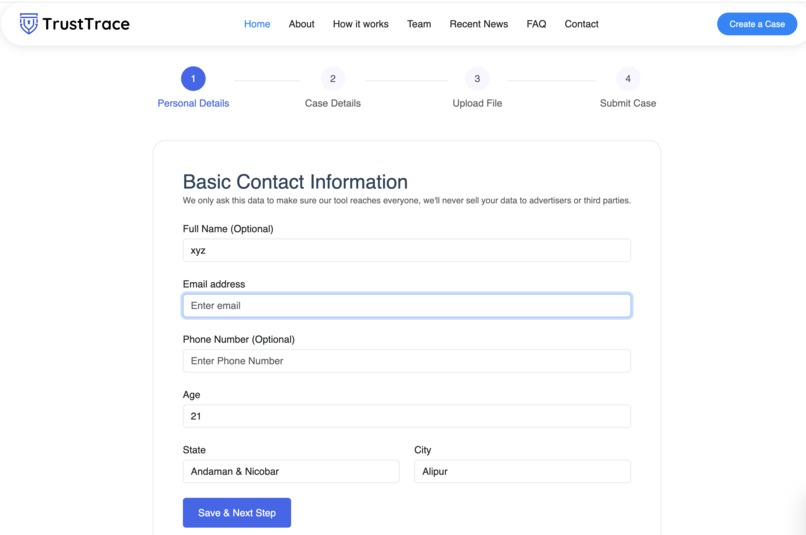
Case Creation: Email-based OTP verification (Name optional)
-
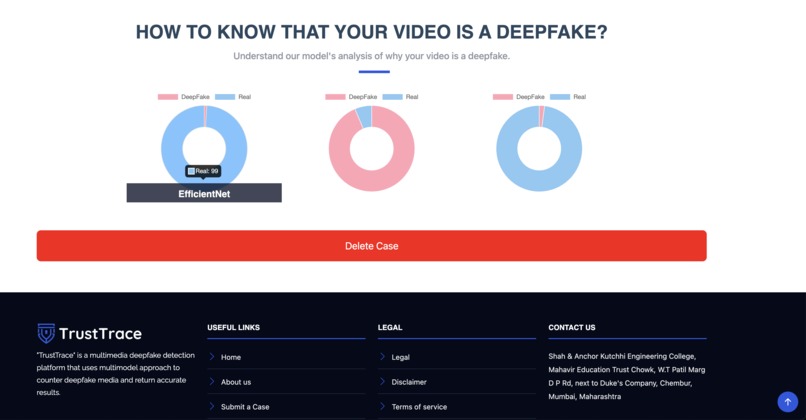
Multiple models analyze different video attributes. One model may flag deepfake due to specific artifacts, improving reliability.
-
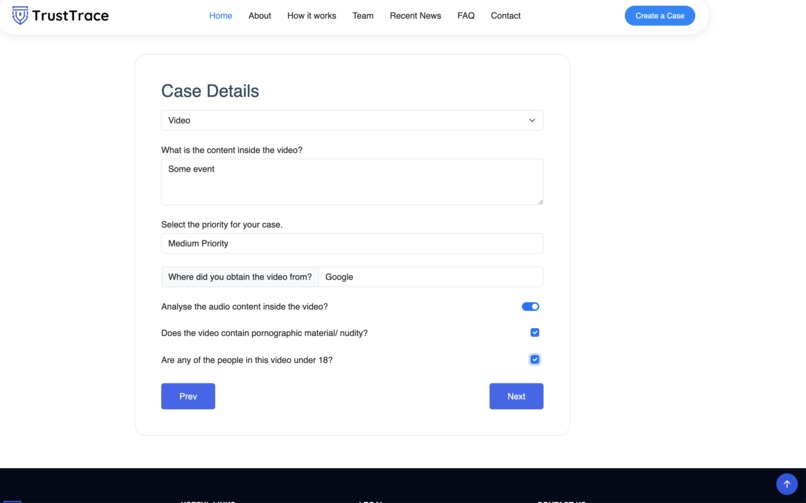
Video Upload: Content Sensitivity and 18+ Compliance Selection
-
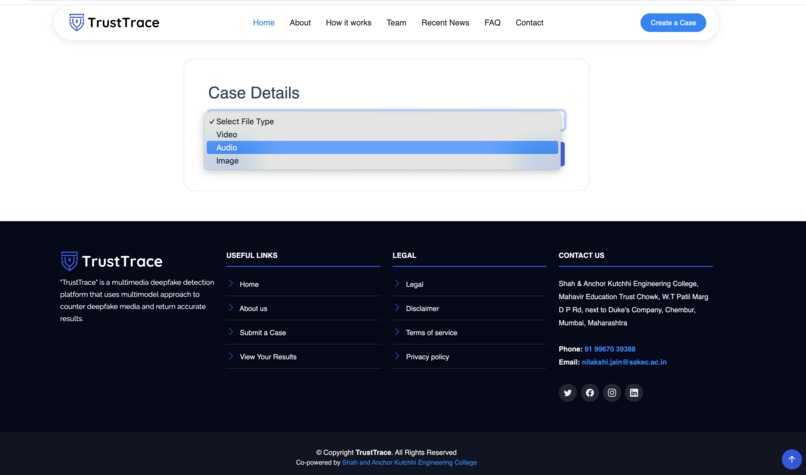
Select Media Type – Image, Audio, or Video
-
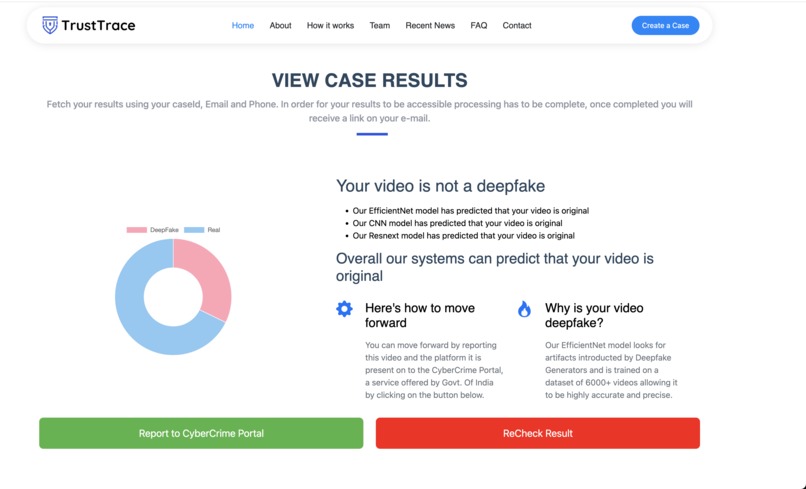
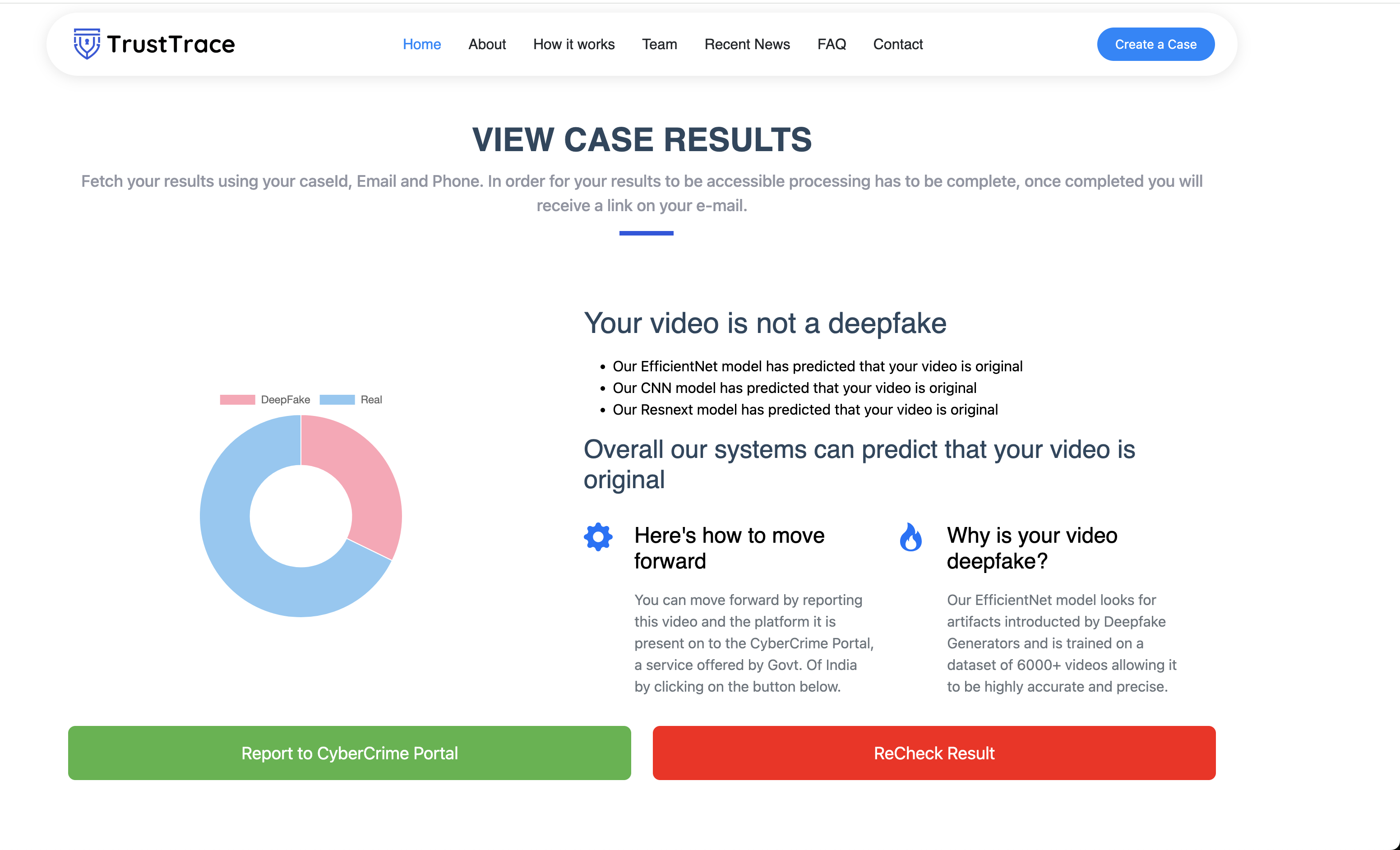
Our result page
-
Home Page of our website..Just click on create a case in order to check your media..

Inspiration
The idea for TrustTrace was born from a growing concern about how rapidly artificial intelligence is advancing and how easily it can now be misused. Today, AI models are capable of creating highly realistic fake images, audio clips, and videos that are almost impossible for humans to distinguish from real ones.
Our team first became deeply aware of this problem after seeing widely circulated morphed videos and manipulated content involving Indian Prime Minister Narendra Modi. The situation became even more alarming when Prime Minister Modi himself publicly warned citizens about the dangers of deepfakes and the threat they pose to society.
Around the same time, cricket legend Sachin Tendulkar also spoke about how a deepfake video using his likeness was used in a scam that led to financial fraud. These incidents showed us that deepfakes are no longer just an experimental technology—they are actively being used to mislead people, damage reputations, and exploit trust.
We also observed similar global examples, including manipulated videos and AI-generated voice clips involving public figures like former U.S. President Donald Trump, which further demonstrated that this is a worldwide issue affecting people across countries and cultures.
These real-world cases made us realize that existing solutions are often fragmented—some tools detect fake images, others focus only on video or audio. There is no simple, unified platform that can verify all major media types in one place.
This gap inspired us to build TrustTrace: a single, unified platform capable of detecting deepfakes in images, audio, and video, with the goal of restoring trust in digital content and helping people confidently distinguish truth from manipulation.
What it does
TrustTrace is a unified multimedia deepfake detection platform that allows users to verify images, audio, and video through a single, simple workflow.
The process begins by creating a case. This case-based approach helps organize submissions and ensures that every analysis is tracked securely. During case creation, users are asked to provide an email address for communication and result access. Providing a name and phone number is optional.
Once a case is created, users can upload either an image, an audio file, or a video file for analysis. After submission, the platform processes the media using trained deep learning models designed to detect signs of manipulation and synthetic generation.
When the analysis is complete, users are redirected to a results page that clearly indicates whether the media is likely real or deepfake, along with a confidence score. Our system currently achieves an accuracy range of approximately 80–90% across supported media types.
TrustTrace is built with privacy and safety at its core. The platform follows DPDP-compliant data handling practices. Users also have the option to delete their uploaded files immediately after receiving results, which is especially important for sensitive or personal content.
How we built it
TrustTrace was developed by our team of final-year undergraduate students under the guidance of our college mentor, Dr. Nilakshi Jain. From the beginning, we approached this project as a long-term research and development effort rather than a short prototype.
We received a development grant through our institution in collaboration with CyberPeace Foundation, which enabled access to computing resources, datasets, and mentoring support. Using this support, we worked on the project continuously over a span of approximately one year.
We began by building and training separate deepfake detection models for images, audio, and video. This involved collecting datasets, performing preprocessing, experimenting with multiple deep learning architectures, and fine-tuning models using GPU-enabled environments.
After achieving reliable performance, we integrated the models into a backend system that manages case creation, secure uploads, and inference requests. A web-based frontend was then built to provide a clean and simple user experience.
Throughout development, we emphasized scalability, security, and privacy, ensuring responsible handling of user data.
Challenges we ran into
One of the biggest challenges we faced was related to dataset diversity and generalization. Many public deepfake datasets are limited to specific regions, demographics, or recording conditions. Models trained on such narrow datasets often fail to generalize well across different faces, accents, lighting environments, and camera qualities.
To address this, we curated and created portions of our own dataset by combining multiple sources and generating additional samples to increase diversity. This helped our models learn generalized manipulation patterns rather than dataset-specific artifacts.
Another major challenge was limited computing resources. Training deep learning models is computationally expensive and time-consuming. We mitigated this using transfer learning, optimized architectures, and efficient training strategies, though scalability remains an ongoing goal.
We also faced system integration challenges while combining multiple detection pipelines into a single unified platform, as well as implementing privacy-preserving storage and deletion mechanisms.
Accomplishments that we’re proud of
We have secured our own patent for the TrustTrace platform. We have published nine research papers in peer-reviewed venues related to deepfake detection and multimedia forensics. We won the Delhi Police Hackathon for our work in combating cybercrime and digital misinformation. We won a global-level competition at the Intel AI Impact Global Summit. We have also received recognition at local hackathons such as the Tatravihar Hackathon.
What we learned
We learned that building responsible AI systems requires more than model accuracy—it requires careful consideration of data, privacy, usability, and real-world impact. We gained strong experience in dataset engineering, model training, system integration, and full-stack development. We also learned the importance of teamwork, documentation, and iterative improvement over long-term projects.
What’s next for TrustTrace
Our next focus is on scaling TrustTrace for real-world deployment with faster and more efficient processing. We aim to enable real-time deepfake monitoring and explore integrations with social media platforms. We plan to build browser extensions for real-time verification and develop mobile applications. We are developing a misinformation detection module for text content, currently in the testing phase. We are also working with a law firm to design forensic-grade evidence handling, chain-of-custody features, and verifiable reporting. Our long-term goal is to evolve TrustTrace into a comprehensive digital forensics and media verification platform.


Log in or sign up for Devpost to join the conversation.