-
-
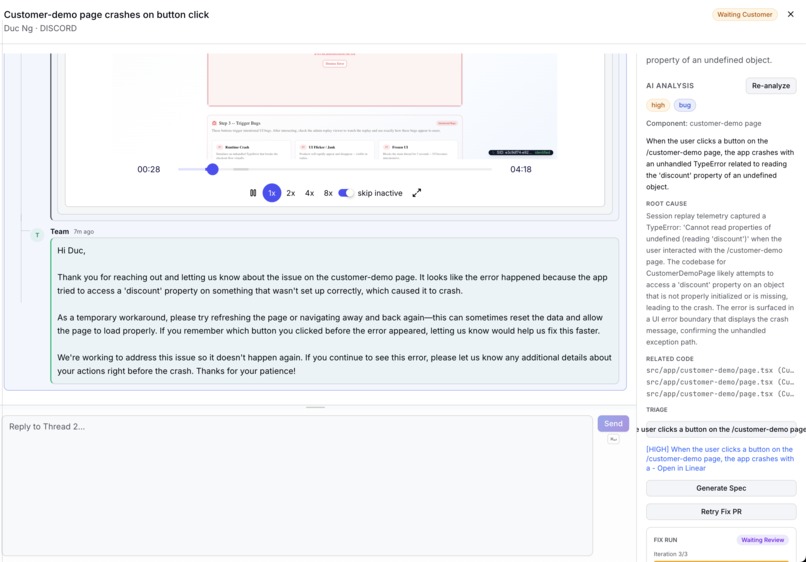
Thread chat
-
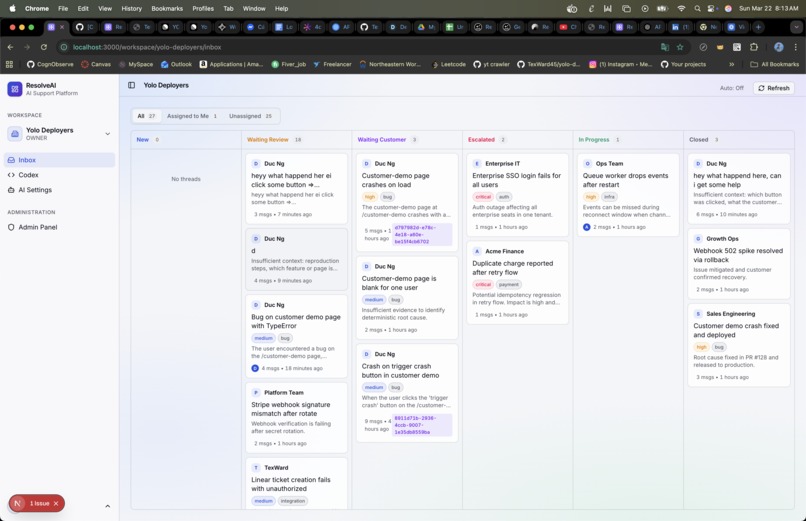
Workspace
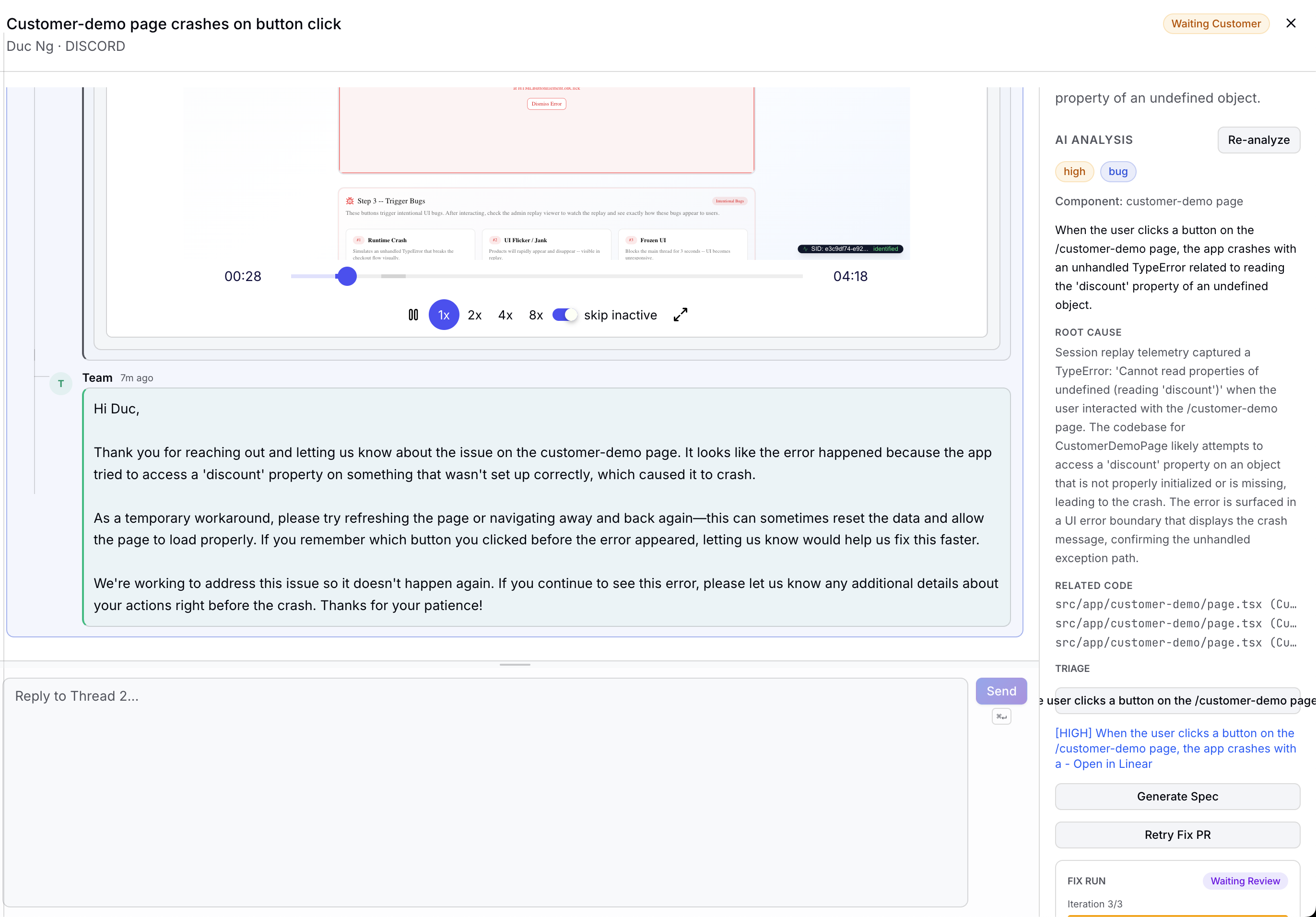
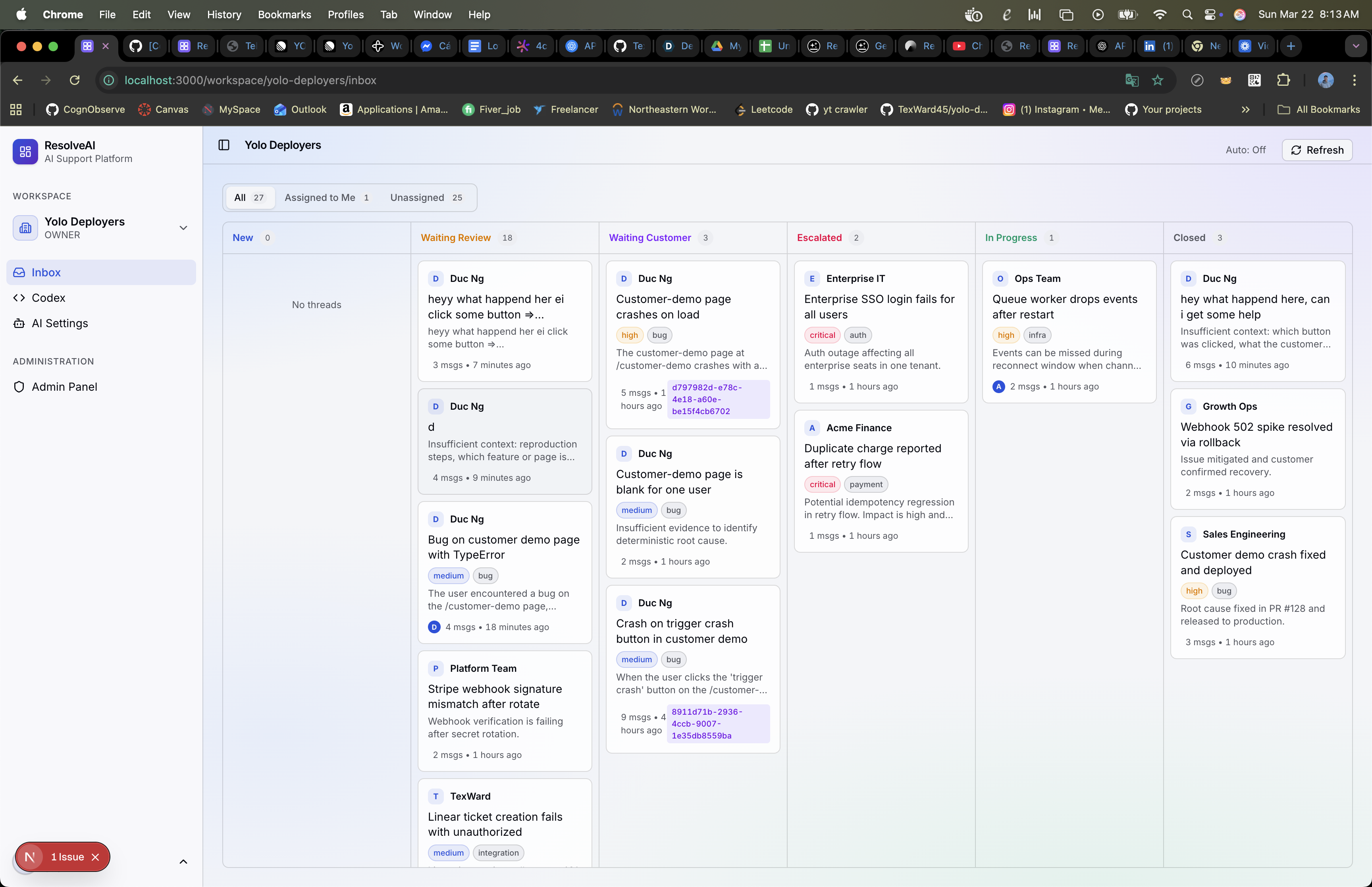
Inspiration
Support teams everywhere face the same frustrating cycle: a
customer reports a bug, an engineer spends an hour hunting
through code to find it, and by the time they respond — the
customer has already moved on.
We noticed a massive gap between where bugs are reported (chat channels like Discord) and where bugs actually live (deep inside the codebase). Traditional support tools treat these as completely separate worlds. What if an AI could bridge that gap — reading a customer's complaint, searching the actual source code, finding the root cause, and drafting a fix — all in seconds?
That's how ResolveAI was born. Not just another chatbot that gives generic answers, but an AI agent that genuinely understands your code and connects it to what your customers are telling you.
What it does
ResolveAI is an AI-powered support platform that automatically investigates customer issues by searching your codebase, correlating error logs, and drafting replies — with a human always making the final call.
The Smart Support Pipeline
When a customer sends a message (via Discord or in-app chat), here's what happens behind the scenes:
- Thread Matching — The system figures out which conversation this message belongs to. Is it a new issue, or part of an existing one? It uses a cascade of smart rules — and when those aren't enough, an LLM makes the judgment call.
- Sufficiency Check — Before doing any heavy lifting, the AI asks: "Do we have enough info to investigate?" If not, it drafts a clarification question to ask the customer, instead of wasting time guessing.
- Parallel Investigation — Once there's enough context, the AI
fans out:
- Searches your codebase using our code intelligence engine (Codex)
- Pulls error data from Sentry
- Checks session replays to see exactly what the customer experienced
- Analysis & Draft — The AI synthesizes everything into a structured analysis (severity, root cause, affected code) and writes a draft reply matching your team's tone.
- Human Approval — Nothing goes out without a human saying "send." Always.
Codex: Your AI's Code Brain
Codex is what makes ResolveAI different from generic AI support tools. It deeply indexes your codebase:
- Supports GitHub, GitLab, Bitbucket, Azure DevOps, local repos, and ZIP archives
- Parses code using Tree-sitter AST — meaning it understands functions, classes, types, and how they connect (not just text matching)
- Supports TypeScript, Python, Go, Java, and Rust
- Hybrid search combining semantic understanding, keyword matching, and symbol graph traversal
- Stays up-to-date via webhooks, scheduled syncs, or manual triggers
From Bug Report to Fix PR
Once an issue is investigated, ResolveAI can go further:
- Create a Linear ticket with the right priority and context
- Generate an engineering spec describing the fix
- Open a GitHub Pull Request with actual code changes, validated by automated tests and code review — all driven by an iterative AI agent loop
Session Replay
A built-in session replay system records what customers actually do in your app — clicks, errors, UI glitches. When a customer reports a bug, the AI can literally watch their session to understand what went wrong.
Multi-Tenant Workspaces
Everything is workspace-scoped. Each team configures their own:
- AI behavior (model, tone, system prompt)
- Channel connections (Discord, in-app chat)
- Integrations (Sentry, Linear, GitHub)
- Code repositories for investigation
How we built it
We built a monorepo with three services:
| Service | What it does |
|---|---|
| Web App | Next.js 16 frontend + API layer |
| Queue Worker | Background AI pipelines + Discord bot |
| Codex Worker | Code indexing + fix PR generation |
Key tech decisions:
- Temporal for orchestrating background workflows — every AI pipeline runs as a durable, retryable workflow with full visibility
- tRPC for end-to-end type-safe APIs — the frontend and backend share the same type definitions, catching bugs at compile time
- Prisma 7 + pgvector for the database — PostgreSQL handles both relational data and vector embeddings for code search
- Tree-sitter for parsing source code into structured AST chunks across 5 languages
- Zod for runtime validation — one schema definition used everywhere, from API routes to form inputs
- All LLM integrations follow a consistent pattern: each AI feature lives in a single *.prompt.ts file containing the prompt, message builder, and API call
The queue worker never writes to the database directly — all mutations go through the web app's REST API, keeping the data layer centralized and easy to audit.
Challenges we ran into
Thread matching was deceptively hard. When multiple customers report the same bug, their messages should land in one thread — not ten. We built a 6-level matching system, but tuning the thresholds took extensive testing. Too aggressive and unrelated issues merge; too conservative and duplicates pile up.
Temporal's sandbox restrictions forced us to rethink our architecture. Temporal workflows can't do any I/O (no database calls, no HTTP requests) — everything must happen in separate "activities." This was painful at first, but the resulting separation of concerns made the code much cleaner.
Balancing hybrid search was tricky. Semantic search understands meaning but misses exact names. Keyword search finds exact matches but lacks context. Symbol search captures code relationships but needs a populated graph. Getting these three channels to work together required multiple iterations.
AI-generated code fixes are unreliable for complex, cross-file changes. We added context expansion (pulling in surrounding code chunks) to give the fixer agent better spatial awareness, but this remains an active area of improvement.
Accomplishments that we're proud of
- End-to-end automation: A Discord message can trigger investigation, find the relevant code, draft a reply, create a Linear ticket, write a spec, and open a fix PR — all automatically (with human approval gates)
- Real code understanding: Tree-sitter AST parsing means the AI can pinpoint "the bug is in processPayment() at line 142" — not just "somewhere in the billing code"
- Sub-5-second thread matching: Simple heuristics handle ~85% of messages instantly; the LLM fallback only fires when needed
- Session replay integration: The AI can watch what the customer experienced, connecting frontend behavior to backend errors
- Full type safety across the stack: From database schema to React components, every boundary is typed — catching entire classes of bugs before they ship
What we learned
- Ask before you investigate. The sufficiency check saves ~40% of unnecessary AI calls. One targeted clarification question is almost always faster than investigating a vague bug report.
- Use deterministic rules first, LLMs second. Simple heuristics handle most cases. AI is a powerful fallback, not the first tool you reach for.
- Human-in-the-loop builds trust. We deliberately require approval for every outbound message. Support teams adopt the tool faster when they know the AI won't embarrass them.
- Monorepo discipline pays off. Shared types and API definitions mean a schema change propagates everywhere instantly. High setup cost, but massive ongoing velocity.
- Durable workflows change everything. Once every background task is a Temporal workflow with automatic retries, you stop writing defensive code and start trusting your infrastructure.
What's next for ResolveAI
- Proactive monitoring — detect issues from error spikes before customers report them
- Knowledge base generation — auto-build searchable docs from resolved threads
- Slack and Intercom support — expand beyond Discord to more support channels
- Smart LLM routing — dynamically pick the best model based on task complexity and cost
- Auto-merge for high-confidence fixes — when CI passes and the AI is highly confident, allow auto-merge with human notification
Built With
- codex
- monorepo
- temporal
- typescript





Log in or sign up for Devpost to join the conversation.