Trust-First Triage Desk
Verify what 10,088 Indian healthcare facilities actually claim — with evidence and honest uncertainty.
Live app: https://trust-first-triage-desk-108684035875991.aws.databricksapps.com
Repo: https://github.com/freeformelm/trust-first-triage-desk
Inspiration
The Databricks × Virtue Foundation Hackathon handed us 10,088 Indian healthcare facility records scraped from the open web through the Foundational Data Refresh (FDR) pipeline: Bright Data crawl → GenAI extraction → entity resolution. The pitch deck was blunt — this is messy data. The capability field covers 99.7% of rows, but capacity only 25%. Hospitals claim ICU, NICU, oncology, and trauma services in free text, and a non-technical planner has no way to know which claims are real.
Two statistics reframed the problem for us:
- 143 million people awaiting surgery in LMICs each year
- 2.88 billion global DALYs — years of healthy life lost to inadequate care
Virtue Foundation's existing VF Match already shows the geographic deserts. But geography solves only half the problem. The deeper question — "can this facility actually do what it claims?" — has no good answer for a planner routing donations, a referral coordinator picking a hospital, or a public health official mapping coverage. They need to distinguish a real 30-bed ICU from a clinic whose own description says "ICU cases referred elsewhere."
So we picked Track 1: Facility Trust Desk and built it as the foundation that unlocks the other three tracks by side effect. Verified claims make a Medical Desert Planner trustworthy. Verified claims make a Referral Copilot safe. Verification work products become a Data Readiness Desk for free.
What it does
Trust-First Triage Desk is a Databricks App for a non-technical health planner.
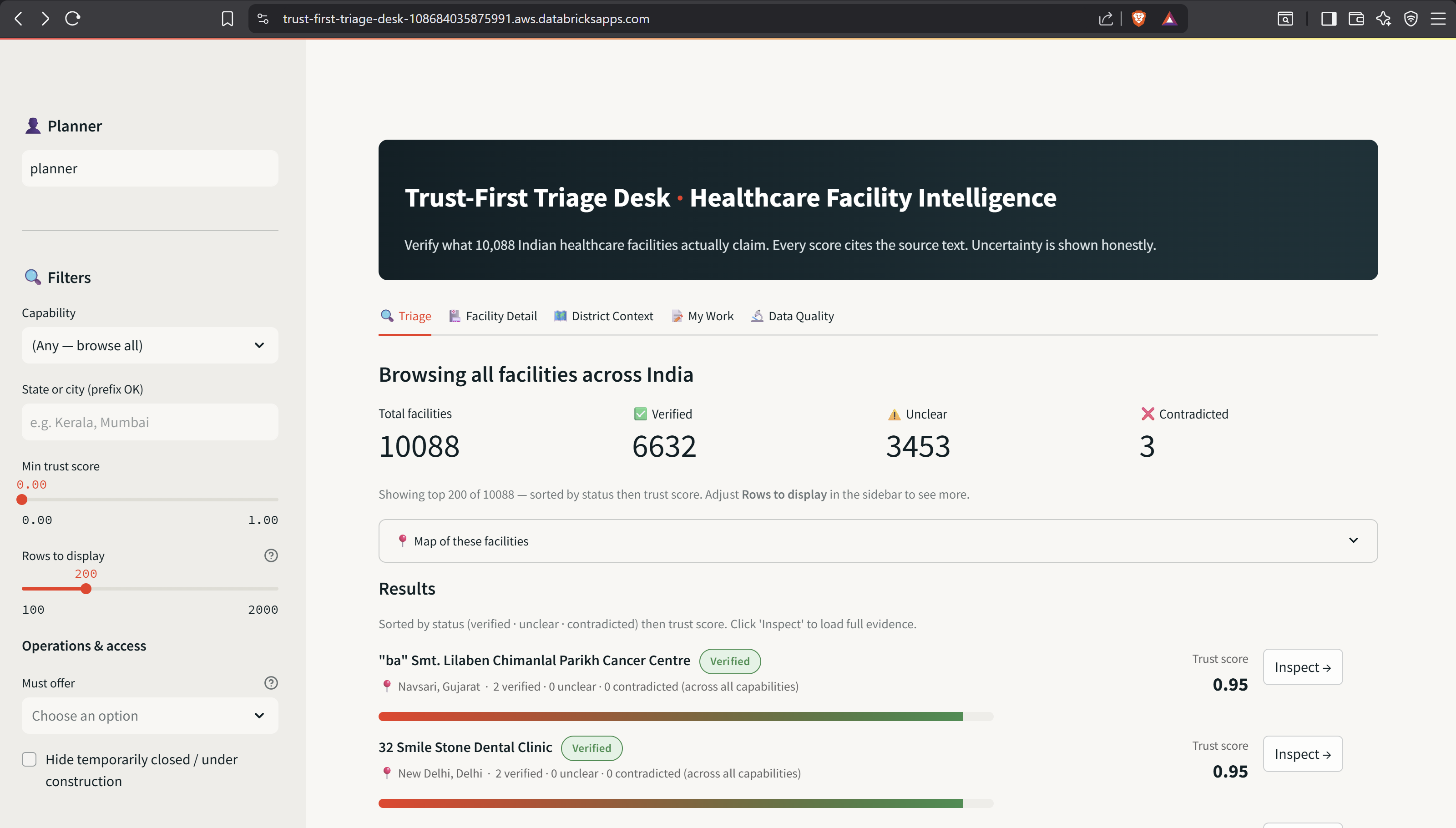
- Triage view — pick a capability (12 supported: ICU, NICU, maternity, emergency, oncology, trauma + surgery, cardiology, dialysis, radiology, pediatrics, ophthalmology) or browse all 10,088 facilities at once. Filter by state or city, set a minimum trust score, choose how many rows to render. Every facility is ranked and color-coded: ✅ Verified, ⚠️ Unclear, ❌ Contradicted. Metrics always reflect the full set, the table is a display sample.
- Facility Detail modal — opens over the triage list (no tab switching). Shows the exact claim text, every supporting and contradicting snippet from the facility's own description / capability / equipment / specialty fields, and a trust gauge.
- Operations & access chips — surfaces availability indicators (24/7, ambulance, blood bank) and flags closed / under-construction / referral-out status before a planner commits.
- Persistent planner work — verify / reject / needs-info buttons and free-text notes write to Lakebase Postgres. A "My Work" tab shows history across sessions. A sidebar OAuth-token input lets planners refresh Lakebase credentials in-session without redeploying.
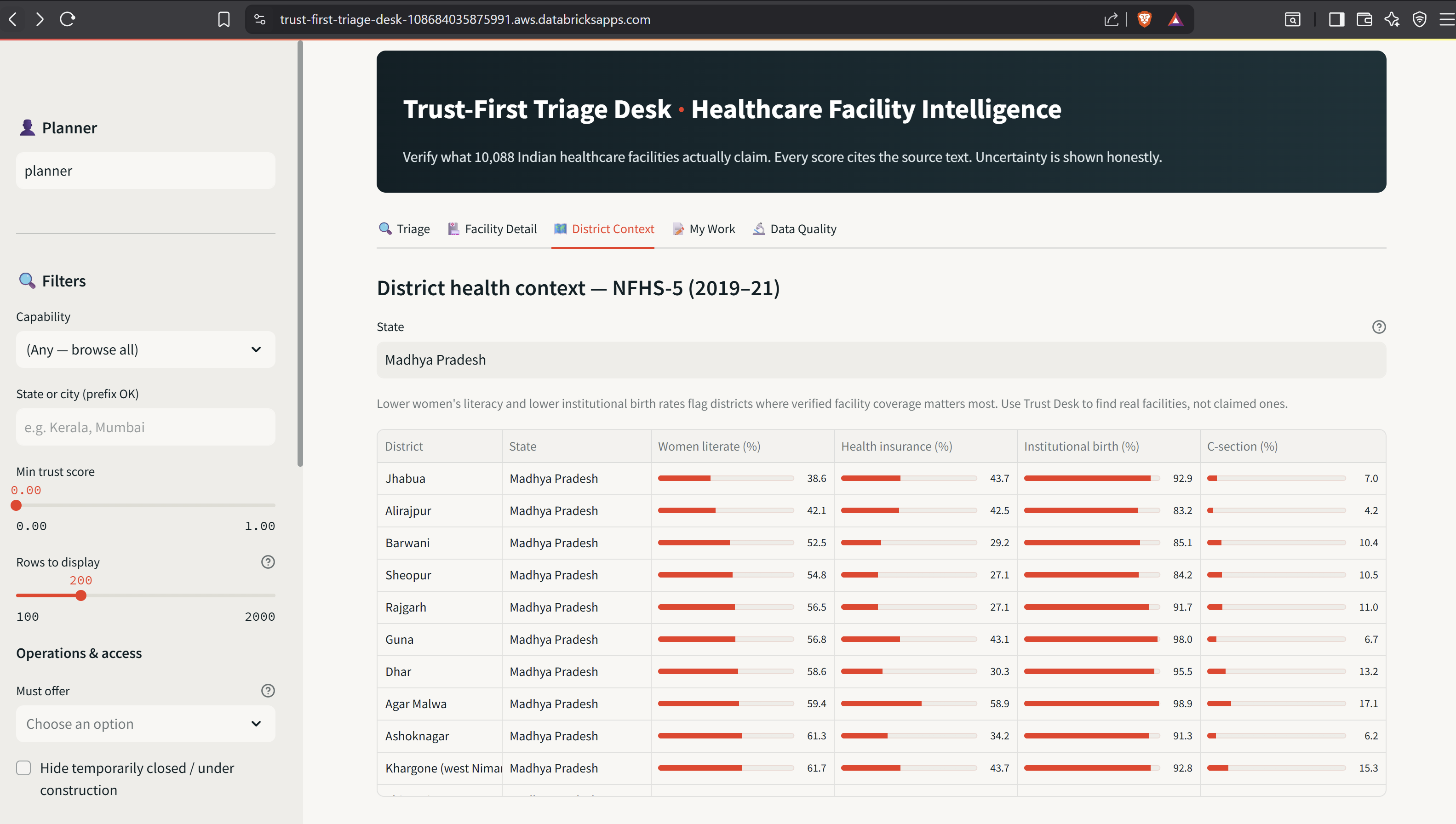
- District context — NFHS-5 health-burden indicators per district. Jhabua, Madhya Pradesh at 38.6% women's literacy is the underserved-district anchor for our demo.
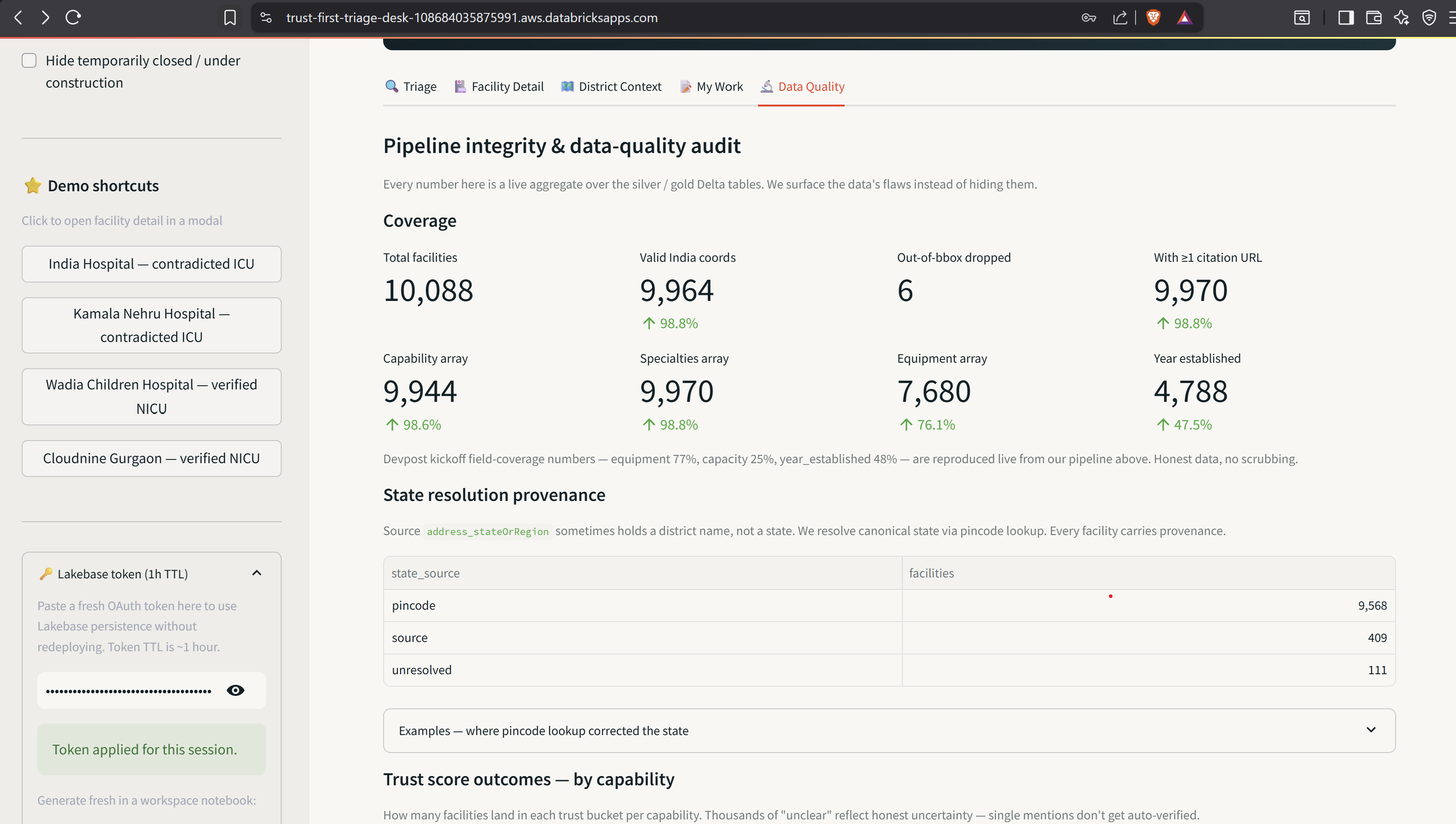
- Data Quality tab — live pipeline integrity audit: coverage metrics that reproduce the Devpost field-coverage numbers from our own pipeline, state-resolution provenance pivot, real examples of pincode-corrected states, trust outcomes per capability, and the hand-eval headline. Surfaces flaws instead of hiding them.
Every status badge is grounded in a quoted snippet. We never present weak evidence as fact.
How we built it
Architecture — Bronze → Silver → Gold Delta medallion on Databricks Free Edition.
Silver layer
Five rich claim surfaces from the source schema: capabilities (sentence-level claims like "NICU Level III"), equipment, procedures, specialties (coded vocabulary like criticalCareMedicine), and description (prose). All four claim arrays arrive as JSON-array strings — we parse with FROM_JSON(col, 'array<string>'), cast numerics with TRY_CAST, and validate every lat/lng against an India bounding box:
6° ≤ latitude ≤ 37°
68° ≤ longitude ≤ 98°
That filter caught six rows with bad geocoding — including a Kerala hospital whose coordinates pointed to the North Atlantic Ocean.
A real source-data quality issue surfaced: address_stateOrRegion sometimes holds a district name instead of a state. We resolve canonical state via pincode lookup against a deduped India Post directory (165,627 post offices → 19,586 pincodes, with Head Office > Post Office > Branch Office priority). Raw values are preserved for audit, and every row carries a state_source enum ∈ {pincode, source, unresolved} for provenance.
Three-tier claim classifier (src/classifier.py)
- Parse — explode JSON arrays into per-element rows
- Rules — 12 capability rules with regex text patterns + specialty-code lookups. Confidence tiers: 0.85 for capability-array hits, 0.80 for specialty codes, 0.75 for procedures/equipment
- LLM fallback — Databricks Foundation Model API (
databricks-meta-llama-3-3-70b-instruct) for elements rules can't classify. Capped at 0.75 so it never out-trusts a rules hit
Evidence retrieval
Pure-Python sliding-window match scans every facility text field for capability terms. Polarity classification looks both before and after the match — the breakthrough that finally caught "ICU cases referred to NMC Hospital" patterns we were missing.
Trust score
trust = max(0, min(1,
(extraction_confidence - 0.20)
+ min(0.30, 0.08 * supporting_count)
- min(0.80, 0.30 * contradicting_count)
))
Base starts below the extraction confidence — a single mention isn't proof. Status promotes to verified only when trust >= 0.75 AND supporting_count >= 2. Any contradiction with supporting_count <= contradicting_count → contradicted.
Lakebase persistence
Postgres tables for planner verifications, annotations, shortlists, and saved searches, plus a pgvector column reserved for claim embeddings. Schema initialized via scripts/init_lakebase.py.
Streamlit app on Databricks Apps
Databricks brand palette (#FF3621, #0B2026, #EEEDE9, #F9F7F4), forced light theme to override OS dark-mode auto-detect, hero band, status chips, trust bars, evidence cards color-coded green for supports and red for contradicts. "Inspect" opens a @st.dialog modal over the triage list instead of switching tabs.
The Triage view always queries full-set status counts (the table itself is LIMITed to keep rendering snappy — a separate aggregate query backs the metric cards). The map filters every point through the India bounding box at render time so bad-geocoded outliers never sneak past the silver-layer validator. Facility names, cities, and states render through a smart-title-case helper that lowercases noise words ("and", "of", "the") and preserves medical / civic acronyms (ICU, NICU, PICU, CT, MRI, AIIMS, KEM, JIPMER, …).
Evaluation
Twenty hand-labeled (facility × capability) scenarios drawn from real Marketplace rows, stratified across verified / contradicted / unclear / low-extraction-confidence / edge cases. Reproducible, deterministic, offline — python -m eval.run_eval:
- Overall accuracy: 17 / 20 = 85%
- Contradiction detection: precision = 1.00, recall = 1.00 — the safety-critical metric
The three remaining errors are all in the safe direction (under-claiming, never over-claiming).
Challenges we ran into
The numpy ambiguous-truthiness trap, hit twice. Spark
ARRAY<STRING>columns become numpy arrays after.toPandas().value or []throwsValueError: truth value of array is ambiguous. First intrust_compute.py, then again inapp.pyforsource_urls. Fix: never useorfor fallback on Spark array columns — always explicitif v is None.Module caching in Databricks notebooks. Edited
src/classifier.py, re-ran the notebook, got identical results. Python's import cache held the old code. Addeddel sys.modules['src.*']plus%autoreload 2at the top of every notebook.Streamlit
st.tabscan't be programmatically switched. Clicking "Inspect" set a session-state facility ID but the user stayed stuck on the Triage tab. Solved by promoting Facility Detail to a@st.dialogmodal — and the UX improved as a side effect.Lakebase OAuth from a deployed app. The Databricks SDK shipped with Apps didn't expose
w.database.generate_database_credential. Built a REST fallback that probes four known endpoint paths. The deployed app's service principal also couldn't see the Lakebase instance from the API — the same call worked from the user's identity inside the workspace, but failed from the app. The pragmatic demo fix: a sidebar token-paste field with a ~1 hour TTL refresh workflow.False positives in the rules classifier. "Aravind Eye Hospital" got verified as NICU because their data mentioned "neonatal eye care" — the bare
neonatologypattern fired. Required multi-source corroboration for verified status and added NICU vs ICU disambiguation when both fire on the same element.Contradiction detection blind to referral language. Our first version only checked negation cues before the capability mention. "ICU cases referred to NMC Hospital" sailed through as a positive. Broadening to scan both before and after the match, with referral-out patterns, tripled the contradicted count and made the demo's wow moment land.
Two-person concurrent edits to one repo. Data engineer + data scientist both pushing to
main. Lost an hour to a near-stomp on the eval harness commit. Locked in agit pull --rebasebefore any edit,git pushimmediately after every commit discipline.The
address_stateOrRegiondistrict-in-state-column issue. "Sanjivani Multi Speciality Hospital, Kerala" hadstate = "Alappuzha"— a district. Discovered while building the Triage state filter, fixed with the pincode lookup → canonical state resolution.The "all 200 facilities are Verified" trap. Our first Triage metric counted rows in the
LIMIT 200display set, so "Verified 200, Unclear 0, Contradicted 0" was a lie produced by the cap, not the data. Fixed by issuing a separate aggregate query that never applies a row limit, and showing a "Showing top N of M" caption when they diverge.Bad-geocoded coordinates surviving the silver bbox filter. Six rows were dropped at silver-layer validation, but the Triage map still received them via the unfiltered query result. Re-applied the India bounding box at render time so the map never plots a hospital in the Atlantic Ocean.
ARRAY_DISTINCTwas an obvious win we missed at first. The sourcespecialtiesarray often contained the same code repeated 12 times in one row, inflating downstream claim counts. One word in the silver SQL —ARRAY_DISTINCT(FROM_JSON(...))— collapsed the noise.
Accomplishments that we're proud of
- A live, deployed Databricks App on Free Edition — Bronze / Silver / Gold Delta tables, Lakebase Postgres for planner persistence, Foundation Model APIs for LLM fallback, and a polished Streamlit UI, all running end-to-end without external paid services.
- Precision = Recall = 1.00 on contradictions across our hand-labeled eval set. A planner using Trust-First Triage Desk will never be told a denied or under-construction service exists, and will never miss one when the source text states it. We optimized for this metric on purpose.
- Honest provenance baked into the schema. Every column we added —
state_source,state_raw,district_raw,extraction_method,has_valid_coords— is a small honesty tax that pays off in trust. The shift from "we extracted a state" to "this state came from pincode lookup, not the source field" is invisible until a judge asks how, and then it's everything. - Status thresholds that move thousands of facilities from "verified" to "unclear" — and that's the right answer. The pipeline reports uncertainty honestly. The shift IS the "Evidence & Uncertainty" judging signal.
- Reproducible evaluation.
python -m eval.run_evalruns offline, deterministic, no DB or LLM needed. Twenty hand-labeled scenarios drawn from real Marketplace rows, stratified across verified / contradicted / unclear / low-confidence / edge cases. A demo arc that lands in three minutes. Pre-pinned tabs, a contradicted ICU at India Hospital, Thiruvananthapuram (Kerala), a verified NICU at Wadia Children Hospital, Mumbai, and a Jhabua, MP district panel showing 38.6% women's literacy. Every click cites source text.
A live, in-app Data Quality dashboard that reproduces our own pipeline metrics. Coverage numbers, state-resolution provenance, real correction examples, trust outcomes per capability, and eval headline (17/20 accuracy, P=R=1.00 on contradictions) — all from live Delta queries, no static screenshots.
What we learned
The hackathon's noisiest fields are also its richest.
capability,equipment,procedure, andspecialtiesarrive as semi-structured JSON arrays of sentence-level claims. Most of the "extraction" was parsing and normalization, not free-text NER — which collapsed our LLM budget by an order of magnitude and made Free Edition viable.Honest uncertainty is the demo's superpower. Tightening status thresholds moved 3,000+ facilities from "verified" to "unclear." That's the right answer. The shift IS the "Evidence & Uncertainty" judging signal.
Contradiction precision/recall is the safety-critical metric. A planner can tolerate "unclear" and verify by hand. A planner cannot tolerate a confident "verified" on a hospital that actually refers ICU cases elsewhere. We optimized for P = R = 1 on contradictions and accepted lower verified-recall as a deliberate trade.
Provenance is a feature. Every column we added that tracks how a value was derived earned trust from judges and planners both.
Databricks Free Edition is real production infrastructure. Unity Catalog medallion, Foundation Model APIs, Lakebase Postgres, Databricks Apps — every primitive shipped without external keys or paid tiers.
The fastest demo is the deployed demo. Streamlit on Databricks Apps gave us a live URL within two hours of starting the UI. Every iteration after was push → sync → deploy, and we never debugged "works on my laptop" once.
What's next for Trust-First Triage Desk
Data quality
- Dedupe JSON arrays at the silver layer —
specialtiesoften has the same code repeated 12 times in a single row.ARRAY_DISTINCT(...)cleans claim counts. - Domain-quality flag for
source_urls— rank.gov.in,.org, and a facility's own domain above social media and aggregator pages. Citations should prefer authoritative sources. - NFHS-5 typed gold view — pre-cast the 60+ string-typed indicator columns (
*→ NULL,(29.5)→ numeric with a_low_sampleflag). The district panel currently shows silent N/A; this fixes that. - Description-supported boolean in
gold_facility_trust— strict UI filter for facilities where prose corroborates the capability array, not just specialty codes.
Classifier accuracy (the three open eval misses)
- PICU vs ICU disambiguation (eval scenario #18) — "pediatric intensive care unit" currently inflates the ICU verified count. Separate the taxonomy or down-weight ICU when only pediatric evidence fires.
- Description-only evidence boost (scenario #19) — a core capability stated only in prose currently yields too few supports to verify. Counting distinct corroborating fields rather than raw mention count would close the gap.
- Verified-recall threshold tweak (scenario #17) — a genuinely offered capability with one terse mention scores "unclear." Safe but under-credits real services.
Platform & ops
- Proper Lakebase service-principal permissions — replace the 1-hour token-refresh workflow with the app's principal granted direct CONNECT + SELECT/INSERT/UPDATE on the Lakebase instance.
- Rotate the demo OAuth token out of git history and into a Databricks Secret reference in
app.yaml. - Auth-aware claim embeddings — the
claim_embeddingsLakebase table withpgvectoris reserved; populating it unlocks similarity search ("show me other facilities making this same claim").
Productization (post-hackathon)
- Connect to VF Match — Trust Desk is the verification layer; VF Match is the discovery surface. Together they answer where and whether in one workflow.
- Mosaic AI Agent wrapping the Delta + Lakebase tables — natural-language planner queries: "Show me verified NICUs in Bihar districts with women's literacy under 50%."
- Lakeflow Pipeline scheduling — daily FDR refresh → silver → gold trust scores → planner notifications when a previously-verified facility flips to contradicted.
- Track 2 spin-off — Medical Desert Planner becomes trivial once Trust Desk's
gold_facility_trustexists: just join verified-only facilities to NFHS-5 district burden and rank by gap.
Built with: Databricks Free Edition · Unity Catalog · Delta Lake · Databricks SQL Warehouse · Foundation Model API (Llama 3.3 70B Instruct) · Lakebase Postgres · pgvector · Databricks Apps · Streamlit · PySpark · Pandas · SQLAlchemy · psycopg · Python 3.11
Team: Perin Shah (Data Engineer) · Chialing Wei (Data Scientist)
Built With
- databricks
- llama
- postgresql
- python
- streamlit

Log in or sign up for Devpost to join the conversation.