
Inspiration
For ages now, photographic evidence has been the pinnacle of definitive proof.
Want to prove that someone robbed your store? Show us the security camera footage.
Hear about a scandalous celebrity affair? Look up the photos on TMZ.
Or are you referencing something a political candidate has said in the past? Bring up the tapes.
As the saying goes: I'll believe it when I see it. So what happens when you shouldn't believe what you see?
The emergence of artificially-generated images called deepfakes presents a disturbing trend with deep cybersecurity impacts. Artificial Intelligence has made it easier than ever to manipulate photographs into showing things that were never even real, and some are using that power maliciously.
Misleading and manipulated media has enormous power to shift public opinion. Everything could be at stake here- from fair democratic elections to the integrity of our courtrooms and social media platforms.
Fake photographic proof could be submitted to a court case, creating a false conviction. Or perhaps a manipulated video of a political candidate saying outlandish things could go viral on social media- causing voters to lose confidence, and tip the scales of an elections. This problem has the potential to wreak havoc on our society as a whole.
Naturally, we wanted to design a solution that could reinstate confidence in the authenticity of photographs on the internet. We believe we have done just that.
What it does
Many have tried to create algorithms to detect the presence of deepfakes with varying degrees of success. Personally, our team believes that this method of attack is futile. Deepfakes are created with GAN's, which simply get better over time with more training data. Soon enough, deepfakes will be completely indistinguishable from real images. What to do then?
Our solution attacks this problem before a deepfake can even get involved. Here's what it does:
When a user knows they want to take a photograph that they would like to be verified as authentic, they open our TruShot mobile app. They take the photo and we immediately upload it to our server.
Then, the user is given a 6 digit "ID". This "ID" corresponds to the image they just took.
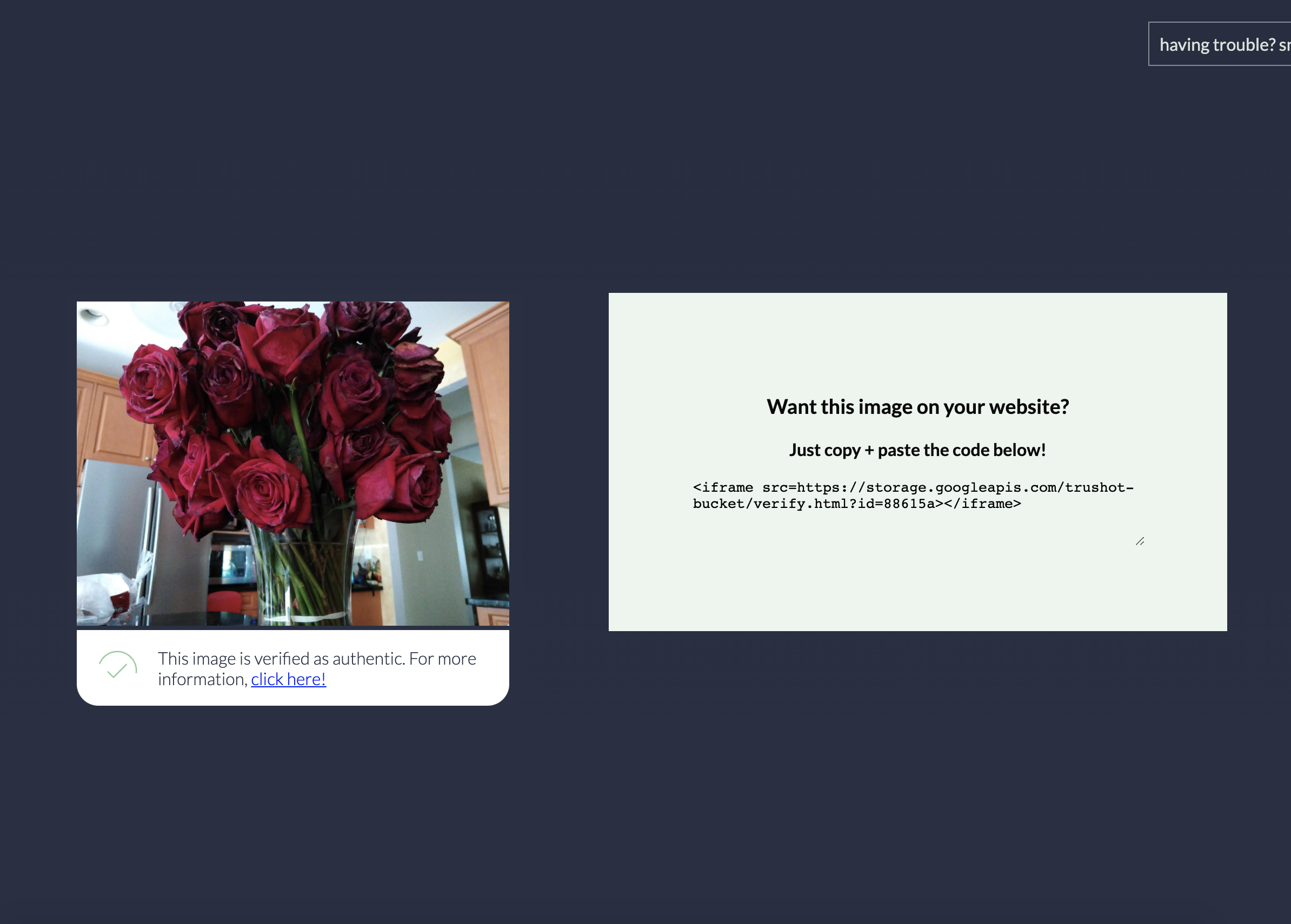
Next, the user navigates to our website. On our home page, they can enter the ID.
From there, our website shows the image, along with a banner that verifies that it's authentic. We know it's authentic because it came from our server, and the only way to get onto that server is to upload straight out of the camera on our mobile app.
From that landing page, the user can copy an "embed code" that they can use to embed the image and banner into their website. We can see this embed mechanism be used in news articles, blogs, or even become integrated into twitter to automatically show our banner.
How we built it
The project can be broken down into four distinct parts: Backend, Web App, Mobile App, & Embed Code Generation
Mobile Application - built with Flutter
The mobile application was built with Flutter and was the entry point to our deepfake prevention pipeline. The app utilizes the device's camera and when the picture is taken, it is sent to the backend where the image is processed and passed onto the next part of the pipeline. After a picture is taken, it will show the image and the key for that respective image so that the user can utilize on the web app.
Backend: Google Cloud Application Engine & Cloud Storage - built with Python
(this is how we used google products and why) The backend was the glue between the web application and the mobile application. We exposed a REST Service to the mobile app so that the phone could communicate with the Google Cloud Application Engine. We using Python and the FastAPI Library which supported multipart/form-data POST requests. From the mobile app, the image was base64 encoded and sent to the server where it would be decoded into an image and stored in a Google Cloud Storage bucket with a unique identification string. When a picture is taken on the mobile application, the image is successfully stored in the Google Cloud Storage bucket. The unique identification string is used to generate the iframe which is handled by the web application.
Web App - built with HTML, Javascript, and CSS
The web application is one of the most essential parts of this process. Without it, and your picture will just sit on a server, inaccessible. To make it, we used a Javascript-enabled text box to receive user input. Then, we passed that input into an iFrame embed template, which rendered the photo (using the code described next). Finally, we wrapped it all up with a neat bow, using CSS to create a wonderfully minimalistic design.
Embed Code - built with HTML, Javascript, and CSS
The embed code is the part that actually used a URL parameter to call the image down from the server. We used a parameter called id to pass the id to the javascript. Then the javascript gets the image, and if the image exists, it displays a verified banner. If it doesn't, it displays "something went wrong!"
Challenges we ran into
Backend Challenges - Rohan
Overall the biggest challenge for us was learning the ropes of Google Cloud because I had previously used AWS for another project that I had been using previously. However, Google Cloud's extensive documentation was very helpful because I was able to find the Google Cloud Platform Service I needed for our use case. Another challenge in the backend was working with receiving and uploading images to the Google Cloud Storage bucket. Some of the terminologies that were in the Developer Documentation were very foreign to me but the extensive code samples definitely helped to clear up the confusion. By the end of the competition, I was confident in setting up GCP services and APIs and interfacing Python with those services and APIs respectively.
We also had a lot of issues with the domain name. Abdullah spent an hour with the support staff for domain.com and eventually we found a way to host our website that was different from how we set out to do it. In the end, however, it worked.
Accomplishments that we're proud of
We are super proud that we finished this project. We paced ourselves well and got it done before the deadline. I think that it's a testament to how much we've all learned over the past year- there was a lot less friction and stressful issues than at the previous hackathons we participated in. We're also proud of the sleek design that we employed. We chose a color scheme and we stuck to it.
What we learned
We learned how to pass parameters through javascript, which was certainly a new skill for us. We also learned how to set up and use google cloud. These challenges were formidable, but we quickly learned and implemented all of them.
What's next for TruShot - Fighting deepfakes at their roots
We think that embedding this in social media platforms like twitter would really help users trust the authenticity of images.
Built With
- css
- dart
- fastapi
- flutter
- google-cloud
- google-cloud-app-engine
- html
- javascript
- python
- rest





Log in or sign up for Devpost to join the conversation.