-
-
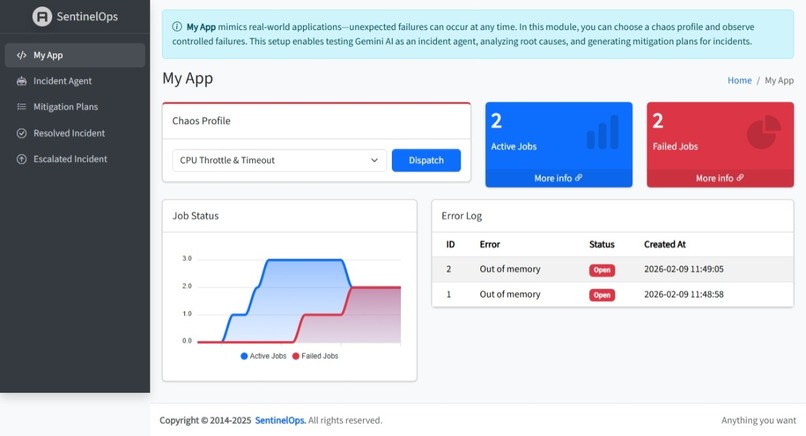
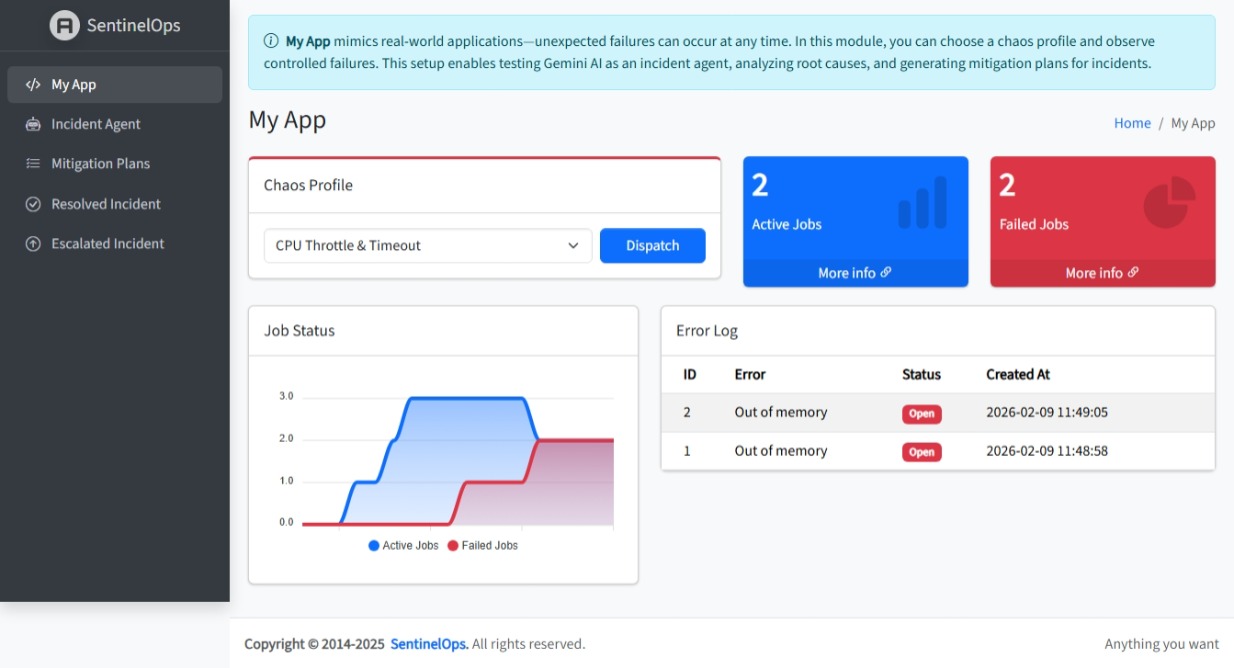
My App serves as real-world Application Software
-
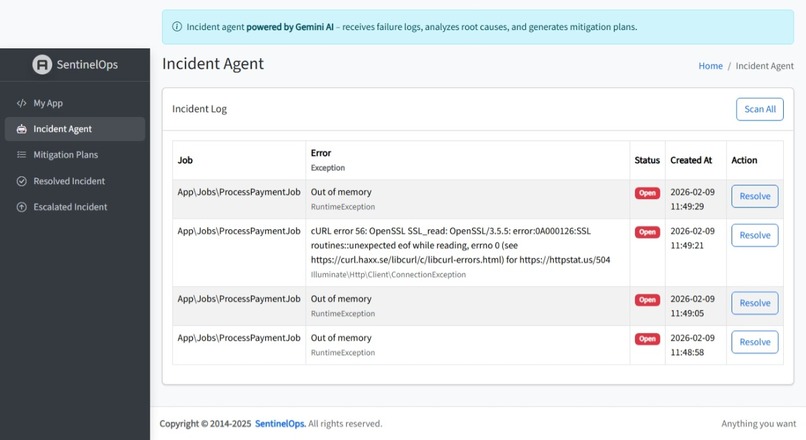
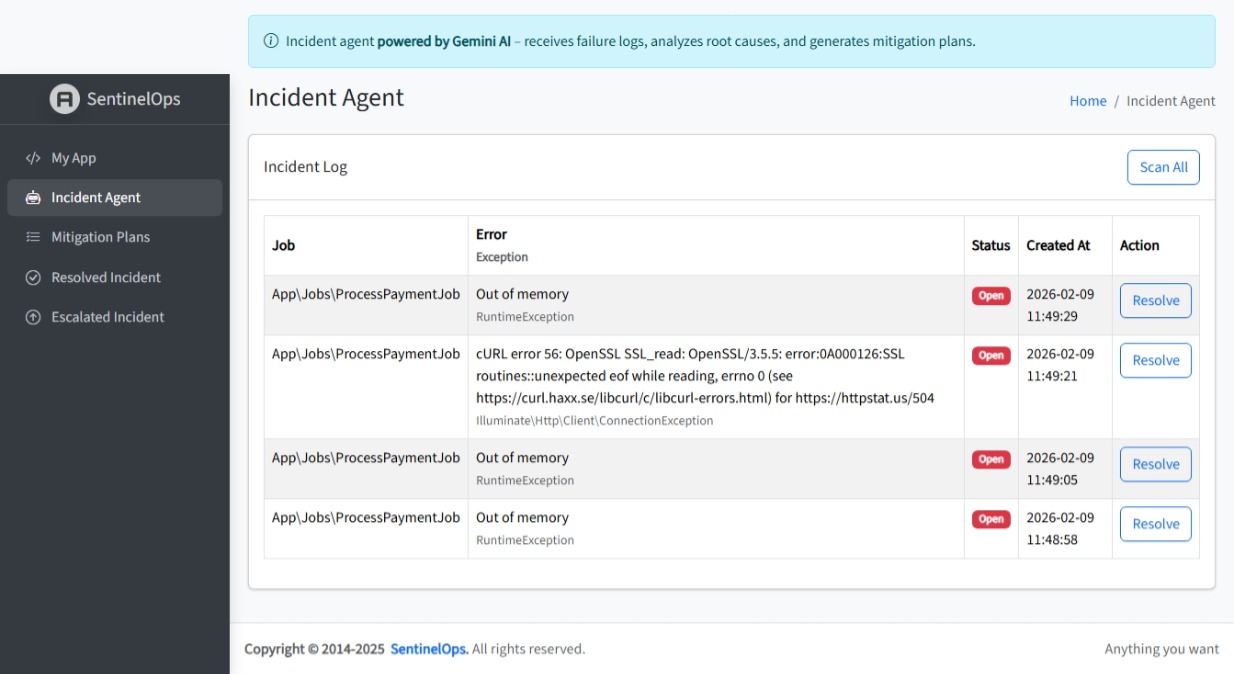
Incident Captured ready to be sent for AI analysis
-
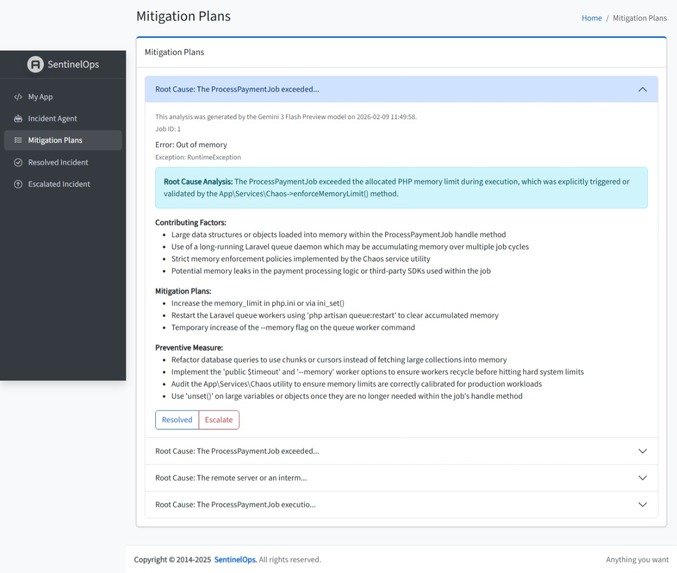
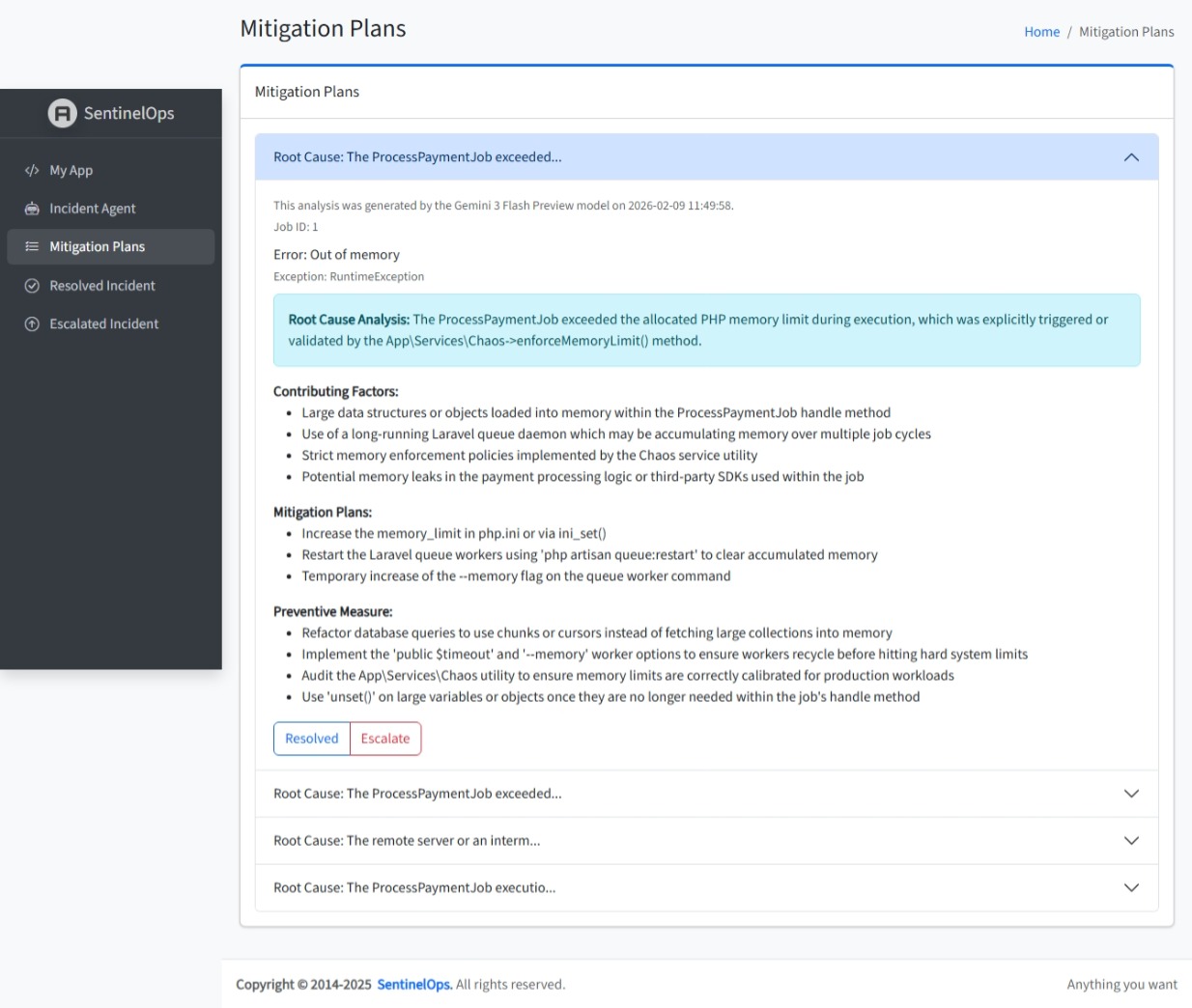
Mitigation Plans generated by Gemini AI
About SentinelOps
Inspiration
In today's cloud-native world, systems are more complex than ever. They depend on dozens of microservices, APIs, databases, and external vendors. Yet most teams only discover how their systems actually behave under stress when things break in production.
SentinelOps was born from a simple question: What if I could test failure modes before they cause real damage?
I was inspired by the chaos engineering movement—companies like Netflix, Amazon, and Google intentionally inject failures to harden their systems. But I noticed that most chaos engineering tools are designed for distributed systems at scale. Smaller teams and individual developers needed something accessible, practical, and easy to reason about.
So I built SentinelOps: a chaos engineering platform that brings failure testing within reach of every engineering team, whether you're running a single application or managing complex infrastructure.
What It Does
SentinelOps is a comprehensive failure simulation and analysis platform that enables teams to:
- Simulate Real Failures: Inject controlled chaos like latency spikes, packet loss, memory constraints, and CPU throttling to see how your system responds
- Monitor & Log Failures: Automatically capture detailed failure events with contextual information, helping you understand what went wrong and why
- Analyze Patterns: Leverage AI-powered insights to identify recurring failure patterns, root causes, and system vulnerabilities you might have missed
- Build Resilience: Practice failure scenarios in a controlled environment before they happen in production, making your system more robust and reliable
How We Built It
SentinelOps is built on a modern, battle-tested tech stack designed for reliability and scalability:
Backend Architecture
- Laravel 11 with PHP 8.4 provides a robust, expressive framework for rapid development and clear abstractions
- Eloquent ORM models (
ChaosProfile,FailureLog,FailureAnalyses) manage my data with type safety and relationships - Service Layer pattern (
Chaosservice) encapsulates failure injection logic, keeping business logic separate from HTTP concerns - Queue System powered by Laravel Queue enables asynchronous processing of long-running failure analysis jobs
- Google Gemini API integration provides intelligent, AI-driven analysis of failure patterns to extract actionable insights
Frontend & UX
- Vite for lightning-fast asset bundling and hot module reloading during development
- Tailwind CSS for utility-first styling that lets me ship a polished UI quickly
- AdminLTE theme for professional dashboard components
- Bootstrap & jQuery for interactive UI components and form handling
Infrastructure & DevOps
- Docker & Docker Compose ensure consistency across development, testing, and production environments
- Nginx web server with optimized configuration for high performance
- Supervisor process manager orchestrates background queue workers without downtime
- SQLite for lightweight local development; MySQL for production deployments
- VPS Hosting on Hostinger provides reliable, affordable hosting for the demo environment
The architecture emphasizes modularity, testability, and operational simplicity—enabling fast iteration while maintaining reliability.
Challenges We Ran Into
1. Simulating Real-World Failures Accurately
Injecting realistic failures is harder than it sounds. Network latency isn't uniform—it varies. Packet loss isn't random—it follows patterns. I had to design the chaos profiles to be flexible enough to simulate nuanced failure modes while remaining simple to configure.
2. Capturing Failure Context at Scale
Logging failures is easy; logging meaningful failures is hard. I needed to capture enough context (timestamps, system state, dependency health) to make failure analysis useful without overwhelming the database with noise. My FailureLog model balances completeness with efficiency.
3. Making AI Analysis Useful
Integrating Google Gemini API was straightforward technically, but making the AI generate actionable insights required careful prompt engineering and iterative refinement. I discovered that garbage in = garbage out. Proper failure tagging and context is crucial.
4. Queue Worker Reliability
Managing background jobs reliably is trickier than it appears. I encountered race conditions, deadlocks, and queue saturation during testing. Supervisor configuration and retry policies needed careful tuning.
5. Developer Experience
Building a tool that's powerful but not overwhelming required significant UX thought. Too many knobs, and developers won't use it. Too few, and it's not useful. I had to constantly ask: "What do developers actually need to see?"
Accomplishments We're Proud Of
🎯 End-to-End Chaos Engineering Platform
I delivered a complete system—from failure injection to analysis to insights—all integrated and working together. Most teams build partial solutions; I built the whole pipeline.
🤖 AI-Powered Failure Analysis
Integrating Gemini API to automatically analyze failure patterns is genuinely powerful. It surfaces insights that humans would miss and accelerates the path from "something broke" to "here's why and what to do."
📊 Clean, Intuitive Dashboards
My UI makes chaos engineering accessible. You don't need to be a DevOps wizard to inject a failure and see what happens. The dashboard clearly shows active profiles, recent failures, and trend analysis.
🐳 Production-Ready Docker Setup
My Docker configuration is battle-tested and includes everything needed for production: Nginx, Supervisor, proper entrypoints, and organized configuration files. Teams can deploy with confidence.
⚡ Responsive Performance
Despite running background analysis jobs and handling failure injection, the platform remains snappy. Dashboard load times are sub-second, and failure injection has minimal overhead.
📚 Well-Documented Architecture
The codebase is clean, models are well-named, and services are properly separated. A new developer can understand how failures flow through the system without extensive documentation.
What We've Learned
1. Observability is Everything
You can't fix what you can't see. Proper logging and monitoring infrastructure is not optional—it's foundational. I invested heavily in capturing failure signals early.
2. Asynchronous Processing is Essential
Even with modern frameworks, long-running operations need to happen in the background. Queue jobs transformed SentinelOps from "sometimes slow" to "always responsive."
3. Testing Under Chaos is Revealing
Building SentinelOps while using it to test SentinelOps was invaluable. I discovered edge cases, race conditions, and design flaws that normal testing would have missed.
4. AI is Best as a Thinking Partner
Gemini API isn't a replacement for human judgment—it's a collaborator. The AI surfaces patterns and suggests hypotheses; humans validate and act. This hybrid approach is more powerful than either alone.
5. Simplicity Wins
Our most successful features are the simplest ones. The chaos profiles are straightforward; the failure injection is direct; the analysis follows a clear flow. Complexity creep is the enemy.
6. DevOps Tooling Matters More Than Expected
Docker, Supervisor, migrations, and seeders aren't glamorous, but they're what make the difference between "works on my machine" and "works everywhere." I gave DevOps infrastructure the attention it deserves.
What's Next for SentinelOps
I have an exciting roadmap ahead:
🔗 Multi-Tenant SaaS Platform
Transform SentinelOps into a multi-tenant cloud service where teams can manage chaos experiments across multiple production environments with isolation and fine-grained permissions.
📈 Advanced Failure Scenarios
Add support for orchestrated failure chains—cascading failures, correlated outages, and complex failure patterns that mirror real-world incidents.
🔌 Plugin System
Enable teams to write custom failure injectors and analyzers. SentinelOps becomes the platform; the community extends it.
🎯 Predictive Resilience Scoring
Use historical failure data and machine learning to predict which systems are most likely to fail next, enabling proactive hardening.
📊 Advanced Analytics & Reporting
Build sophisticated dashboards that track resilience metrics over time, generate reports for stakeholders, and benchmark against industry standards.
🌍 Distributed Chaos
Extend failure injection across multiple services, databases, and geographic regions to simulate complex, real-world failure modes.
👥 Team Collaboration Features
Add shared experiments, runbooks, blameless postmortems, and incident response workflows to turn SentinelOps into the hub for chaos engineering conversations.
🔐 Enterprise Security
Build SSO, audit logging, role-based access control, and compliance features for enterprises managing sensitive systems.
Join Us
SentinelOps is more than a tool—it's a movement toward proactive, intentional resilience. If you're interested in chaos engineering, resilient systems, or helping teams sleep better at night knowing their infrastructure can handle failure, I'd love to hear from you.
Let's break things on purpose, so they don't break by accident.

Log in or sign up for Devpost to join the conversation.