-
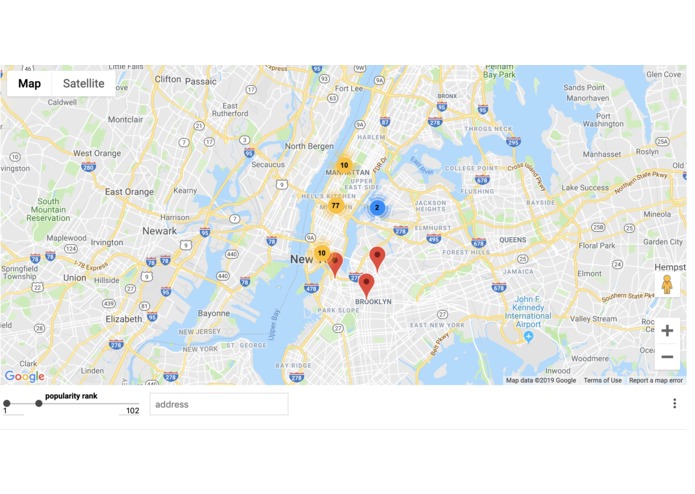
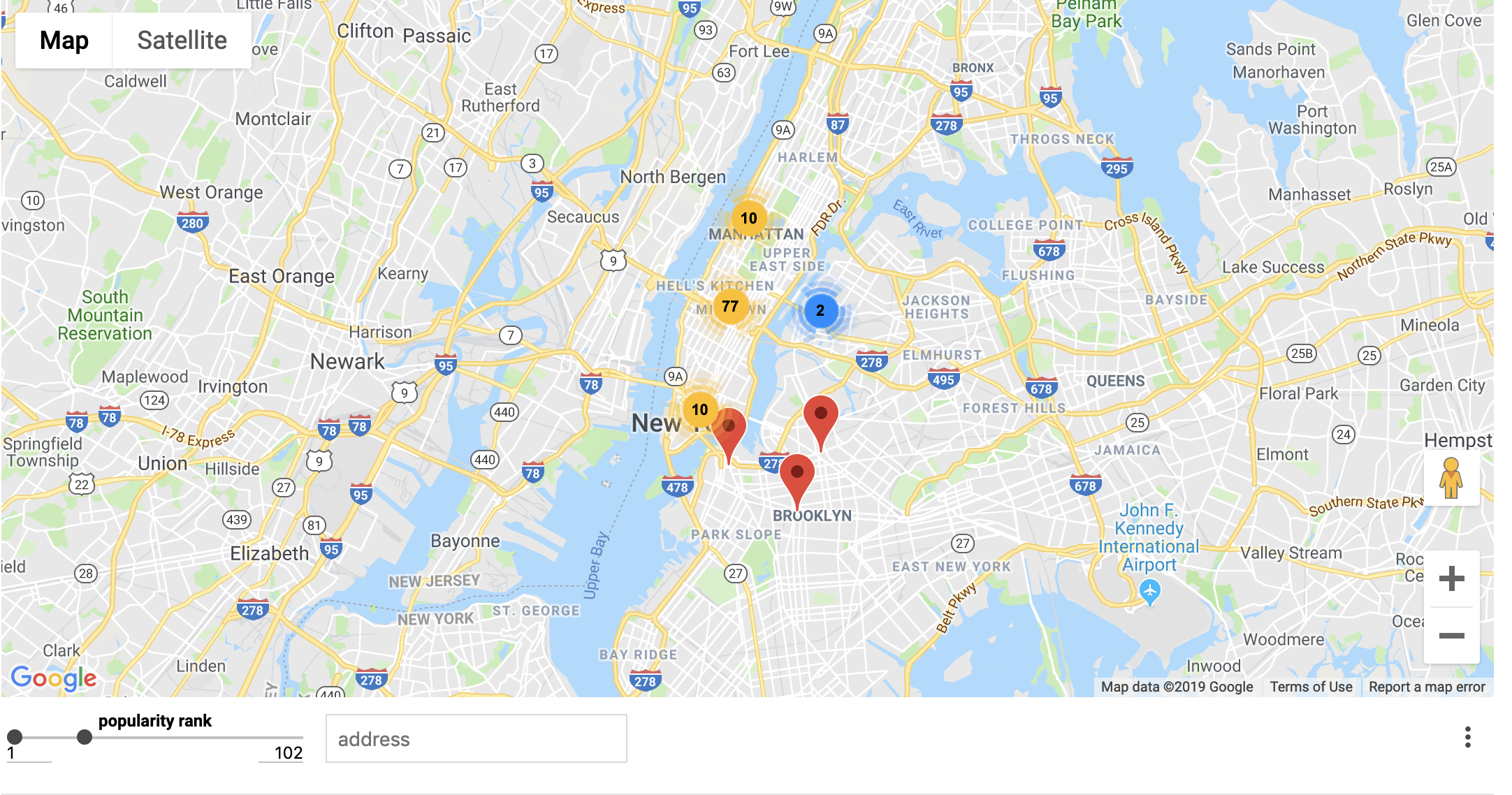
Most Popular Hotel on the map
-
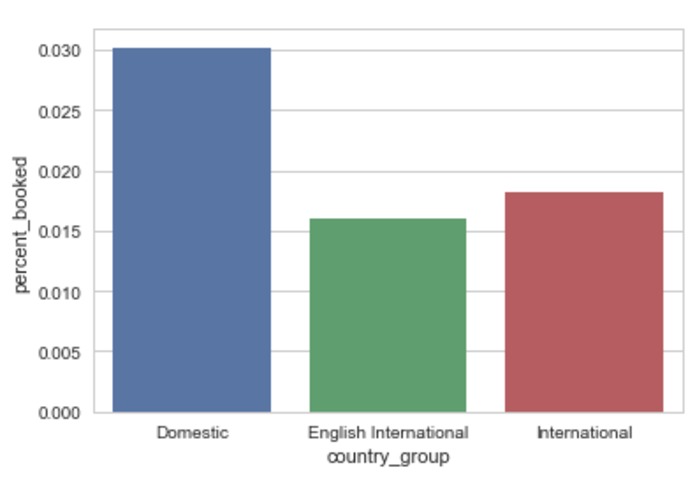
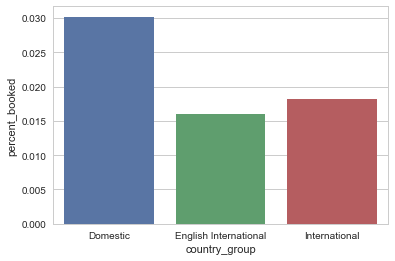
Booking percent by country groups.
-
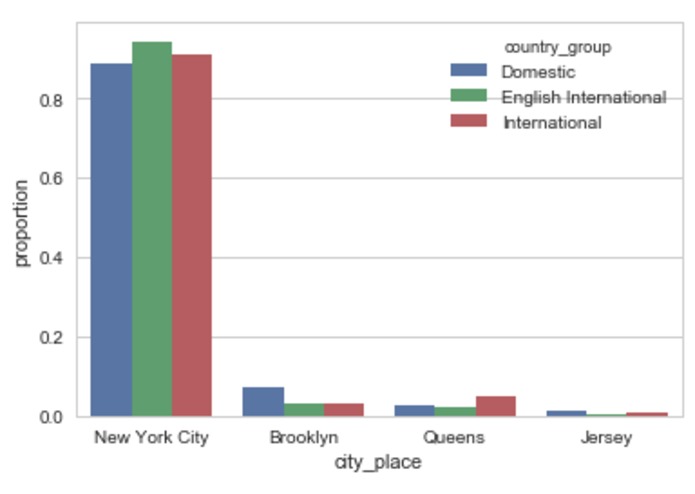
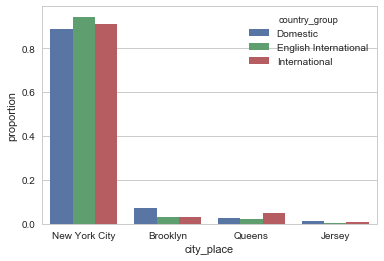
City booked by country group
-
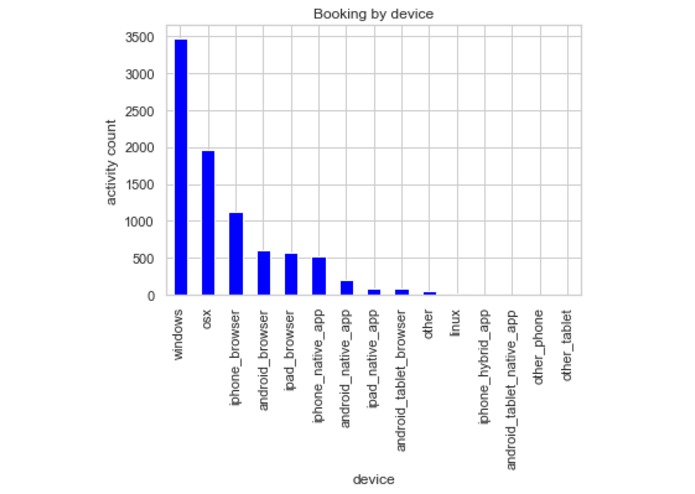
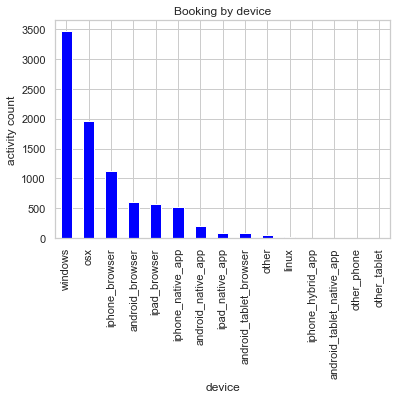
User activity vs device for users that booked.
Inspiration
We started with the given TripAdvisor data which included information about users history over a month and hotel information in the NYC area. We wanted to know if basic user activity and information could be used to predict which users were most likely to book. Other questions we had after exploring the data a bit were does country or device make a difference in the likelihood that a user would book.
Once we were able to predict whether a user was going to make a booking, we wanted to know if we could predict characteristics of the hotel they booked. We focused on star ratings and locations since this information is crucial for ranking hotels on the website. We built an interactive map which shows the most popular hotels by location - this was telling that just general city was not enough information, we wanted zipcodes.
What it does
The first part of our project was to predict if a user would book given the following features: number of price clicks, device, country, number of views, and number of website clicks for each user. This was essentially all information we had about an individual user.
The second part of our project has two separate algorithms to predict star rating and location (zip code). To predict star rating we used information about the user and the hotels that they viewed. We summarized the information of all hotels viewed in our features. The features we used are as follows: country, device, stars(min/max/average), bubbles rating (min/max/average), number of reviews (min/max/geometric average), and number of hotels viewed. We then predicted the zipcode the hotel was located in using some external data. The following features were used: country, device, stars(min/max/average), bubbles rating (min/max/average), number of reviews (min/max/geometric average), average price of 1-bedroom apartment in hotel zipcode (min/max/average) and number of hotels viewed.
We were also able to find feature importance for all of the models.
How we built it
Part 1: Prediction of Whether a User Books We first cleaned the data. There were users who used more than one device or were in multiple countries; these users we dropped in order to have well defined features. This left us will 99% of the original data set. We then manipulated the data in order to create the features: number of views, number of price clicks and number of website clicks for each user. We split the data into train/test sets using 75% of the data to train and 25% of the data for testing. The training data was inputted a XGBoost classifier.
Part 2.1: Star Ratings Prediction To predict the star rating of booking made by users, we consider only users that made exactly one booking during the month of data provided. This dropped about 9% of the data. We split the data into train/test sets using 75% of the data to train and 25% of the data for testing. The training data was inputted a XGBoost classifier.
Part 2.2: Zipcode Prediction For this we first supplemented our data with zipcodes for each hotel and the average 1 bedroom rental price for each zipcode. The zipcodes for each hotel was gotten from the TripAdvisor website. We were able to reverse engineer the corresponding hotel detail page url for each hotel_id on TripAdvisor. We wrote a python crawler with Selenium to read the address and zip code from TripAdvisor's page of every hotel appeared in the hotel data set. In fact, if we had more time, we could possibly write a better parser to extract more data from TripAdvisor's hotel review page. This could include the detailed rating of location etc, and reviews as bag of words. The rental prices per zipcode were gotten from Zillow data. We then combined the data we needed and cleaned it up. We did the same cleaning as the star rating prediction. We additionally dropped users that viewed hotels with no associated zip code and average housing price. After the cleaning we only had 62% of the original data. We split the data into train/test sets using 75% of the data to train and 25% of the data for testing. The training data was inputted a XGBoost classifier.
Challenges we ran into
The main challenge we ran into was the amount of data. We felt like we didn't have enough data about the hotels, especially location and price. We also couldn't do any sequence data since we didn't have time stamps for the activities for each user.
Accomplishments that we're proud of
Part 1: We got a 97-98% accuracy. The most important features were the number of price clicks, device, and country. Number of website clicks is the least important feature by far.
Part 2.1: We had an accuracy of 79%. When calling a prediction correct if it was within .5 stars of the actual star rating, we got a 93% accuracy. The most important features were star min/max/average. The least important features were device and bubble min/max.
Part 2.2: We had an accuracy of 71% to predict zipcode. The most important feature was the min, max, and average of the rental price of the zipcodes. The least important features included bubble max/min and star max/min. In general, the averages were more important than the min/max.
What we learned
We learned that we can predict if a user will booked based on some of their history on TripAdvisor. Given that a user will book, we can predict the star rating of the hotel they will book - especially within 0.5 stars. Our results suggest with more information we could accurately predict the zipcode of the hotel booked by a user.
What's next for TripAdivor: Who's Booking and Where are they Booking?
With more data:
-Using the user history for each day, predict what hotel they’ll view next to ultimately show the hotel they’ll likely to book (RNN). Only half of the users viewed and booked on different days.
-Use the click stream to predict what hotel they’re more likely to view/book (RNN)
-Given a hotel, predict how likely/how many times is booked using all the features available of the hotel with zipcode information, pricing of the zipcode area (XGBoost)
Built With
- python-pandas-sklearn-xgboost

Log in or sign up for Devpost to join the conversation.