-
-

Logo
-
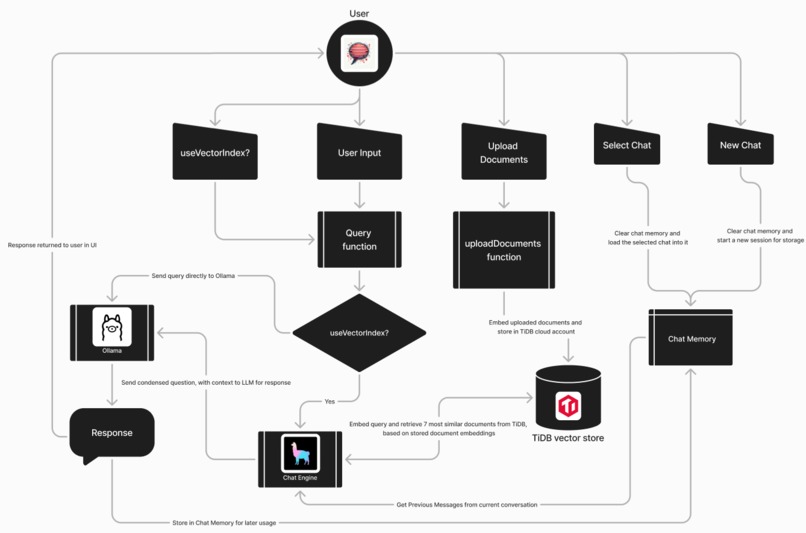
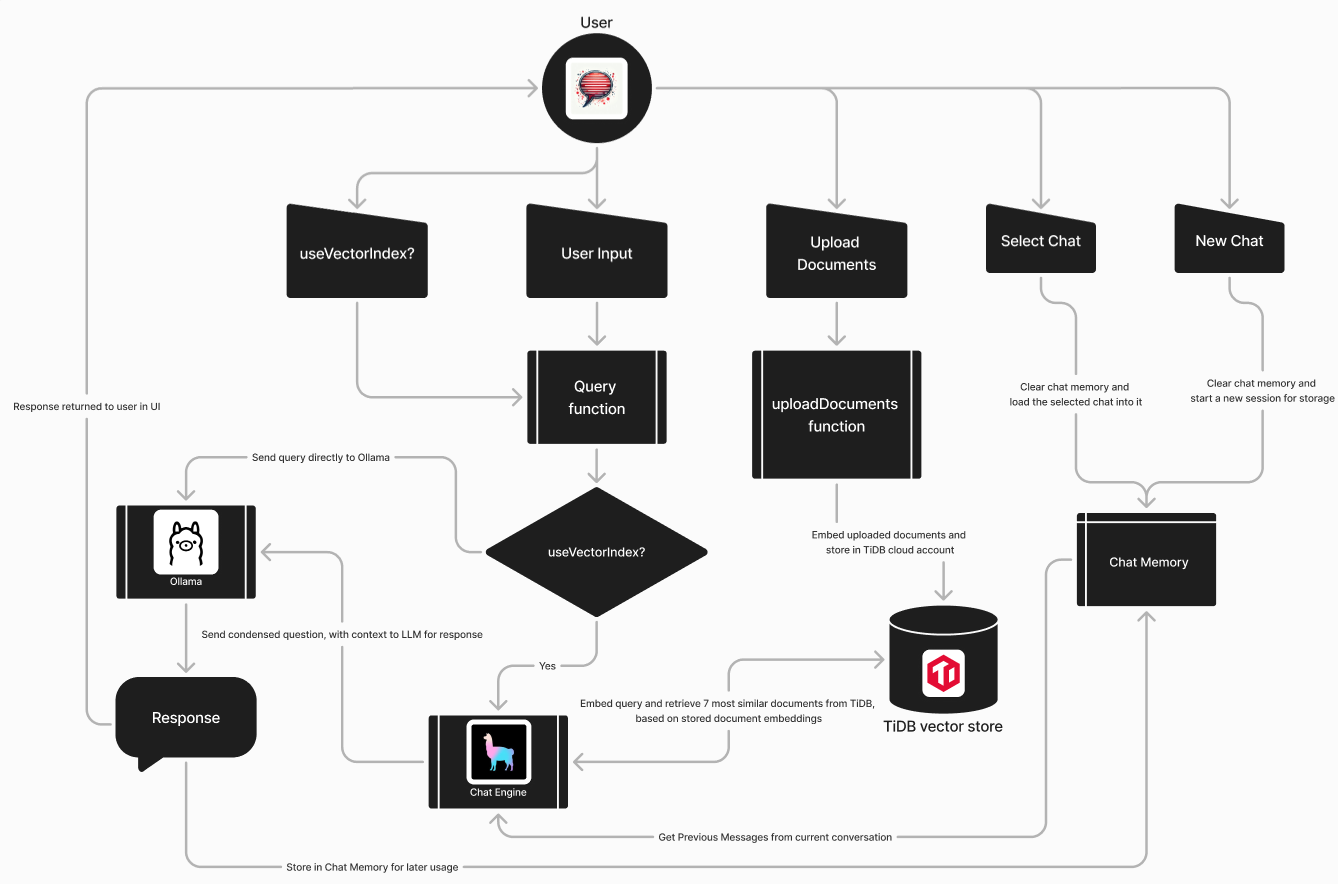
Diagram
-
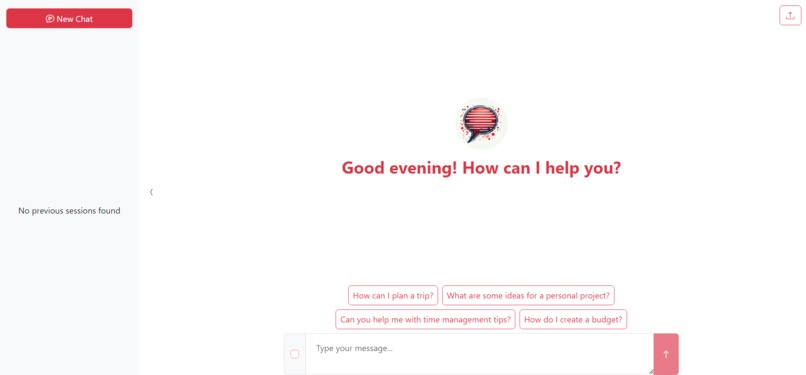
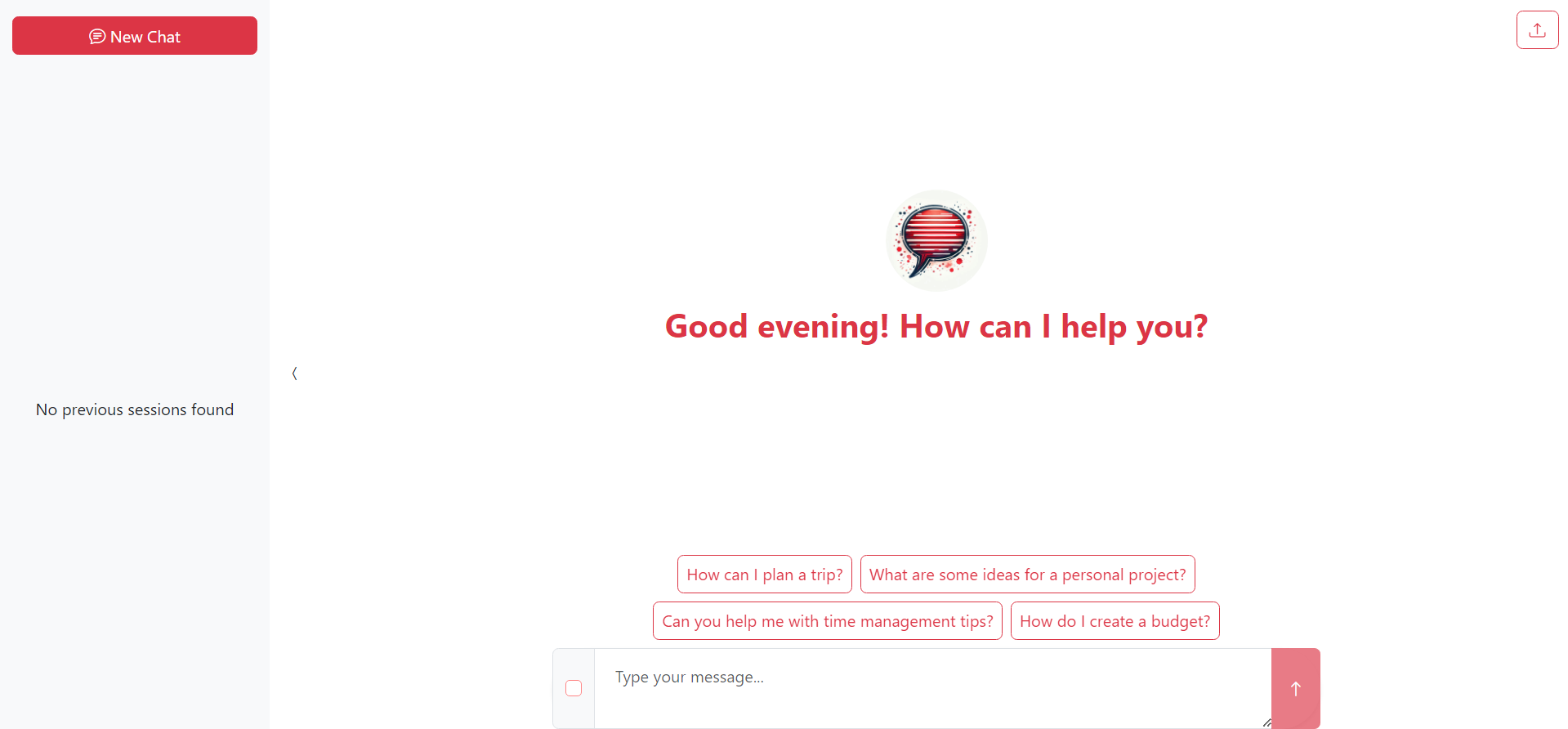
UI image

Inspiration
Current solutions, such as ChatGPT, Claude, as well as other open source solutions have drawbacks, including:
- Rate limits
- API usage
- No Persistence
- No security and safety
- Complicated and Constrained setup
We set out to solve these problems, using TiDB's cloud vector search capabilities, harnessed by llama-index.
What it does
Our solution, TiChat, makes use of TiDB cloud, llama-index and Ollama, with React and Bootstrap5 being used for the frontend, to create a Simple, High-Quality, Extensible, Open-Source RAG application.
It allows the users to:
- Upload text-based documents
- simply chat with the model
- use the built vector-index to get better-informed answers
- treat the app like ChatGPT, with persistent chats and new chat systems
Please read the README's at TiChat and Streamlit Deployment to get a better idea our solution, with the submitted video.
Benefits
- No Rate limits
- Easy setup and installation
- Complete Privacy
- Persistent embeddings
- Extensible
How we built it
TiChat (main local app project)
1) Signed up for a free TiDB cloud account
- Generated a password
- Downloaded the CA certificate
- Copied the connectionString for later usage 2) Installed Ollama
- Used mistral:instruct for current project, due to performance and efficiency 3) Installed llama-index and other relevant dependencies for backend 4) Built the backend using llama-index, flask and flaskwebgui 5) Parallely built the frontend using React and Bootstrap5 6) Packaged the app using PyInstaller for a single-file app 7) Created the installer for the app with the other required files using Inno Setup
BlenderHelperBot-with-TiDB (online implementation for quick testing)
1) Installed llama-index, streamlit and other relevant dependencies 2) Obtained READ token from HuggingFace 3) Uploaded embeddings of Blender 4.1 API docs to TiDB cloud (check README.md) 4) Created streamlit app for chat-engine usage based on uploaded documents 5) Deployed app to Streamlit cloud
Challenges we ran into
1) We had to design the entire system for this solution, and find existing solutions, if any, that can be directly plugged in (e.g. Ollama, llama-index, TiDB) as components. 2) We then had to harmonize the components and build an app using this. 3) Testing of the app showed that chunk_size, chunk_overlap and similarity_top_k paramaters had to be modified for best responses. 4) Final touches included improving look and feel of the app, for best user experience. 5) To allow the users to get a taste of the app, we built a sample online implementation.
Accomplishments that we're proud of
Some of accomplishments include:
1) Harmonized local app 2) Persistent chats and embeddings 3) High speed and quality of model responses 4) Easy setup and extensibility 5) User Experience 6) Complete Privacy 7) Users have complete control over their data
What we learned
Some of our learnings include:
1) Documents are embed into vectors 2) These vectors are stored in a vector store, like TiDB vector store 3) These are retrieved preferably using cosine similarity with the embed query 4) Chunking divides the input documents based on chunk_size, prior to embedding, for easy and quick running 5) chunk_size, chunk_overlap and similarity_top_k determine the quality of responses (lower means higher resource usage, but more fine-grained embeddings and vice versa) 6) context_window and num_output affect hardware resources' usage and response quality (higher=higher and vice versa) 7) RAG is superior to finetuning an llm, due to far lower resource requirements and quicker implementation 8) Importance of:
- UX
- Packaging
- Privacy
What's next for TiChat
1) Add ability to change model parameters from the UI 2) Add Delete documents capability 3) Add Custom Instructions capability for model 4) Add Image upload capability 5) Add Model selection capability

Log in or sign up for Devpost to join the conversation.