
Inspiration
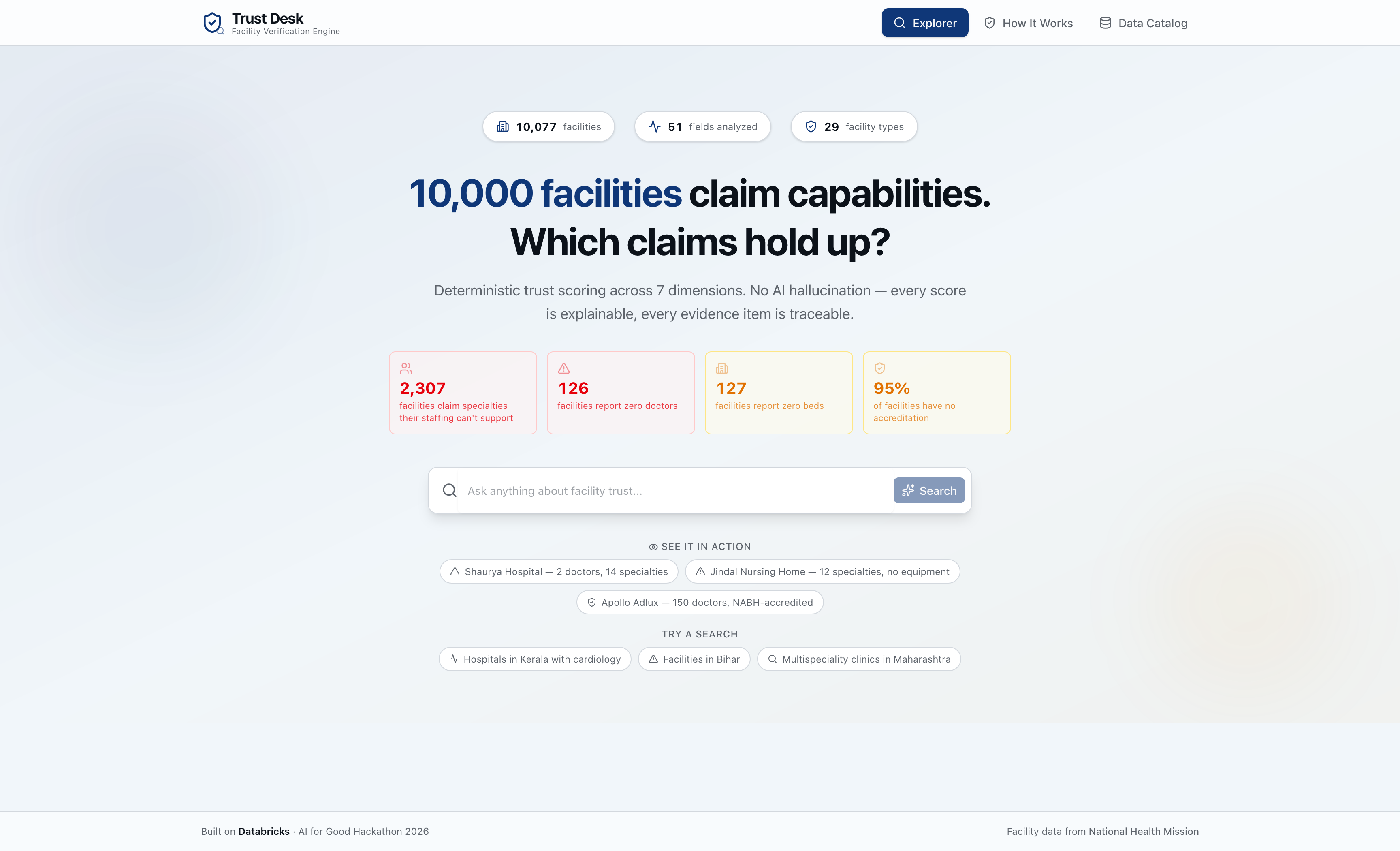
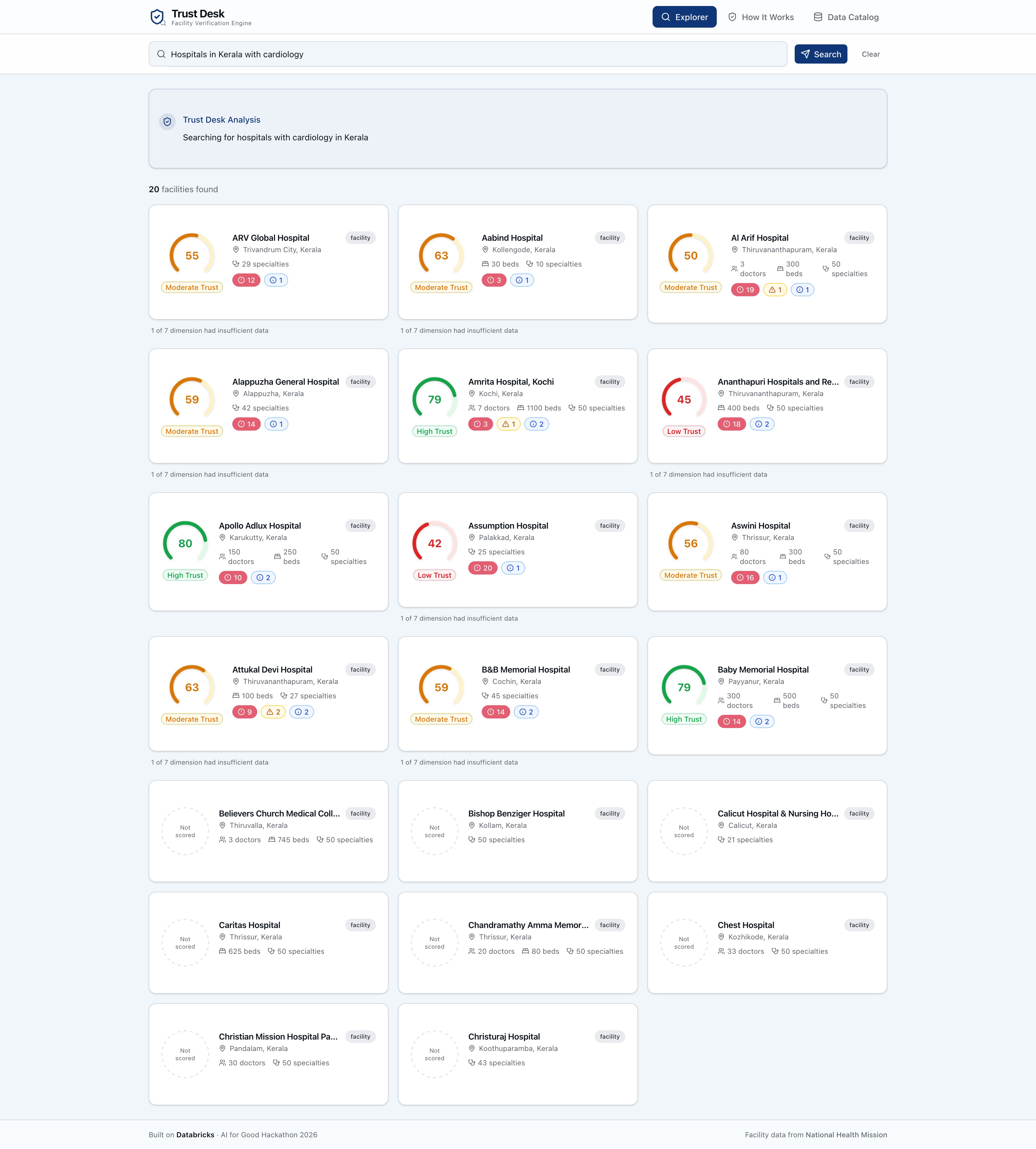
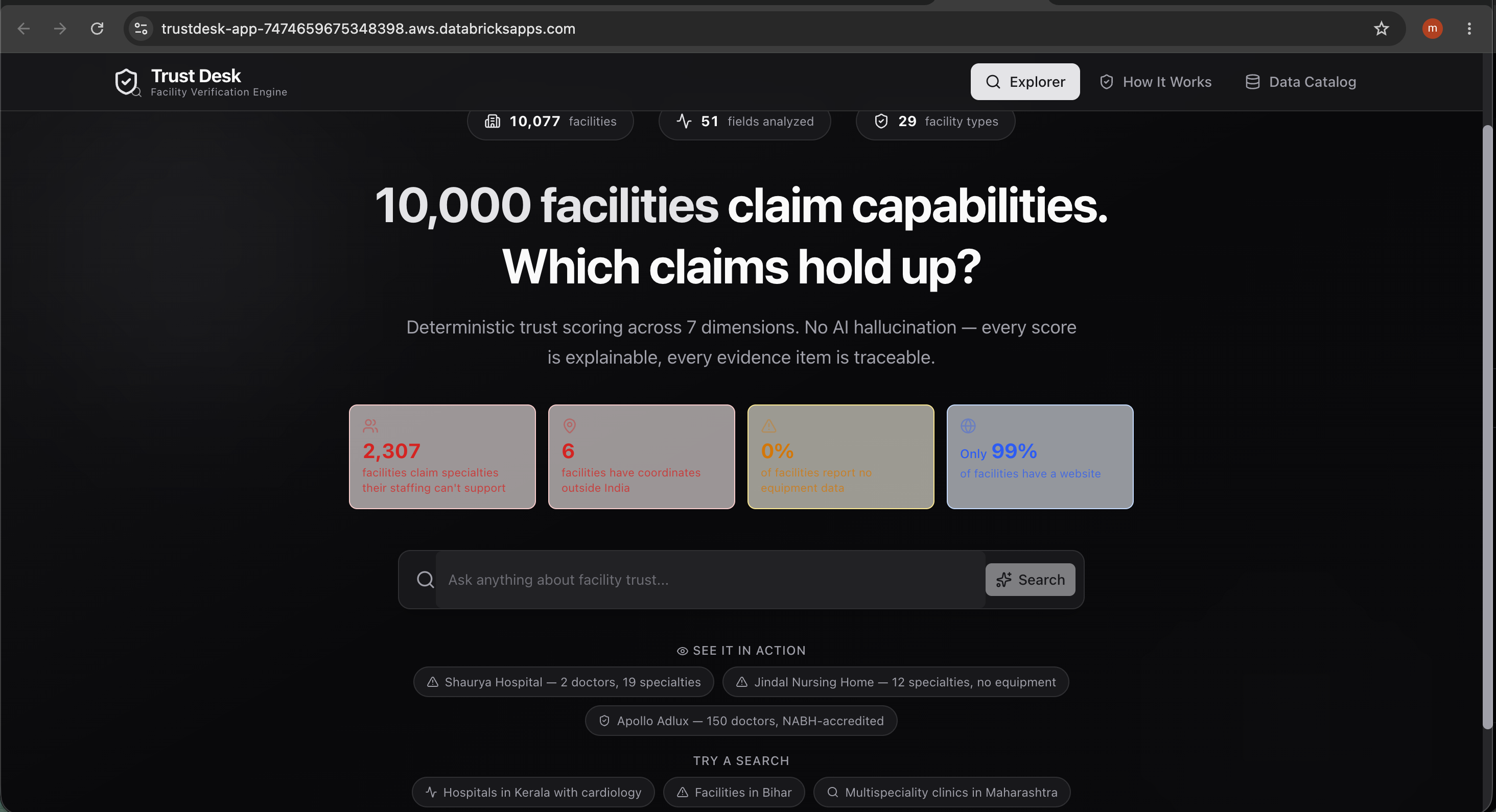
India has over 10,000 registered healthcare facilities — but registration doesn't mean trustworthy. A clinic can list 19 medical specialties while employing only 2 doctors. A hospital can claim to be in Kerala while its coordinates place it in the North Atlantic Ocean. A facility can advertise NABH accreditation it never received.
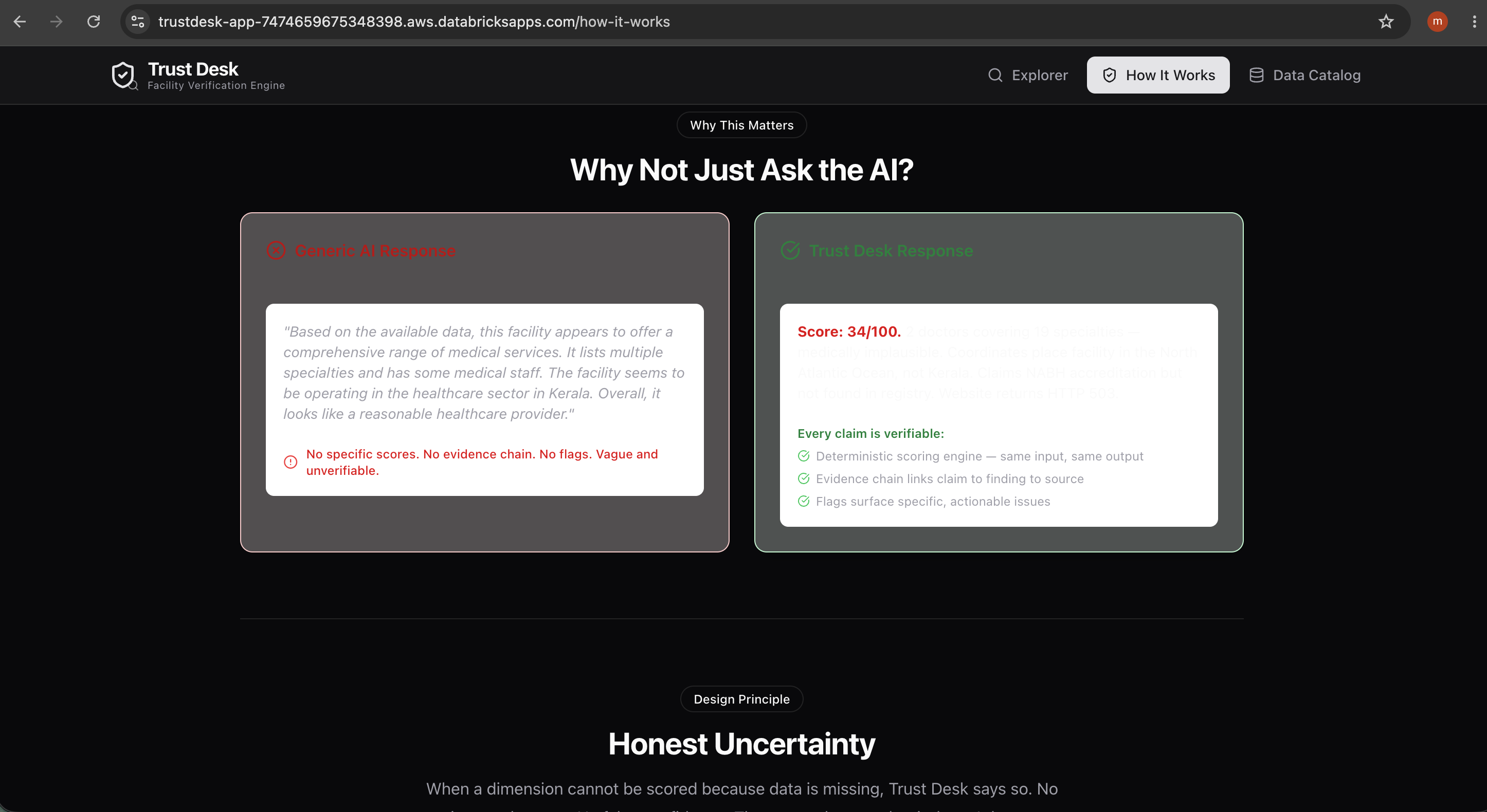
Healthcare planners, insurers, and patients have no scalable way to verify these claims. Asking a generic AI "Is this hospital trustworthy?" gets you a confident-sounding paragraph that's completely unverifiable. We wanted to build something that treats trust as a measurable, evidence-backed quantity — not a vibe.
What it does
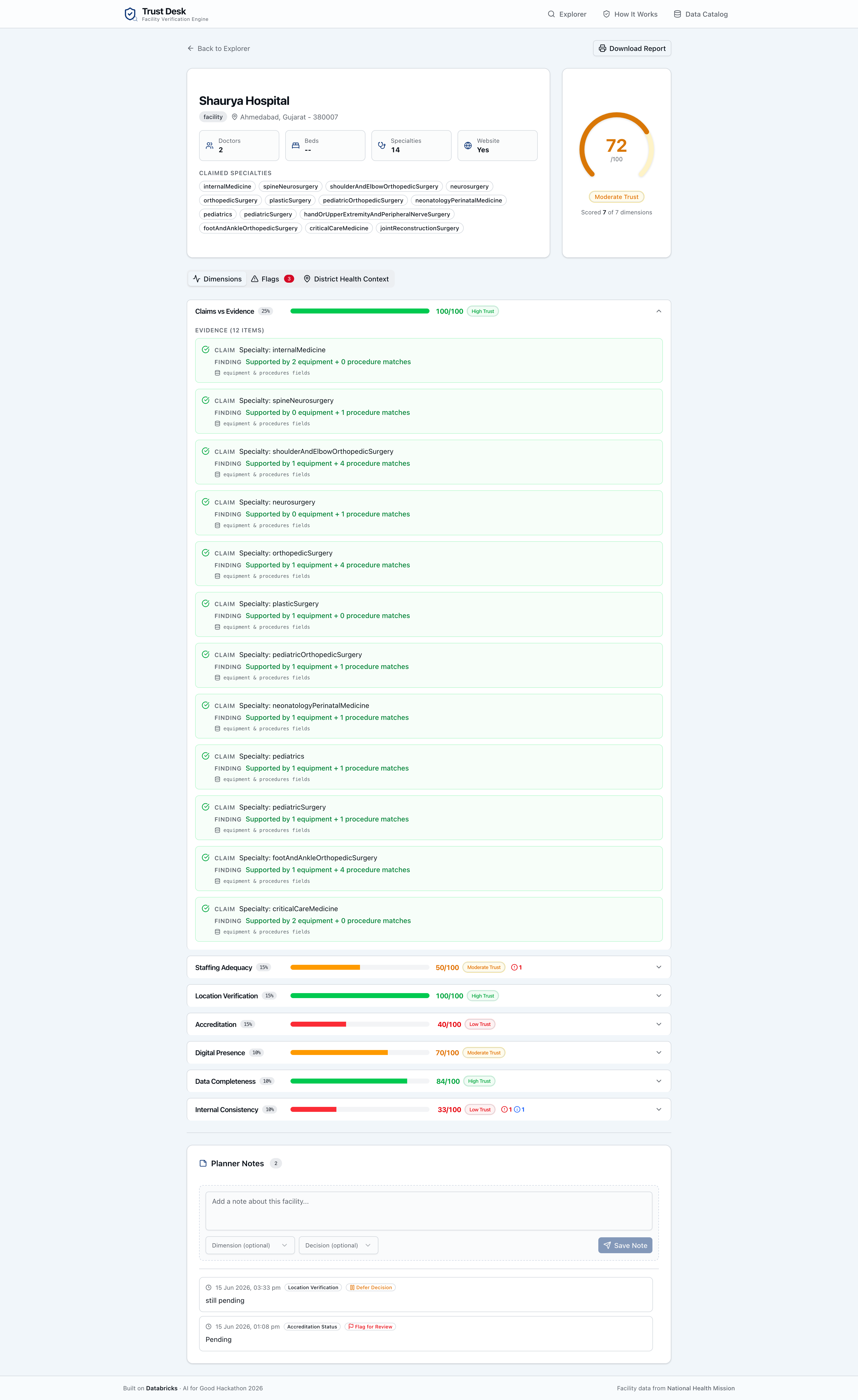
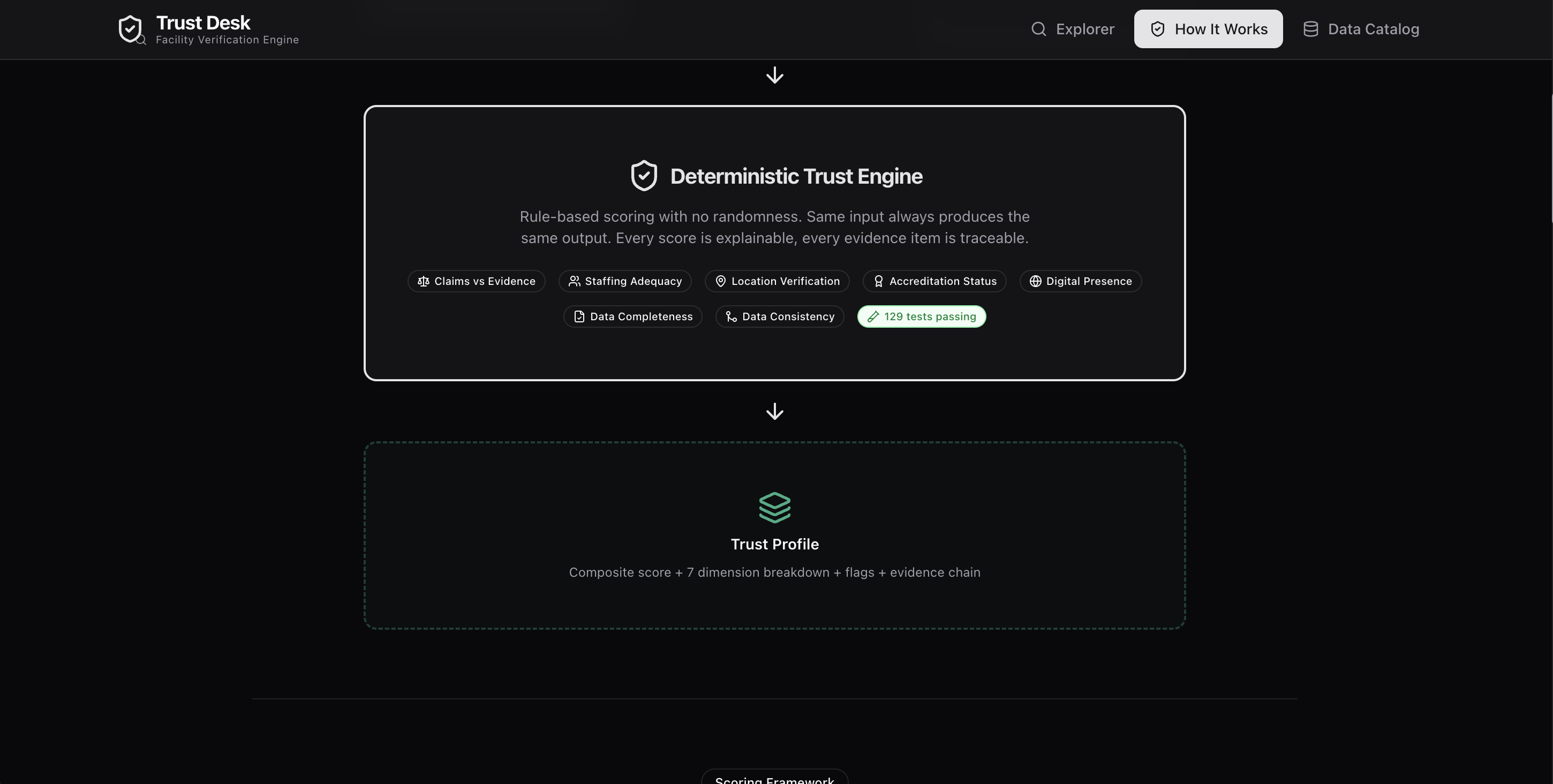
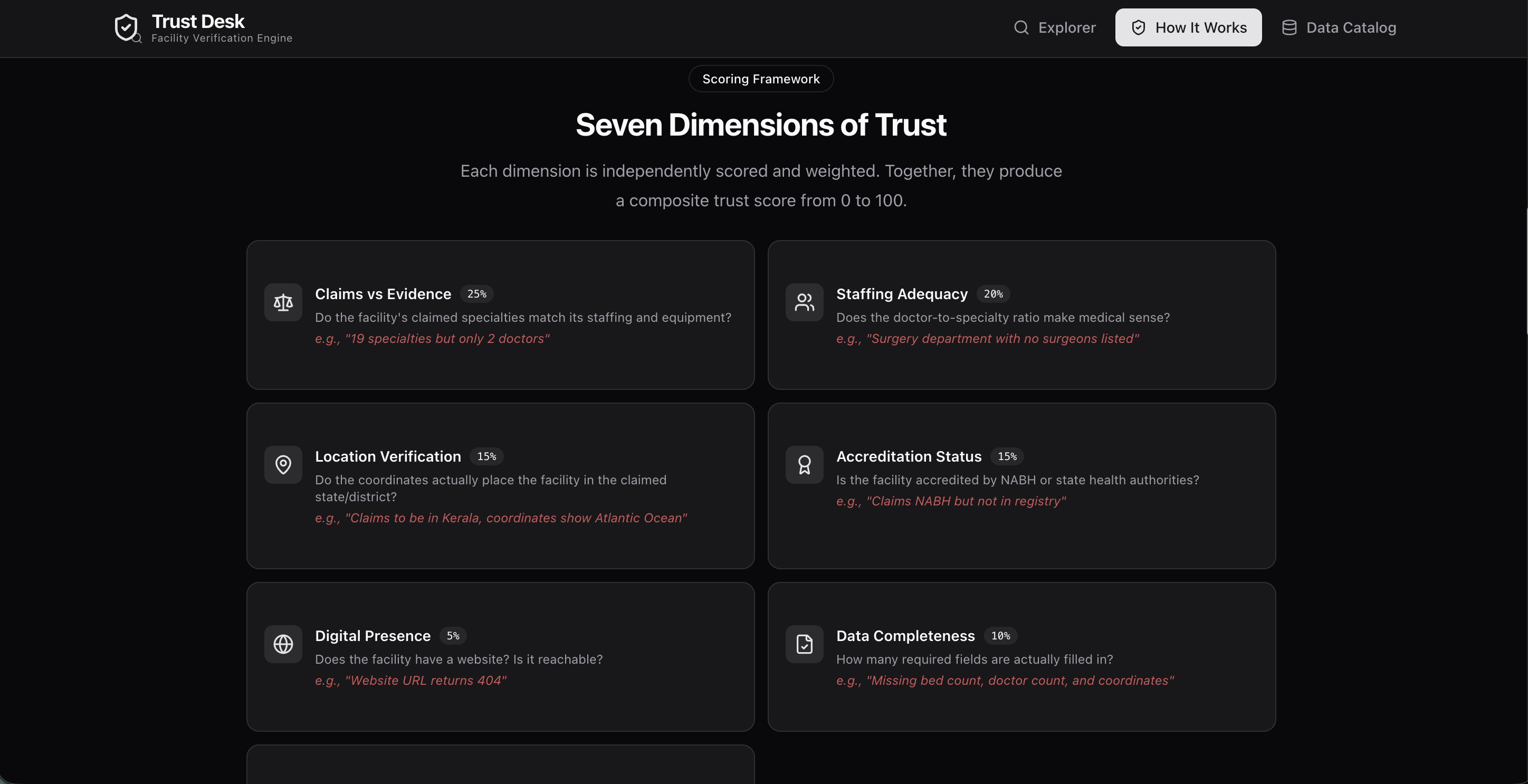
Trust Desk ingests messy, real-world facility records and runs every one through a 7-dimension deterministic trust engine:
| Dimension | What it catches |
|---|---|
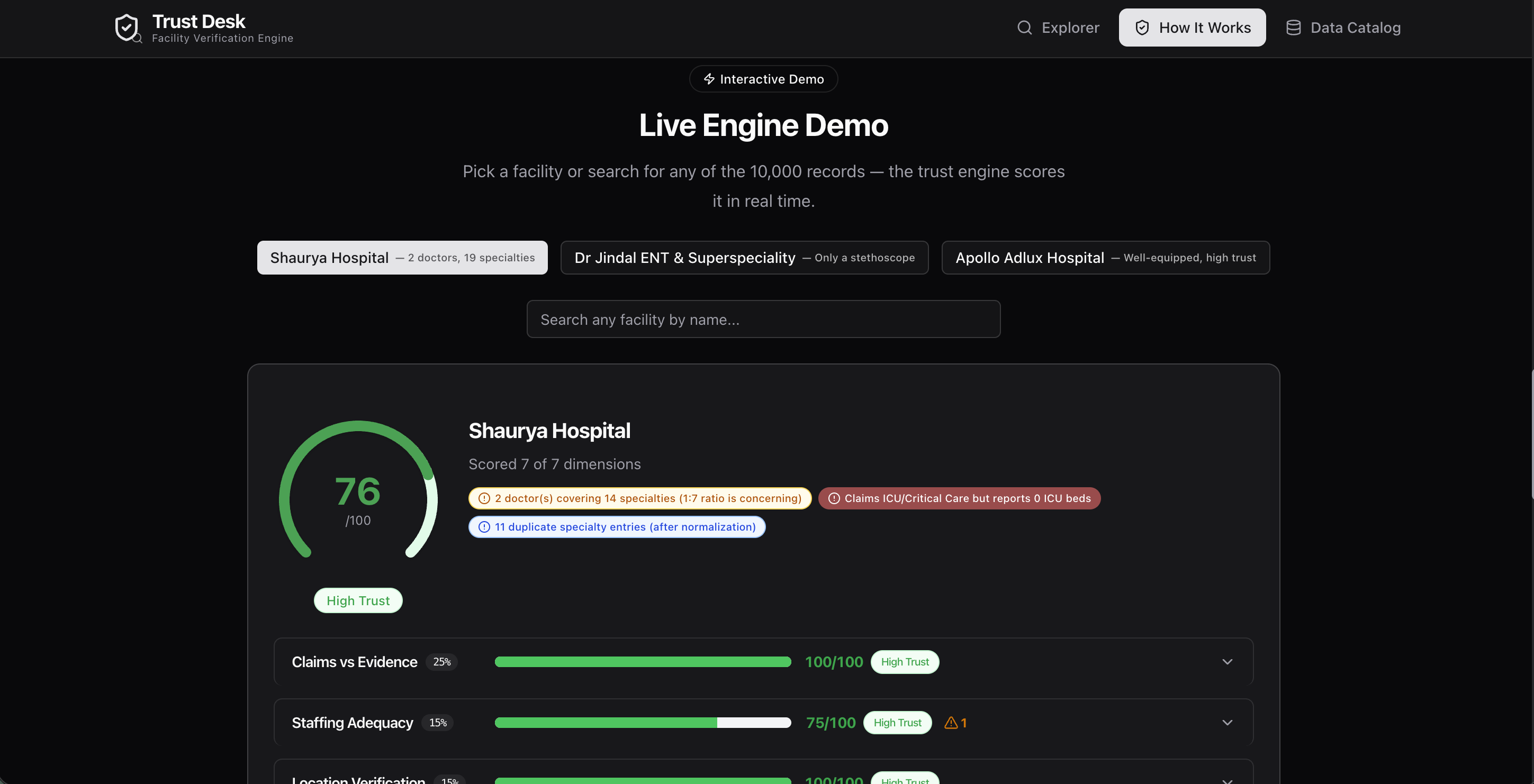
| Claims vs Evidence | 19 specialties but only 2 doctors — medically implausible |
| Staffing Adequacy | Surgery department with no surgeons listed |
| Location Verification | Claims Kerala, coordinates show the Atlantic Ocean |
| Accreditation Status | Claims NABH but absent from registry |
| Digital Presence | Website returns HTTP 503 |
| Data Completeness | Missing bed count, doctor count, and coordinates |
| Internal Consistency | 500 beds but listed as "clinic" |
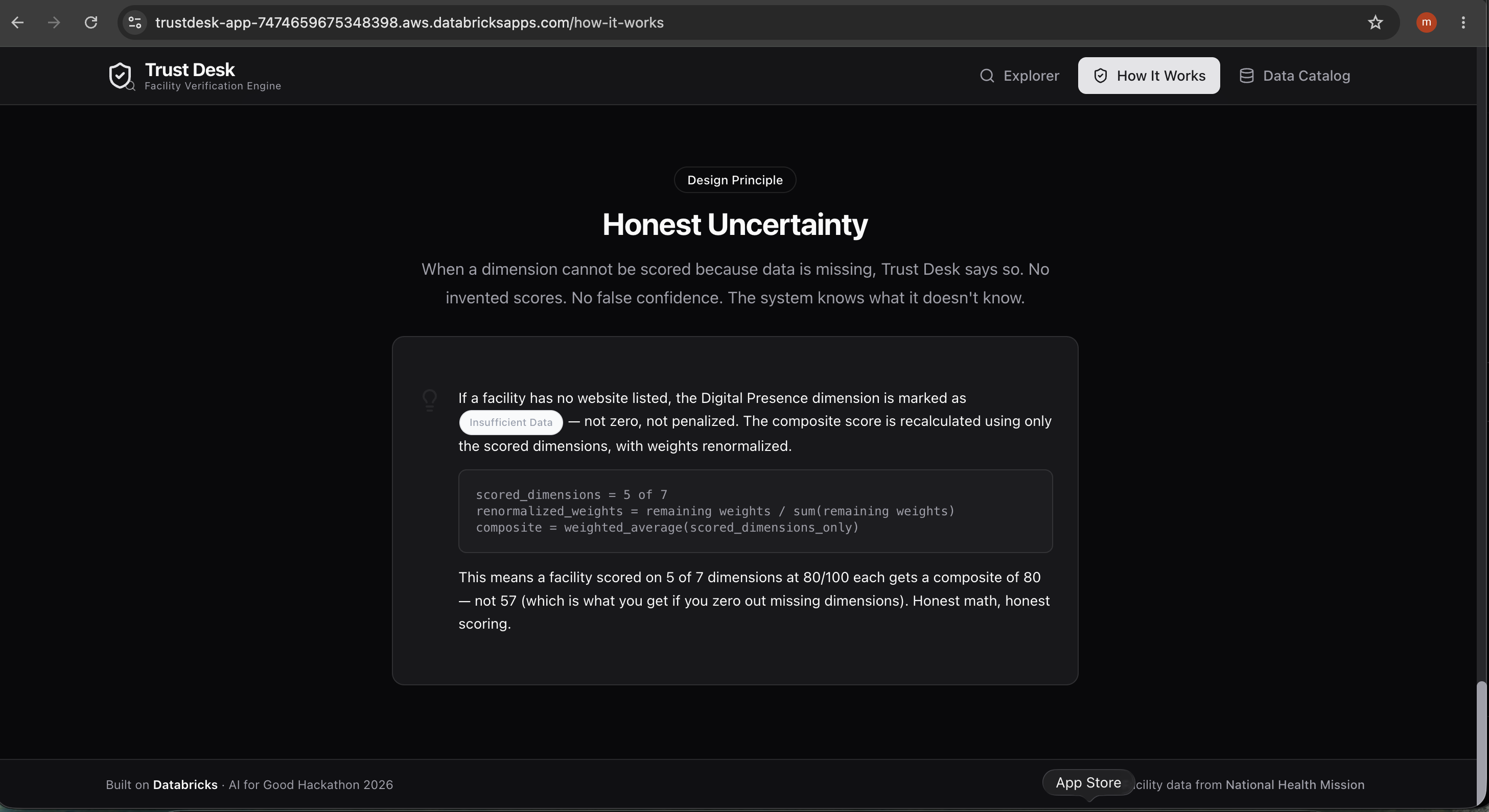
Every score comes with an evidence chain — the claim, the finding, whether it's supported, and the data source. Every flag is specific and actionable. When data is missing, the system says "insufficient data" instead of guessing. Honest uncertainty, not false confidence.
Users can search all 10,000 facilities via natural language chat, compare trust profiles side-by-side, and explore the full scoring breakdown with expandable evidence items.
How we built it
Architecture — the key design decision: The LLM reads language. The engine decides trust. These are never mixed.
- LLM layer (Databricks Foundation Model Serving): Extracts structured intent from natural-language queries, normalizes messy specialty names (e.g.,
reproductiveEndocrinologyAndInfertility→obstetrics & gynaecology), and powers the conversational search interface. It never scores, ranks, or assesses trust. - Deterministic Trust Engine (pure TypeScript functions): 7 scoring dimensions, weighted composite, flag generation — all rule-based. Same input, same output, every time. 129 unit tests verify this.
- Specialty normalization: 404-entry synonym map + 126 keyword-based fallback rules + camelCase-to-words conversion. LLM-informed design, but deterministic at runtime — zero hallucination risk.
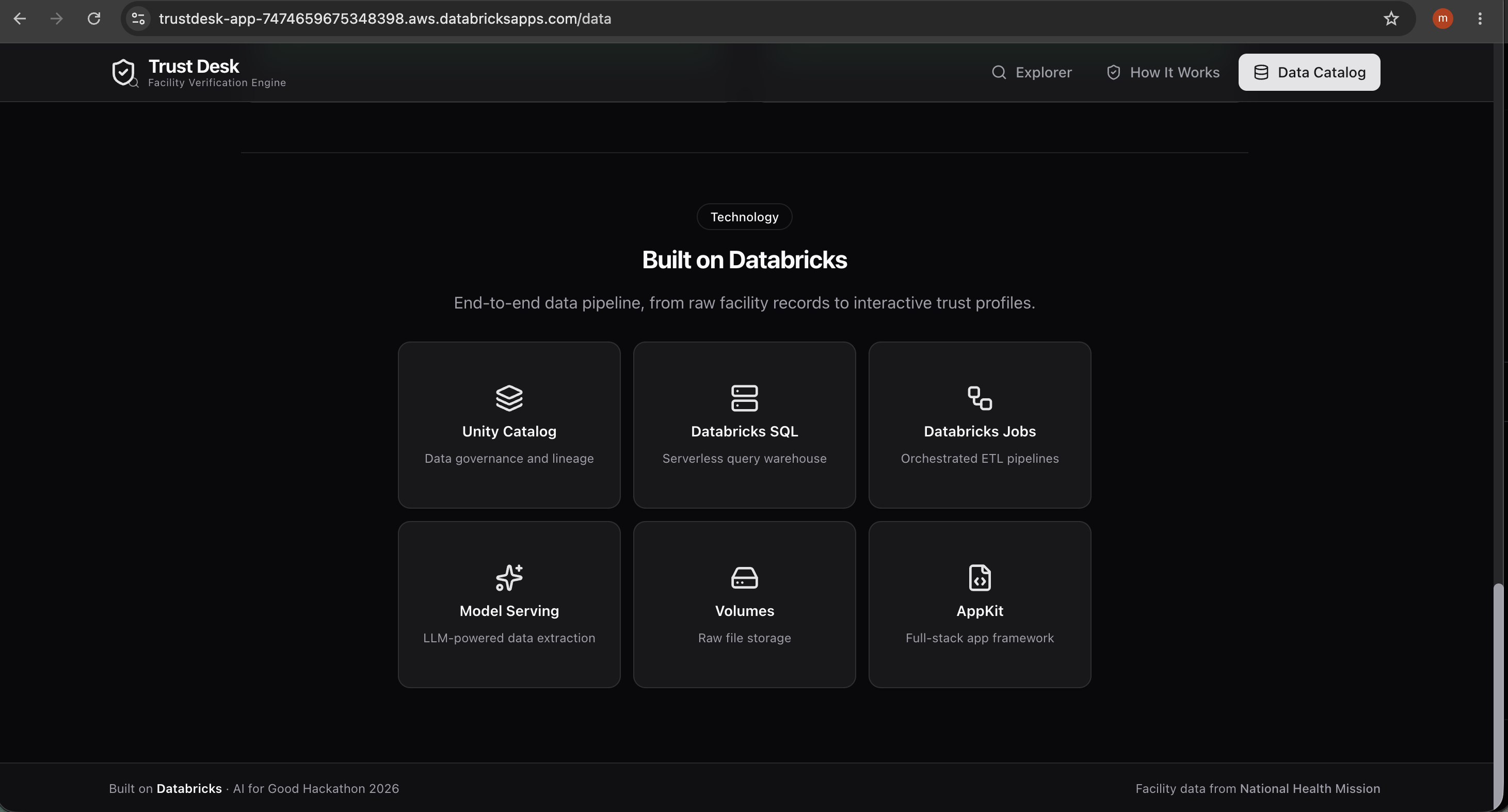
Stack:
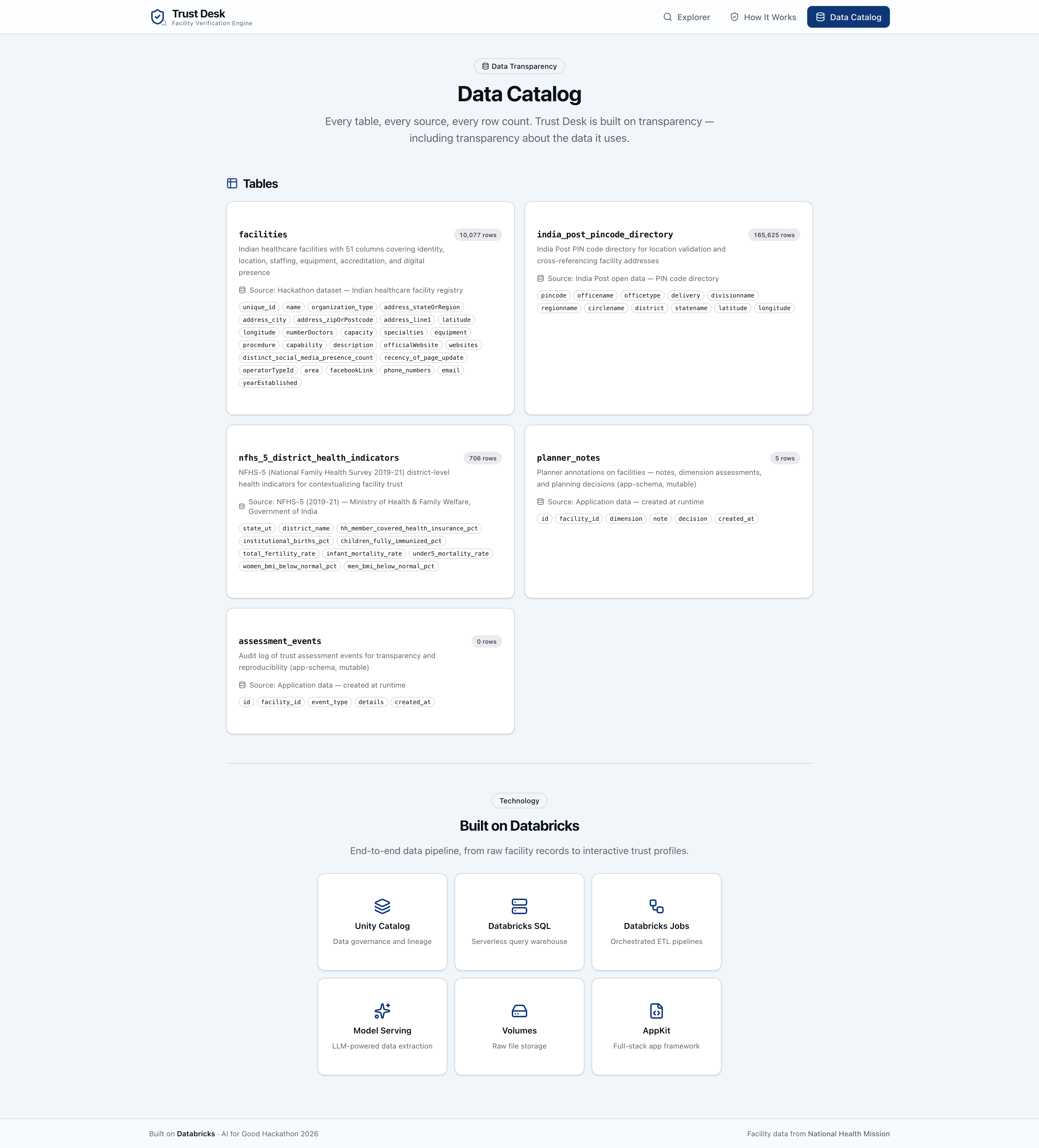
- Databricks AppKit — full-stack TypeScript framework
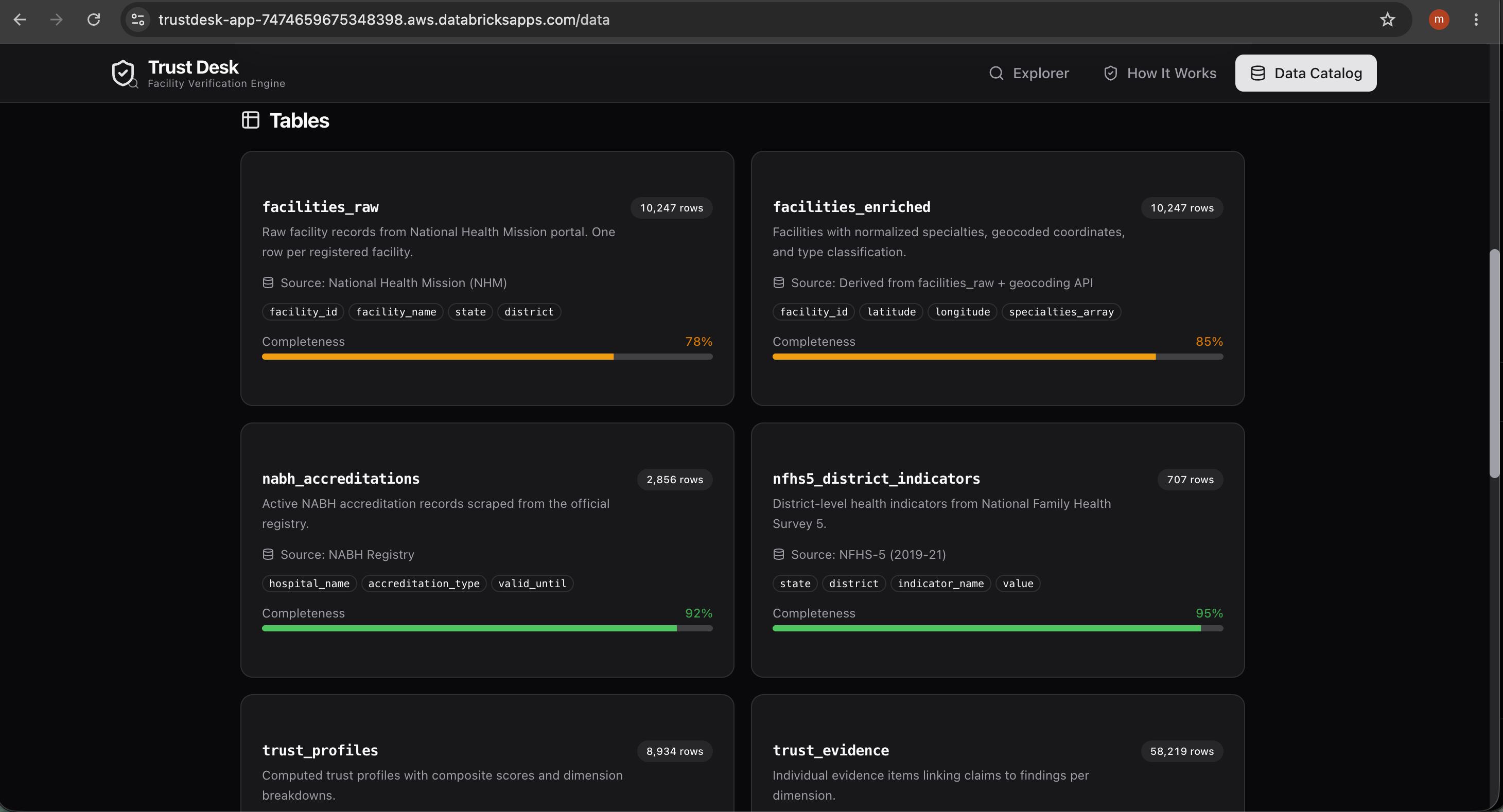
- Unity Catalog —
trustdesk.app.facilities(10K records, 51 columns) - Lakebase — serverless Postgres synced from Delta tables via SNAPSHOT
- Foundation Model Serving — intent extraction and chat
- React + Tailwind — responsive UI with trust gauges, expandable evidence, and print-ready reports
Challenges we ran into
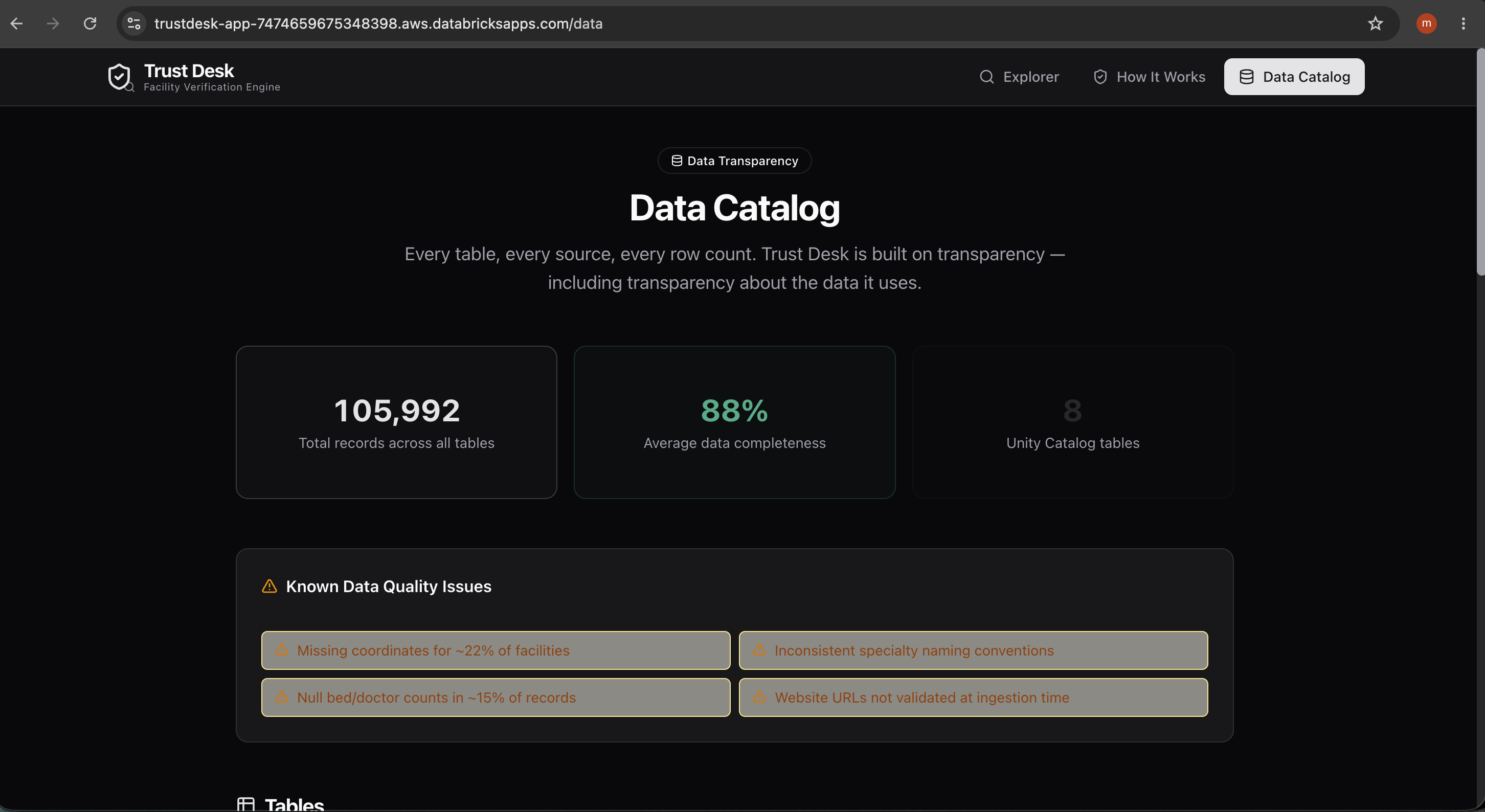
The specialty problem was harder than expected. Indian healthcare facilities list specialties in every format imaginable — camelCase (pediatricGastroenterology), abbreviations (ENT), British spellings (paediatrics), compound terms (obstetrics and gynaecology), and outright garbage data. We initially tried LLM-based normalization at runtime but abandoned it — too slow, non-deterministic, and the prompt escaping broke JSON parsing. The solution was LLM-informed, deterministic-at-runtime: we used the LLM to help design the rules, then hardcoded them. 62% of 2,909 unique specialty strings now resolve correctly; the remaining 38% are legitimately not specialties (procedures, conditions, allied health roles).
Search seemed broken for entire states. Bihar returned zero facilities despite having records. The bug: SQL ILIKE filters were doing exact matches (ILIKE 'Bihar') instead of wildcard matches (ILIKE '%Bihar%'). A two-character fix (% wrappers) across two files.
Balancing coverage vs. correctness. The trust engine can only be as good as its reference data. We had to decide: is it better to score a dimension with imperfect heuristics, or mark it "insufficient data"? We chose honesty — if we can't defend the score, we don't produce one.
Accomplishments that we're proud of
- Zero hallucination by design. The LLM never makes a trust judgment. Every score traces to a deterministic rule, every evidence item cites a data source. This isn't a guardrail — it's architecture.
- Real findings from real data. Sanjivani Hospital's coordinates in the Atlantic Ocean, Shaurya Hospital's 2-doctor/19-specialty ratio, Dr. Jindal's entire practice equipped with only a stethoscope — these aren't demo data. They're the actual 10,000 records, and the engine finds these issues automatically.
- 129 passing tests on the trust engine. Determinism isn't just claimed — it's proven.
- Honest uncertainty. When data is missing, the composite score renormalizes weights across only the scored dimensions. A facility scored 80/100 on 5 of 7 dimensions gets an 80 — not a 57 from zeroing out unknowns.
- The live demo page lets judges score any of the 10,000 facilities in real time — not canned examples, real API calls to the real engine.
What we learned
- Separating AI from decisions is a superpower. The moment we drew a hard line — LLM for language, engine for trust — the entire system became testable, explainable, and auditable. This pattern (which we call "LLM reads, engine decides") should be the default for any high-stakes AI application.
- Messy data IS the product. We spent the first hours trying to clean the data. Then we realized: the messiness is the signal. A facility with garbage coordinates isn't a data quality problem — it's a trust problem. The engine's job is to surface that, not hide it.
- Deterministic doesn't mean simple. 404 specialty synonyms, 126 keyword rules, PIN-code-to-state validation, coordinate boundary checks, IPHS staffing norms — building a "rule-based" engine still requires deep domain knowledge. The rules are the hard part.
- LLMs are best when they inform design, not runtime. Our best use of the LLM wasn't at runtime — it was during development, helping us classify 2,909 specialty strings into canonical categories that became deterministic lookup tables.
What's next for Trust Desk
- Cross-reference external registries — validate NABH/state accreditation claims against live registry APIs instead of text matching
- Temporal trust tracking — score facilities over time as data updates, surfacing trust trajectory (improving, degrading, stale)
- Vector search — semantic facility search using GTE-Large embeddings for queries like "hospitals that might be inflating their specialty count"
- District health context — overlay NFHS-5 indicators to contextualize trust scores (a low-trust facility in an underserved district has different implications than one in a well-served metro)
- Planner collaboration — multi-user annotation layer so health planners can flag, annotate, and track facilities through review workflows
- Export and reporting — PDF/CSV export of trust profiles for regulatory submissions and audit trails
Built With
- databricks-appkit
- databricks-rest-api-libraries:-lucide-react
- databricks-sql-warehouse-databases:-lakebase-(serverless-postgres)
- databricks-unity-catalog-cloud-services:-databricks-foundation-model-serving
- delta-lake-apis:-databricks-sdk
- languages:-typescript
- python
- sql-frameworks:-react
- tailwind-css
- vite
- vitest-platforms:-databricks-apps

Log in or sign up for Devpost to join the conversation.