-
-

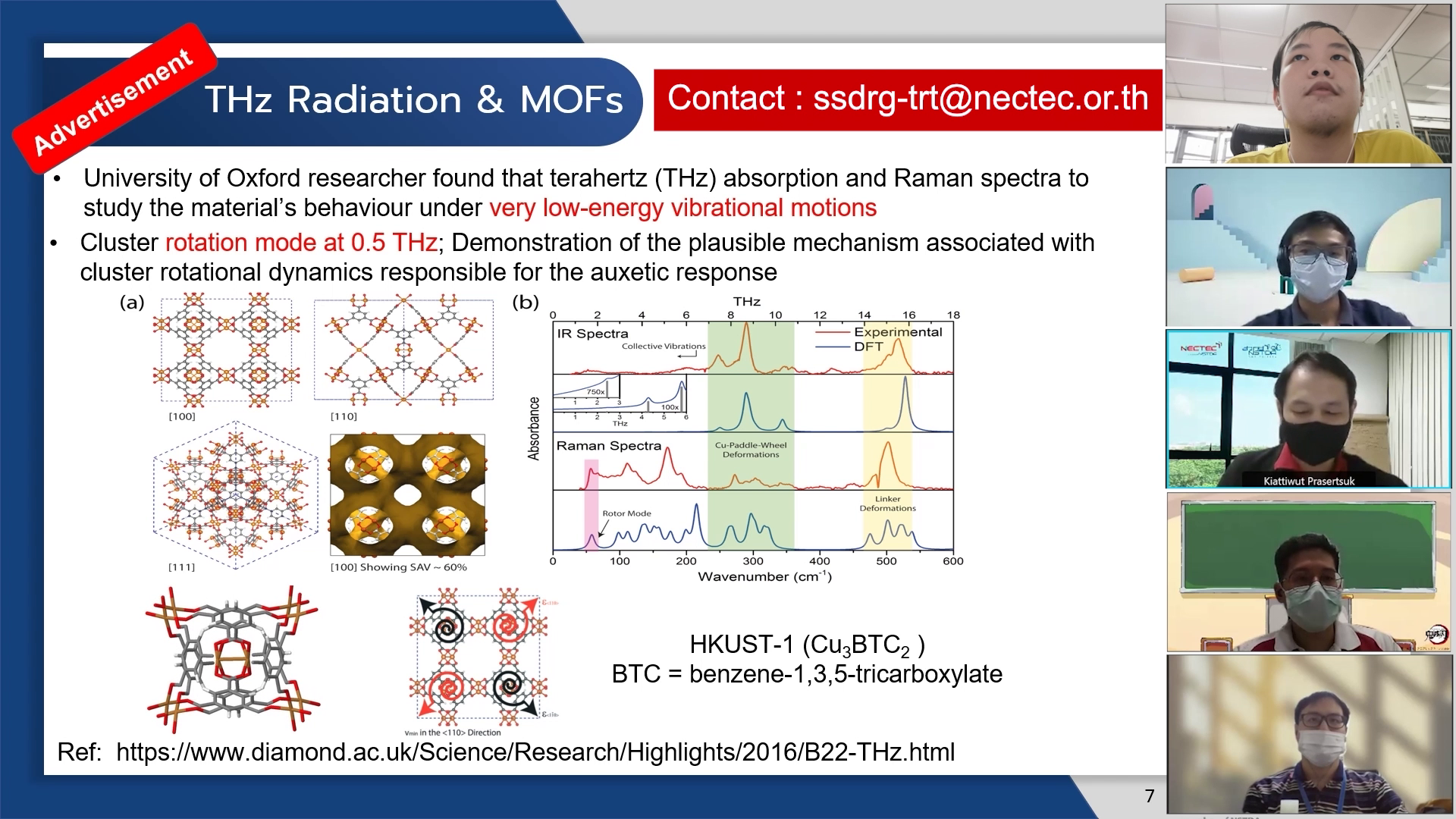
โฆษณาการวัด Cluster Rotation Mode ของ MOF ด้วยคลื่น Terahertz
-

สมาชิกภายในทีม
-
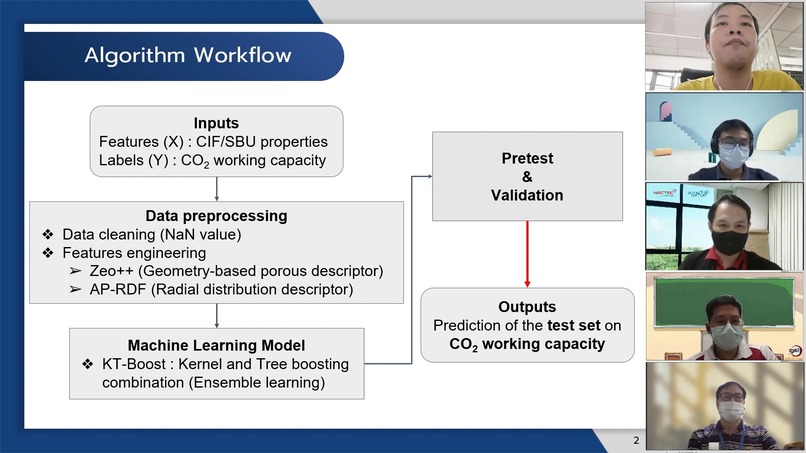
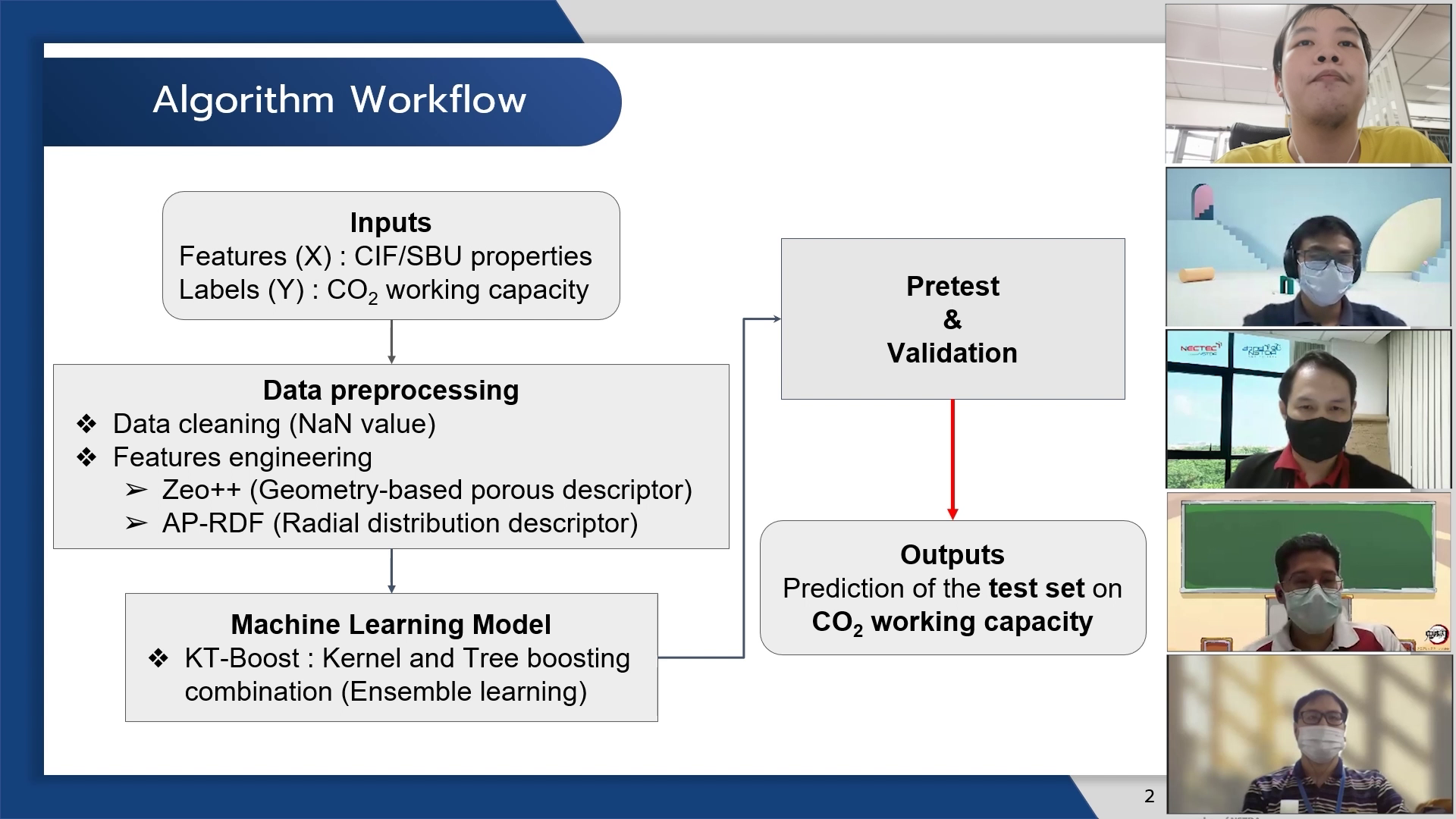
Workflow ของเรา
-

Preprocessing
-
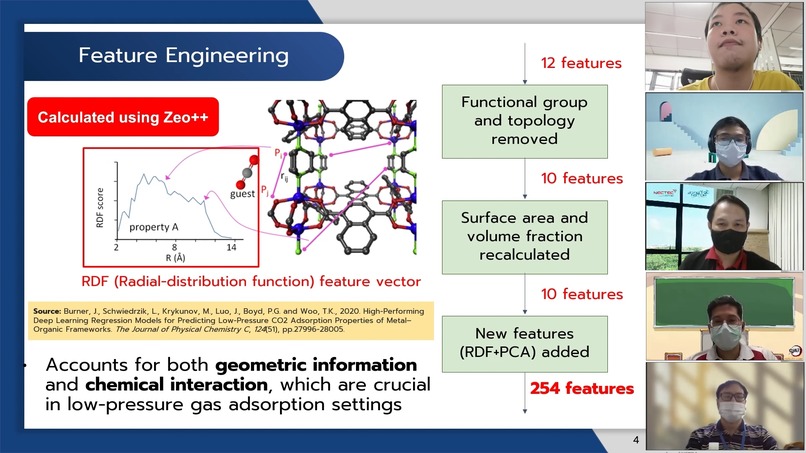
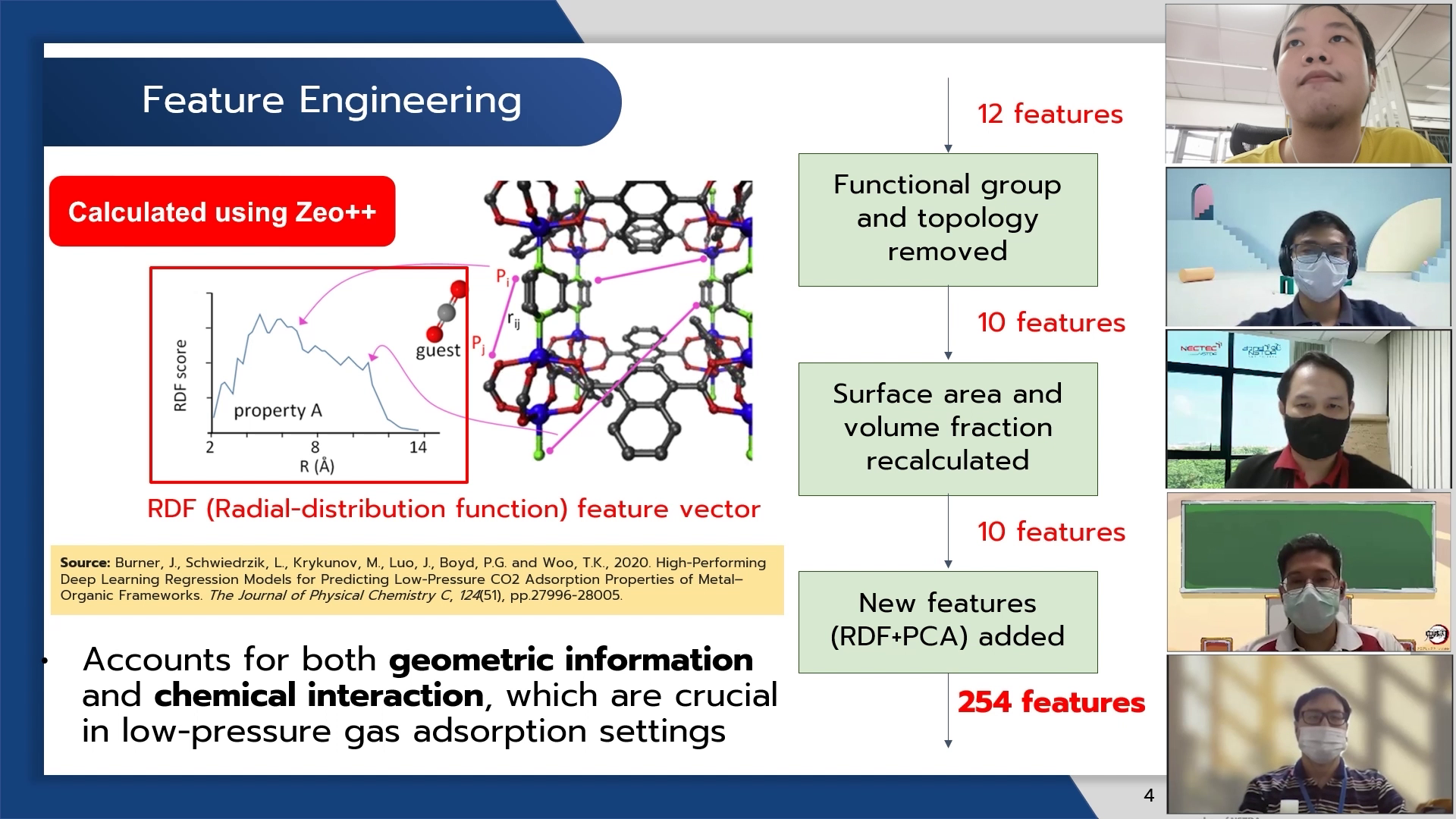
Feature Engineering
-

Model ที่เราเลือกใช้
-
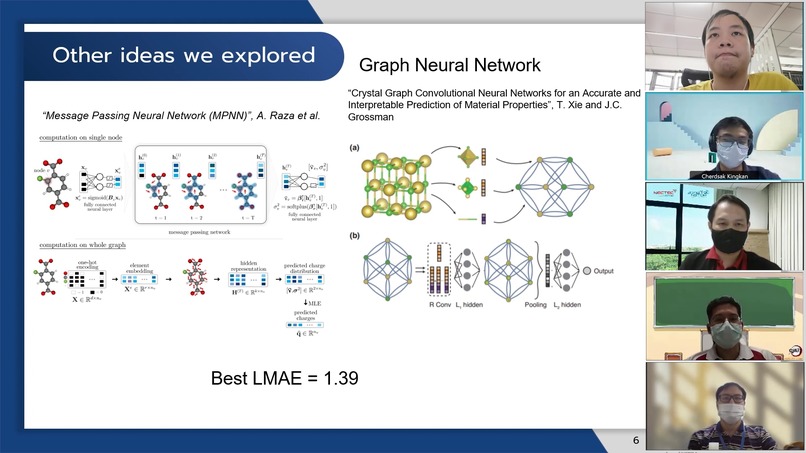
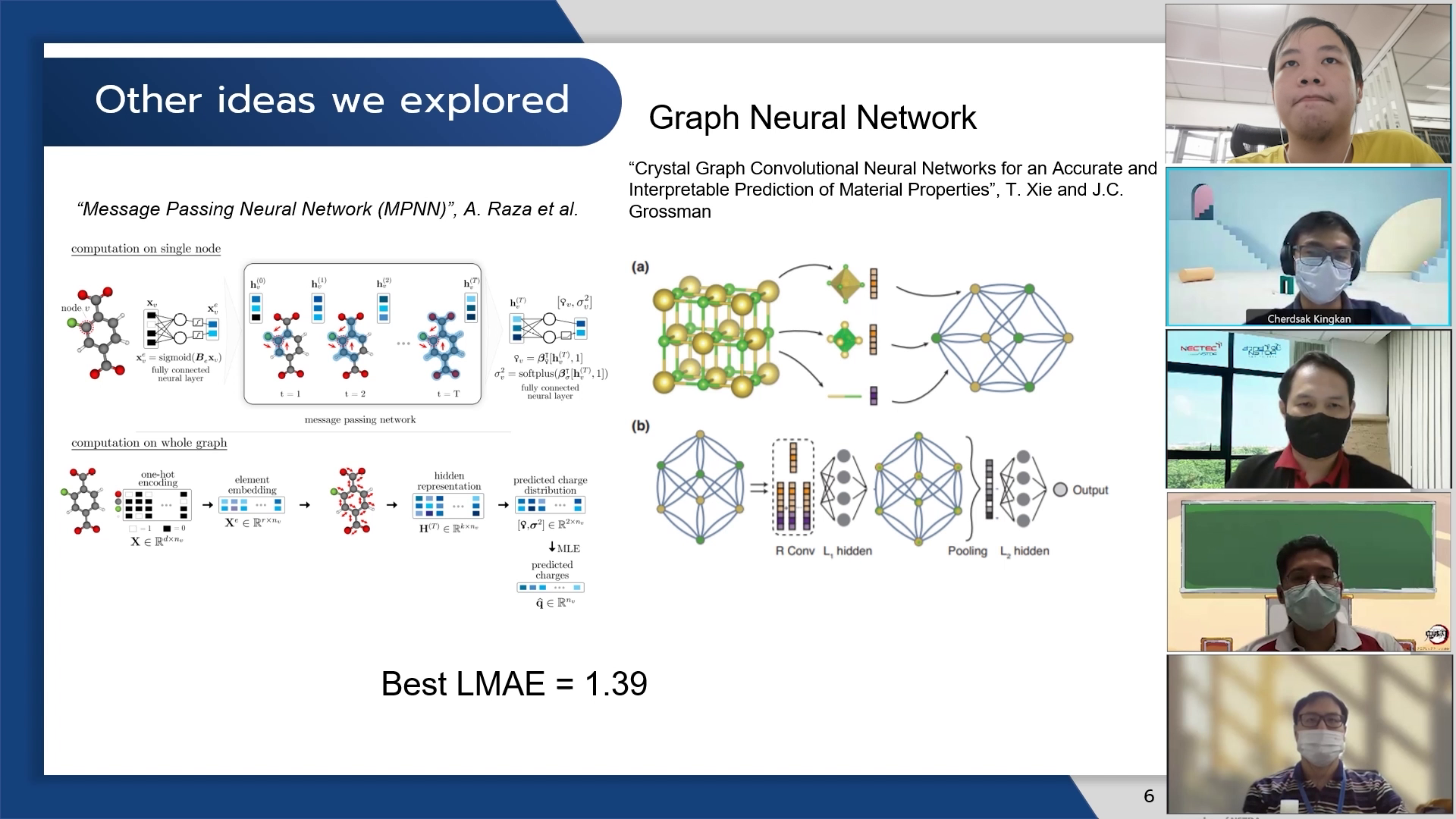
วิธีอื่นๆที่เราได้ทดลองทำ
-

Squid Game?




Inspiration
หาประสบการณ์ในการทำ machine learning ในสาขาอื่นเพิ่มเติม นอกเหนือจากสาขาที่ทำอยู่
What it does
machine learning model แบบ kernel + trees regression มีชื่อเรียกว่า KT-Boost ซึ่งมีข้อได้เปรียบในการทำนายค่า MOF CO2 working capacity จาก training set ที่มีทั้งค่า features แบบ continuous และ discrete รวมไปถึงการทำ feature engineering โดยใช้ RDF (Radial Distribution Function) ของโครงสร้างโมเลกุล และข้อมูลจากการคำนวณค่าคุณสมบัติของ porous material มาช่วยเสริม training set ให้โมเดลมีความแม่นยำมากยิ่งขึ้น
How we built it
Data cleaning and pre-processing >> Features selection/addition >> Model selection >> Training >> Evaluation (Pre-test) >> And prediction on real test set!!
Challenges we ran into
สมาชิกทีม Trillion ได้เจอปัญหาต่างๆ ดังนี้ครับ
- ข้อมูลโครงสร้างเคมีมีความซับซ้อน และต้องใช้เวลานานในการทำความเข้าใจ
- Features ที่นำมาใช้งานมีจำนวนมาก ประกอบกับ machine learning model มีความซับซ้อนสูง ทำให้ต้องเสียเวลาในการ train นาน และ model เกิดการ overfit อยู่บ่อยครั้ง
- โปรแกรม open-source ที่นำมาใช้ทำการคำนวณหาค่า surface area กับ void fraction ใหม่ ติดตั้งและใช้งานยาก เราได้แก้ไขโปรแกรมให้ข้าม Voronoi check ในบางกรณี Zeo++ Edited by Trillion
- การคำนวณหา features ใหม่ใช้เวลาและทรัพยากรเครื่องอย่างมหาศาล ทำให้ไม่มีโอกาสได้ลอง features ในรูปแบบอื่นที่อาจให้ประสิทธิภาพที่ดีกว่า
และนี่เป็นเพียงส่วนหนึ่งของปัญหาของพวกเราในระหว่างทางครับ อย่างไรก็ดี แม้ว่าสมาชิกของพวกเราจะมีความเชี่ยวชาญในสาขาที่ต่างกัน แต่ทุกคนก็ตั้งใจกันอย่างเต็มที่ครับ
Accomplishments that we're proud of
สิ่งที่พวกเราทั้ง 5 คนภูมิใจมากที่สุด คือ การที่พวกเราได้เรียนรู้สิ่งใหม่ๆ เพิ่มเติมขึ้นอย่างมากในช่วงเวลาเพียง 1 เดือน (ซึ่งอาศัยการลองผิดลองถูกอยู่หลายครั้ง) ไม่ว่าพวกเราจะมีความเชี่ยวชาญในด้านไหนมาก่อนก็ตาม และการแข่งขันนี้ทำให้พวกเราสนิทกัน และรู้จุดแข็งของตัวเองและสมาชิกคนอื่นๆ ในทีมมากยิ่งขึ้นครับ
What we learned
- ได้เรียนรู้ว่า MOF คืออะไร และมีความสำคัญอย่างไร
- ได้เรียนรู้ว่า machine learning มีบทบาทที่สำคัญในวงการเคมีอย่างไร โดยเฉพาะในงานวิจัยที่เกี่ยวกับการวัดประสิทธิภาพของ MOF
- ได้เรียนรู้หลักการต่างๆ เบื้องต้น ที่จำเป็นในการทำ machine learning เช่น การทำ EDA (Exploratory Data Analysis), การทำ data pre-processing, การทำ feature engineering, การสร้าง machine learning models โดยใช้ module sklearn และ tensorflow รวมทั้งการแก้ไขหรือปรับแต่งให้ model มีประสิทธิภาพเพิ่มขึ้น
- ได้เรียนรู้การวางแผนเวลา และจัดสรรทรัพยากรต่างๆ ในเวลาที่จำกัด
- ได้ลองใช้ทรัพยากร Cloud Computing ที่เราไม่เคยคิดว่าจะได้ใช้มาก่อนเพื่อประหยัดเวลาในการรันโปรแกรม Zeo++ ARM64 compiled by Trillion Train+Pretest Test และการหา Feature AP-RDF Train+Pretest Test
What's next for Trillion
- ฝึกวิชา data engineer และ machine learning ให้เชี่ยวชาญมากขึ้น
- ปรับใช้สิ่งที่เรียนรู้จากโครงการนี้ ไปกับการวิเคราะห์ข้อมูลทาง terahertz เพื่อเทคโนโลยีที่มีประโยชน์ต่อไปในอนาคต
- ช่วยกันประสานองค์ความรู้ทางวิทยาศาสตร์และ machine learning ให้ประสิทธิภาพงานวิจัยมากขึ้นอย่างก้าวกระโดด
Built With
- ase
- python
- sklearn
- tensorflow
- zeo++


Log in or sign up for Devpost to join the conversation.