People scroll on social media 24/7, and they don't even know what they see is real or not. The spreading of misinformation was already bad when social media released, but when artificial intelligence came into the market, the problem only became worse.
TruePixel is the first step to finding the truth behind potentially misleading information, specifically when it comes to images. It identifies pictures if they were AI-generated or human-created.
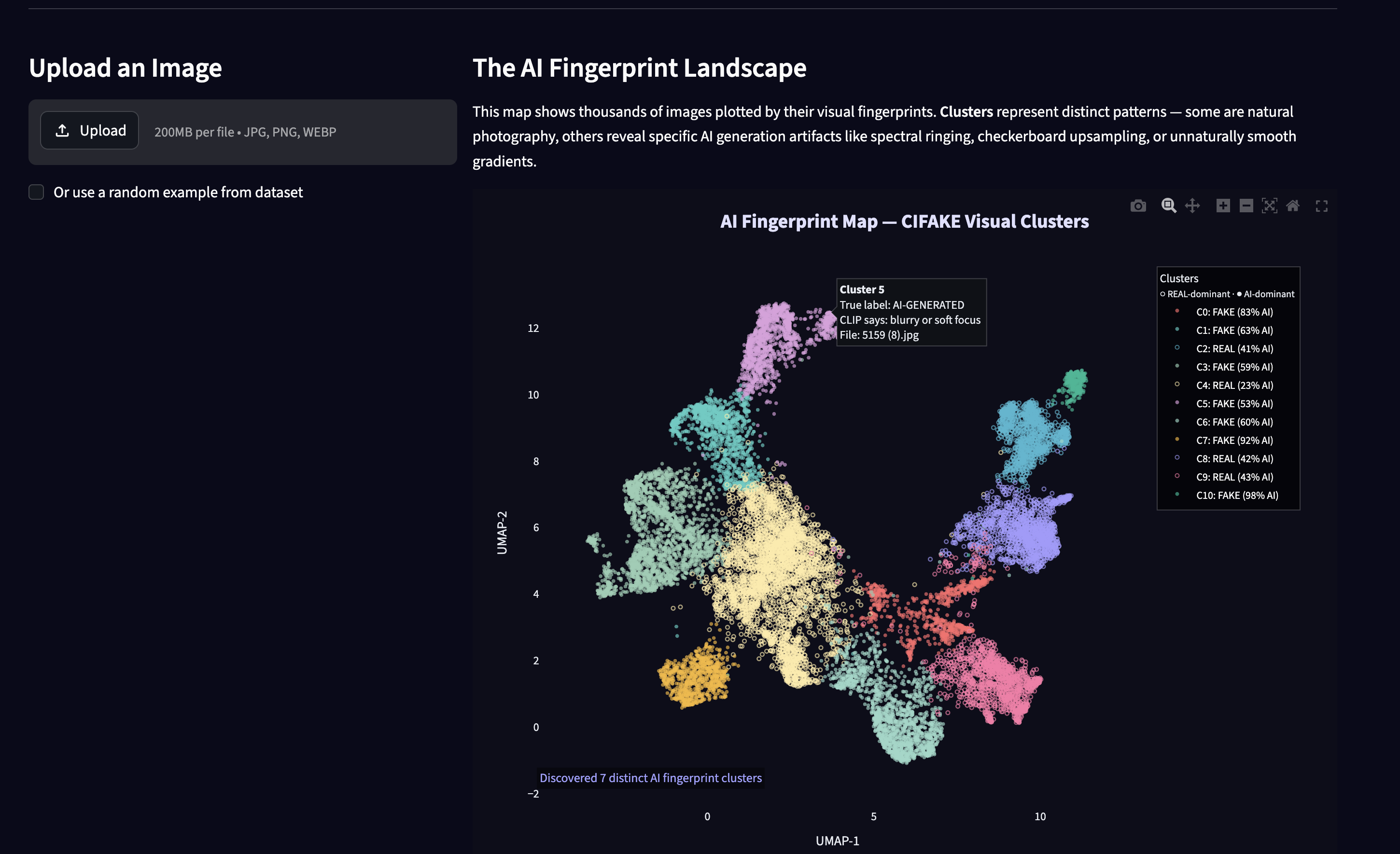
We started with the CIFAKE dataset (real vs AI images), validated the folder layout, and ran every image through a frozen CLIP ViT-B/32 model to get 512-dimensional embedding vectors. We reduced those vectors with PCA, laid them out with UMAP, and grouped them with KMeans (picking the best number of clusters using silhouette score) to discover distinct visual “fingerprint” families. For each cluster we built explanations: average images, FFT frequency profiles (to spot generator artifacts), and CLIP text tags describing what that cluster looks like. We exported an interactive Plotly UMAP map and a Streamlit app where you upload an image, embed it with the same CLIP pipeline, and assign it to the nearest cluster with AI probability and confidence from that cluster’s training statistics. The whole pipeline is scripted (run_pipeline.sh), tested with pytest, and published on GitHub so anyone can reproduce it after downloading CIFAKE locally.
One challenge I ran into was the confidence number being lower than 75%. This happened on some images when the resolution of the image input exceeded 1000x1000, because the predictions TruePixel makes are based on 32x32 pixel images. To fix this, I tried doing HD synthetic augmentation, where I create the 32x32 images into what the images would have looked like if they were 1000x1000 resolution images. When I implemented that solution, it still was not accurate, in fact the predictions and the confidence levels were even worse than before, so I scrapped the idea entirely and stuck with what I have now.
I am mostly proud of how my model could somewhat predict correctly with high-resolution images, even the data set used to train my model was horrible.
I learned that the biggest factor that affects the quality of a ML model is solely based how good the data set it uses to train on.
The next part would first be replacing the entire dataset with a better one, then maybe deploy it so people can use this product as a service.

Log in or sign up for Devpost to join the conversation.