
Inspiration
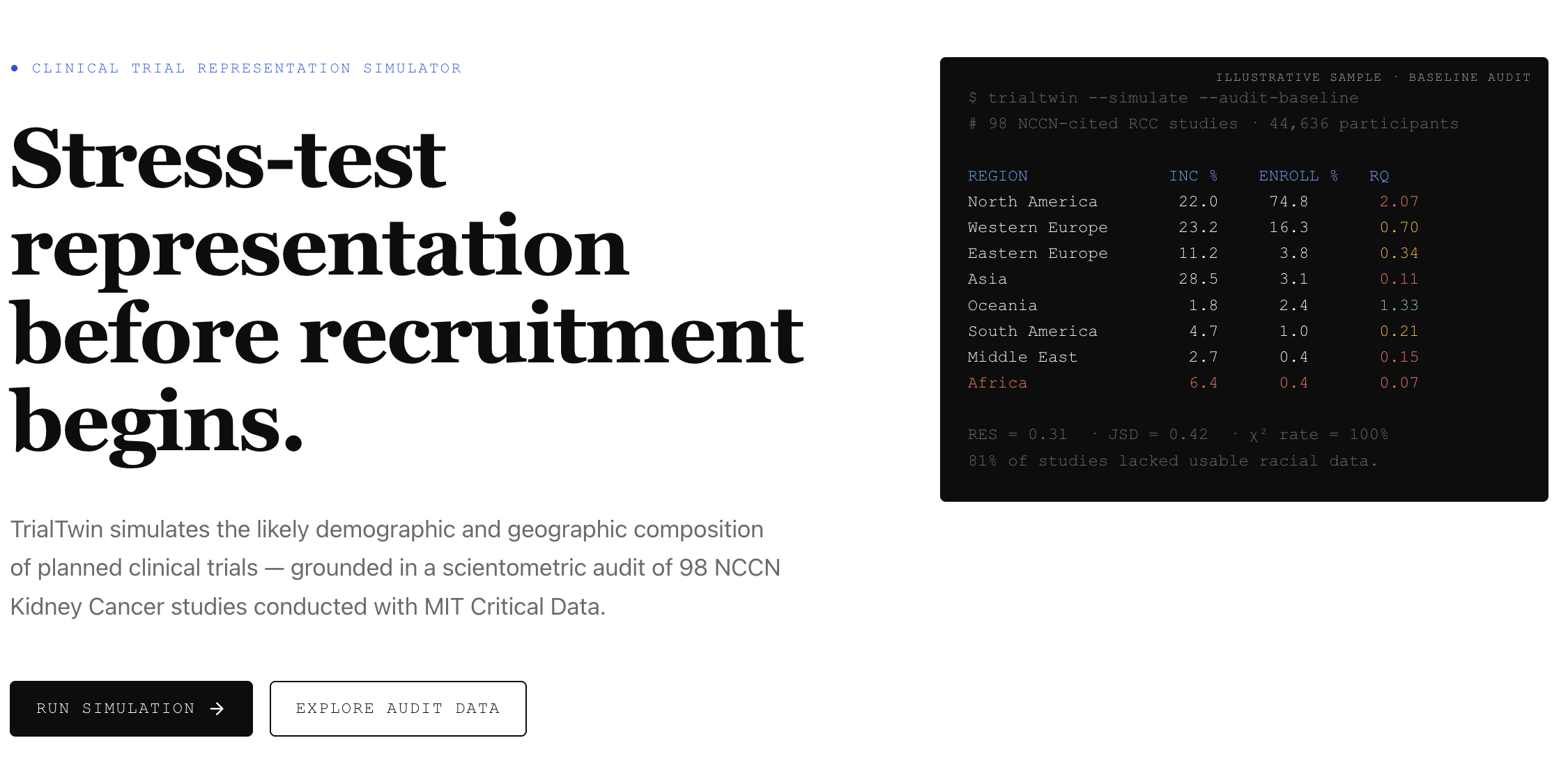
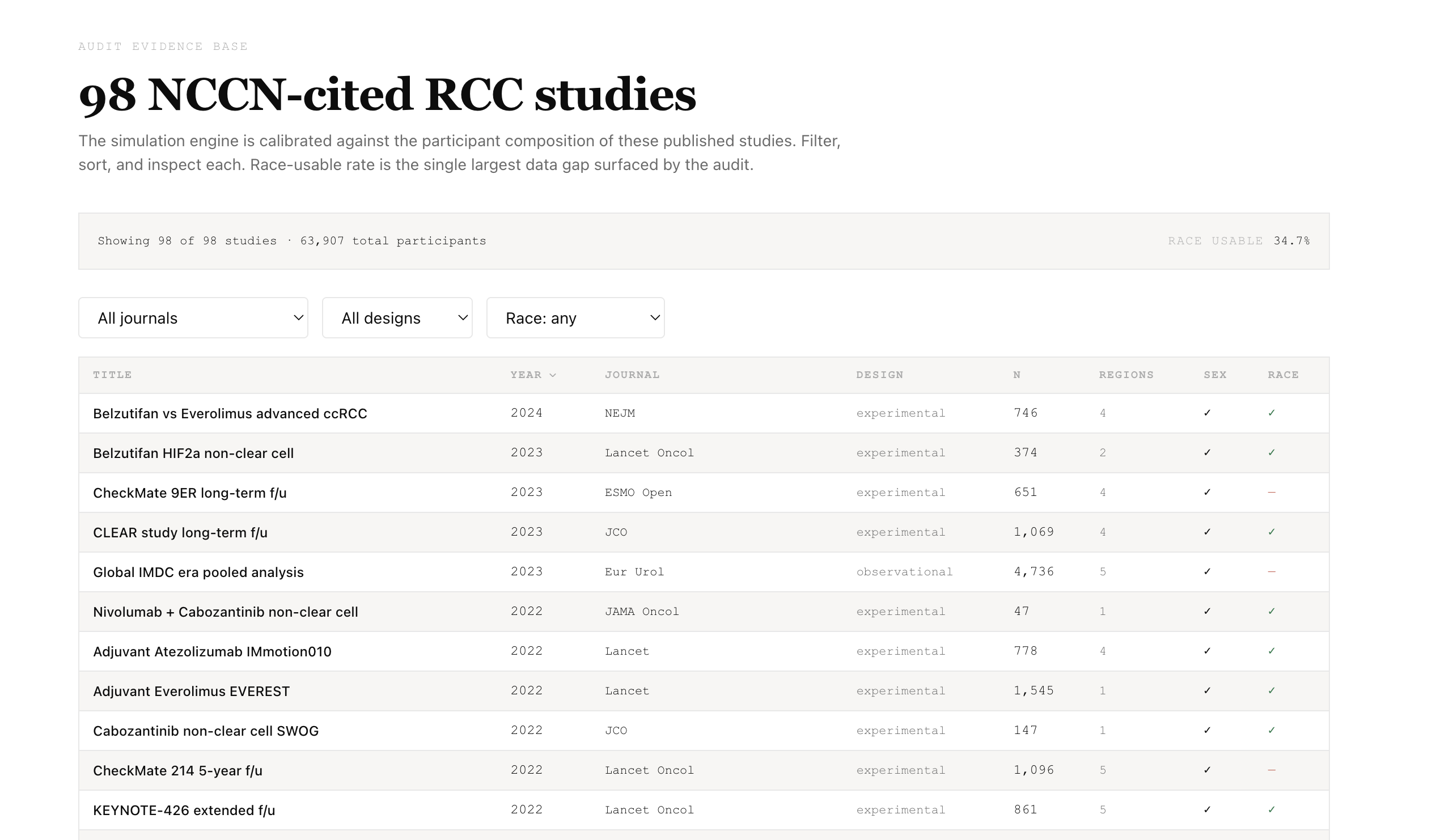
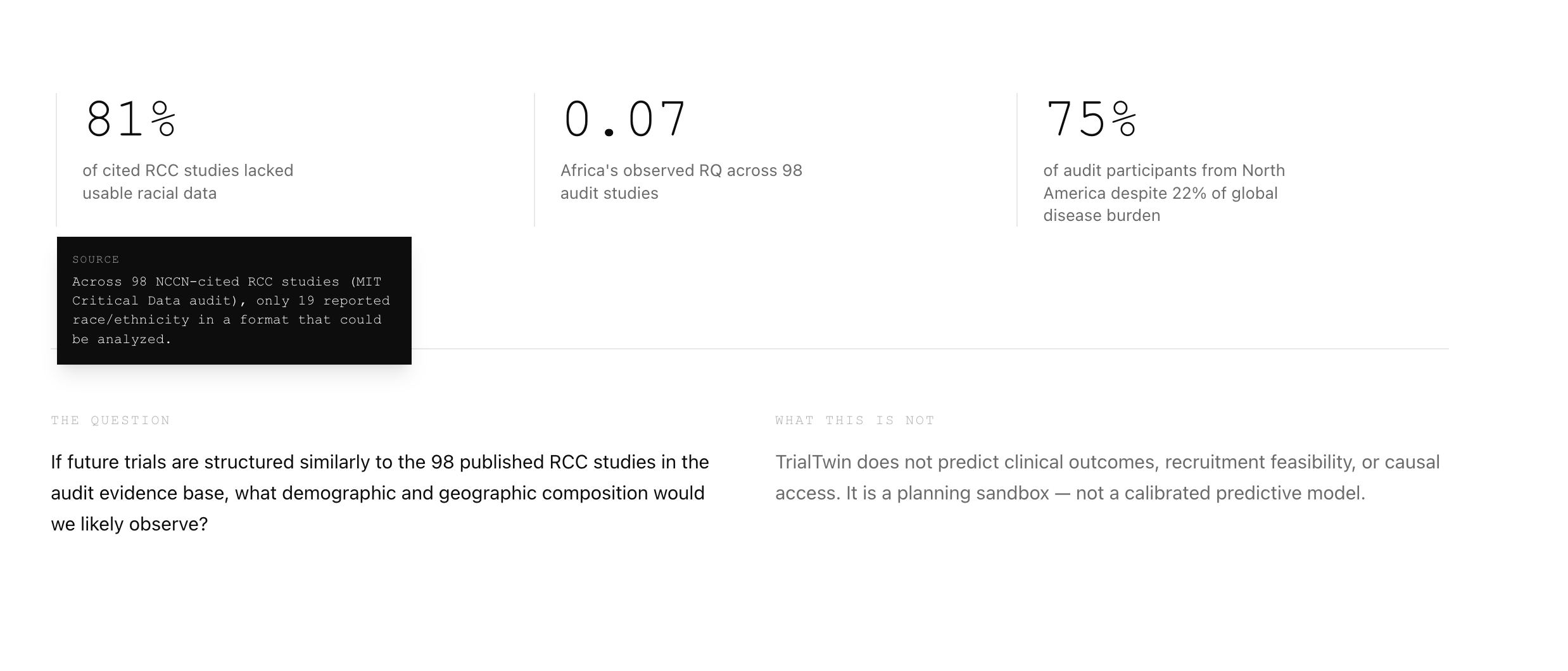
I audited 98 studies cited in the NCCN Kidney Cancer Guidelines v3.2022 with MIT Critical Data — 44,636 patients total. North America was enrolled at 2.07× its global disease burden, Africa at 0.07×, Black patients at roughly half their burden rate, and 81% of studies lacked usable race data. The bias was not discovered during design. It was documented after publication.
TrialTwin moves that check to the start: simulate who will actually enroll before the protocol is locked.
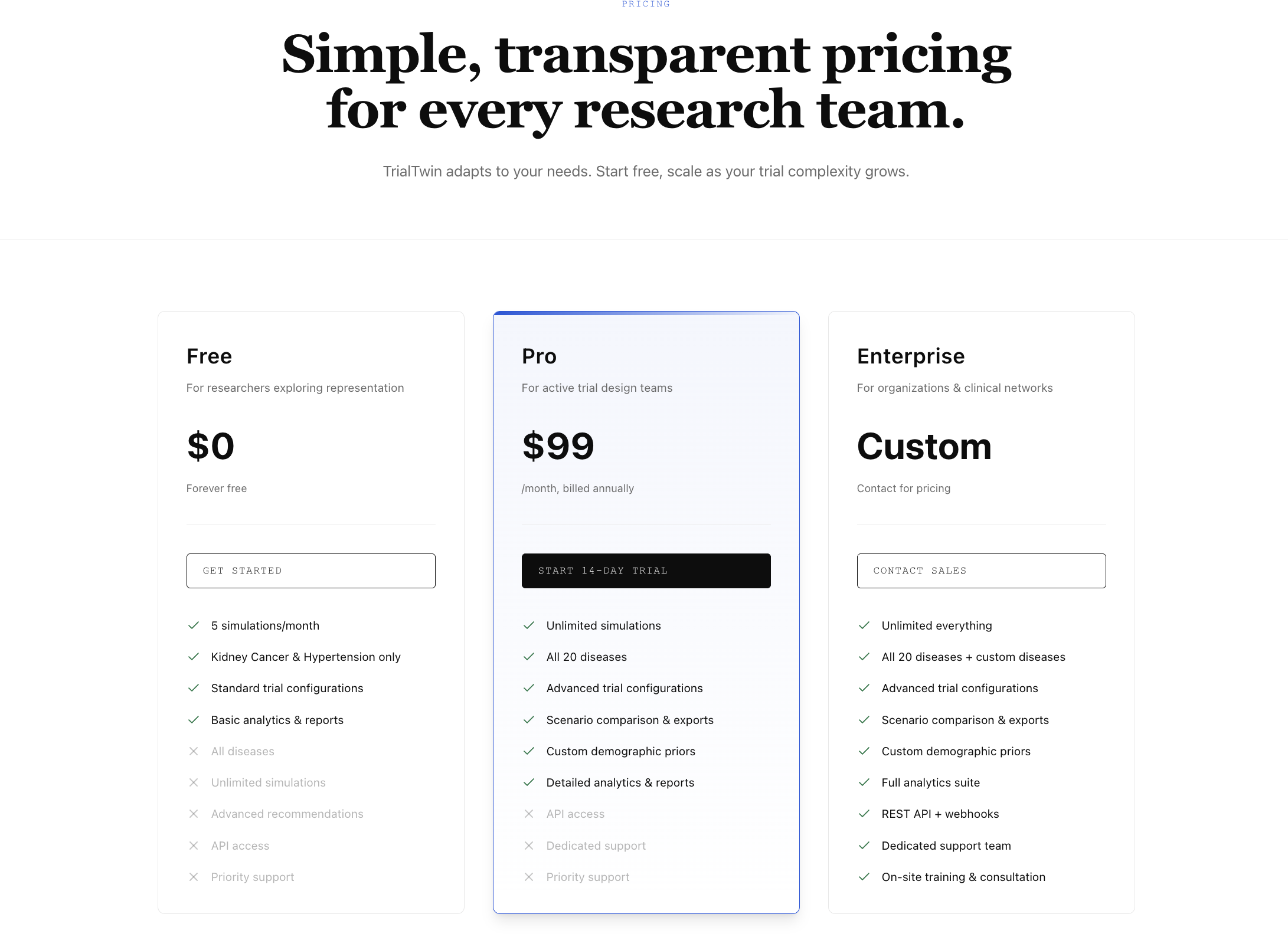
What it does
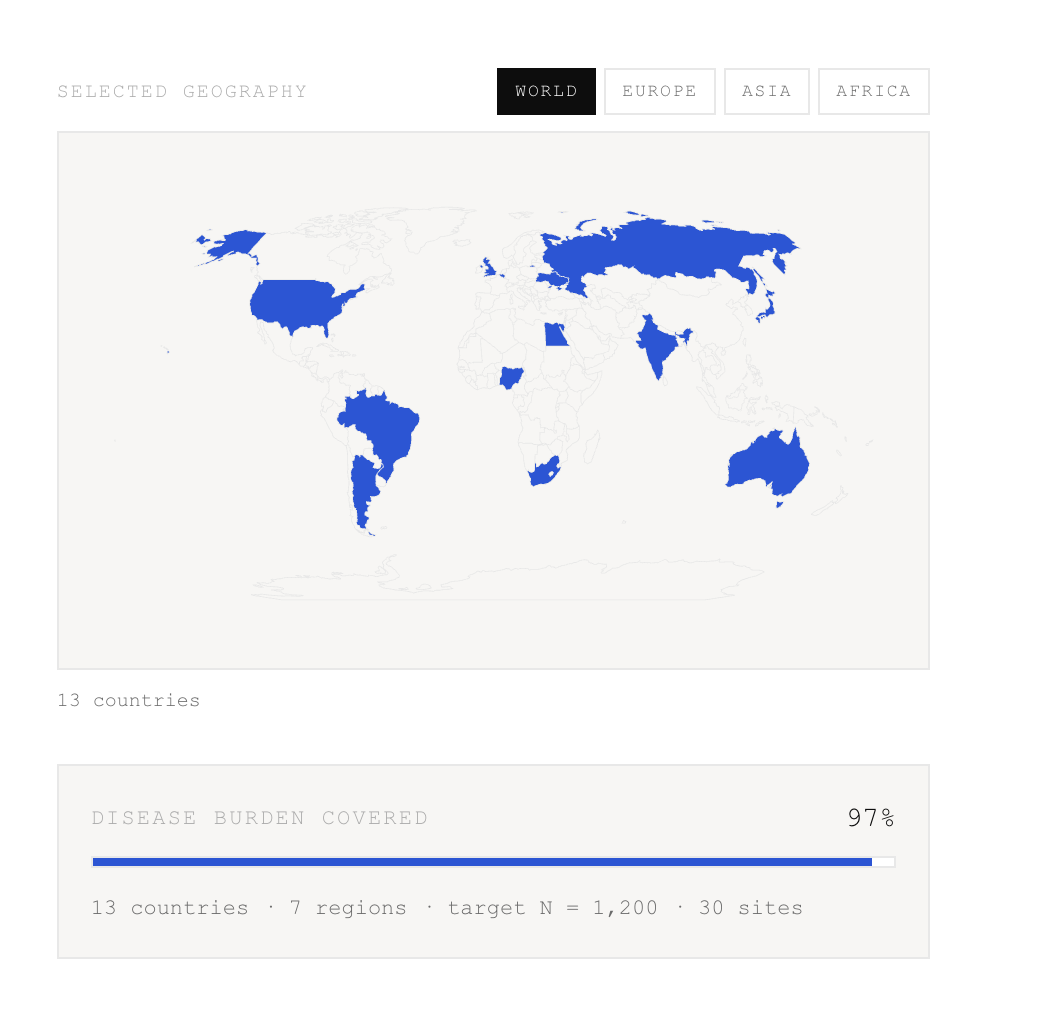
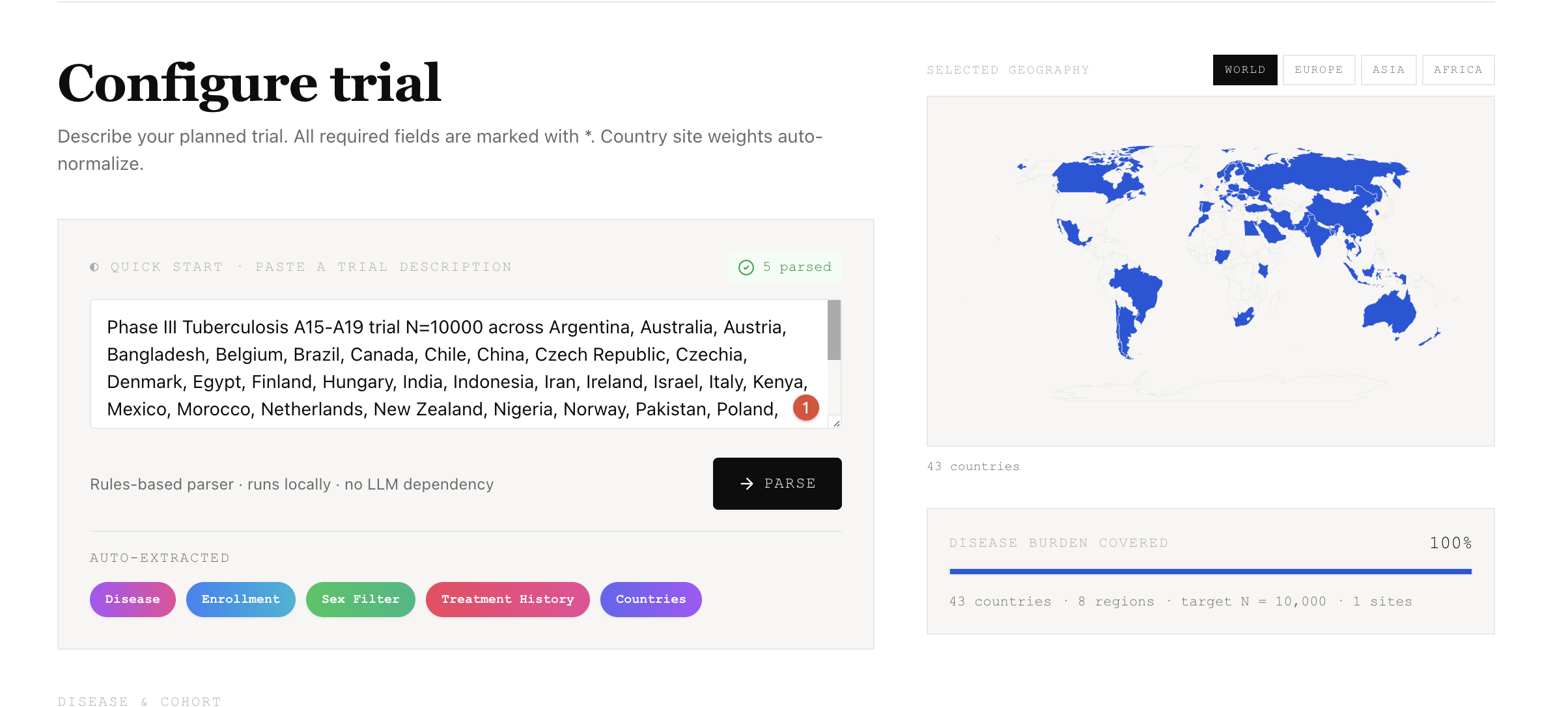
TrialTwin is a pre-recruitment simulator, not a predictor. You configure disease, target N, total sites, countries with weights, and inclusion criteria. The engine runs 10,000 Monte Carlo simulations of site activation, screening, enrollment, and dropout.
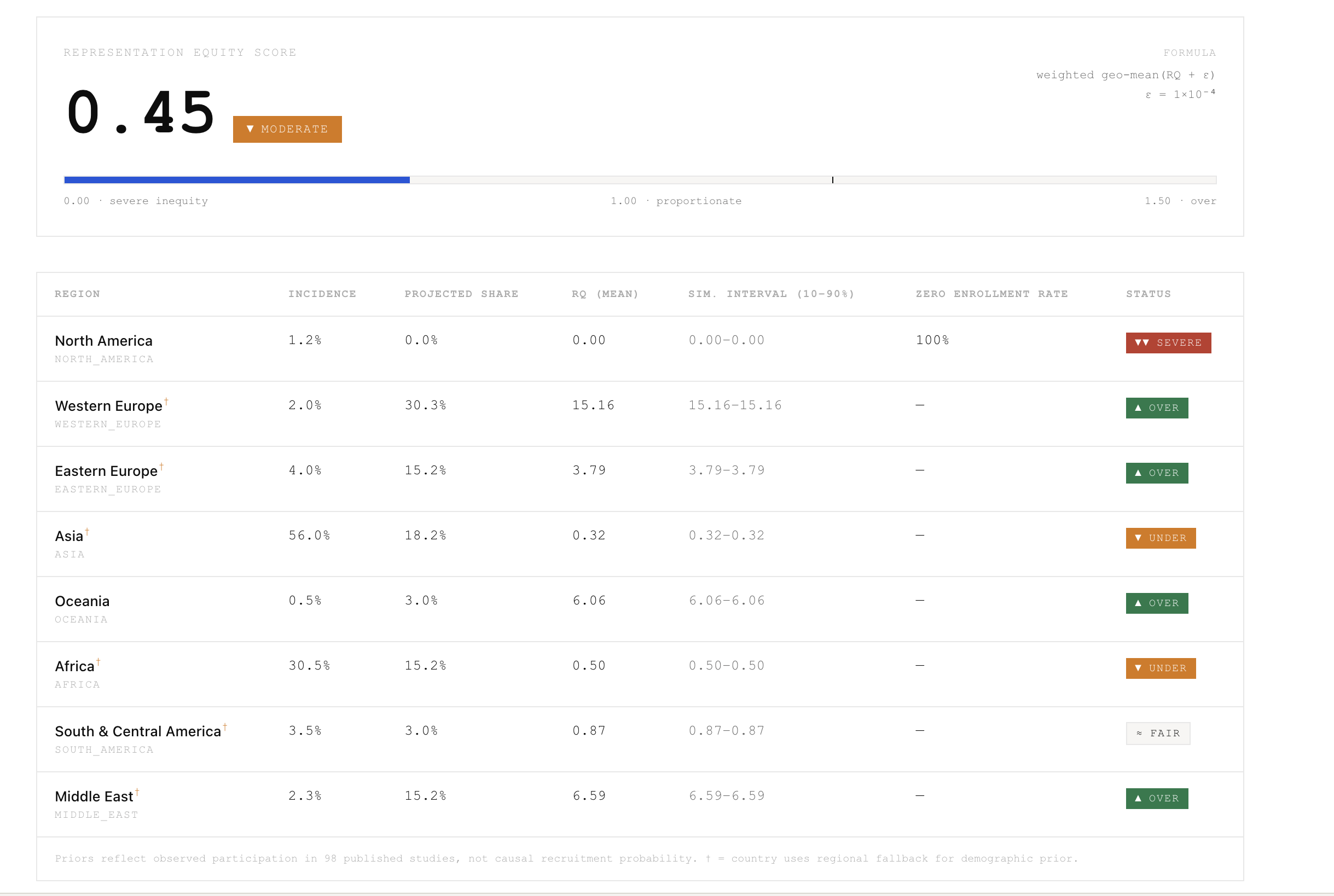
For each region I compute:
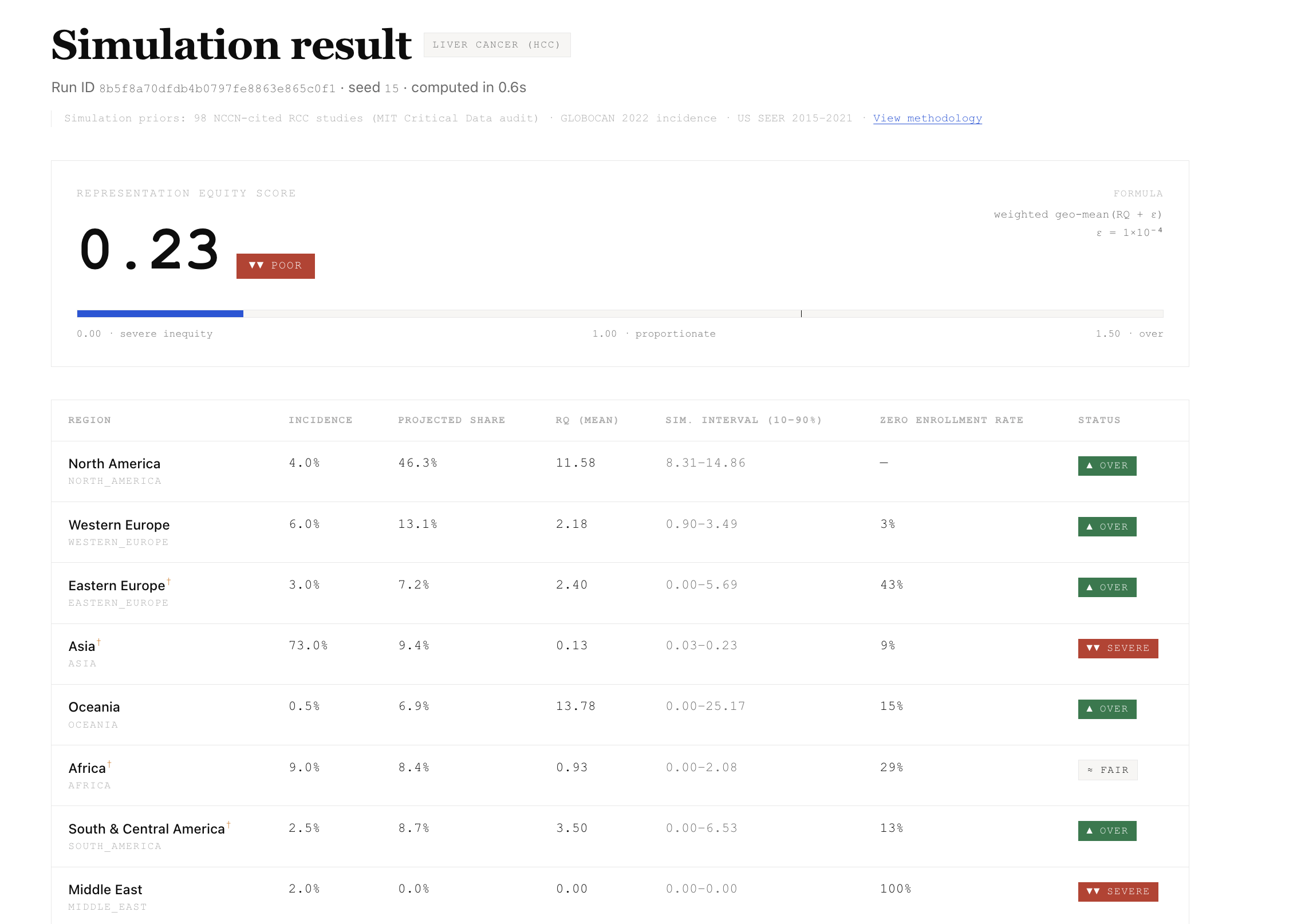
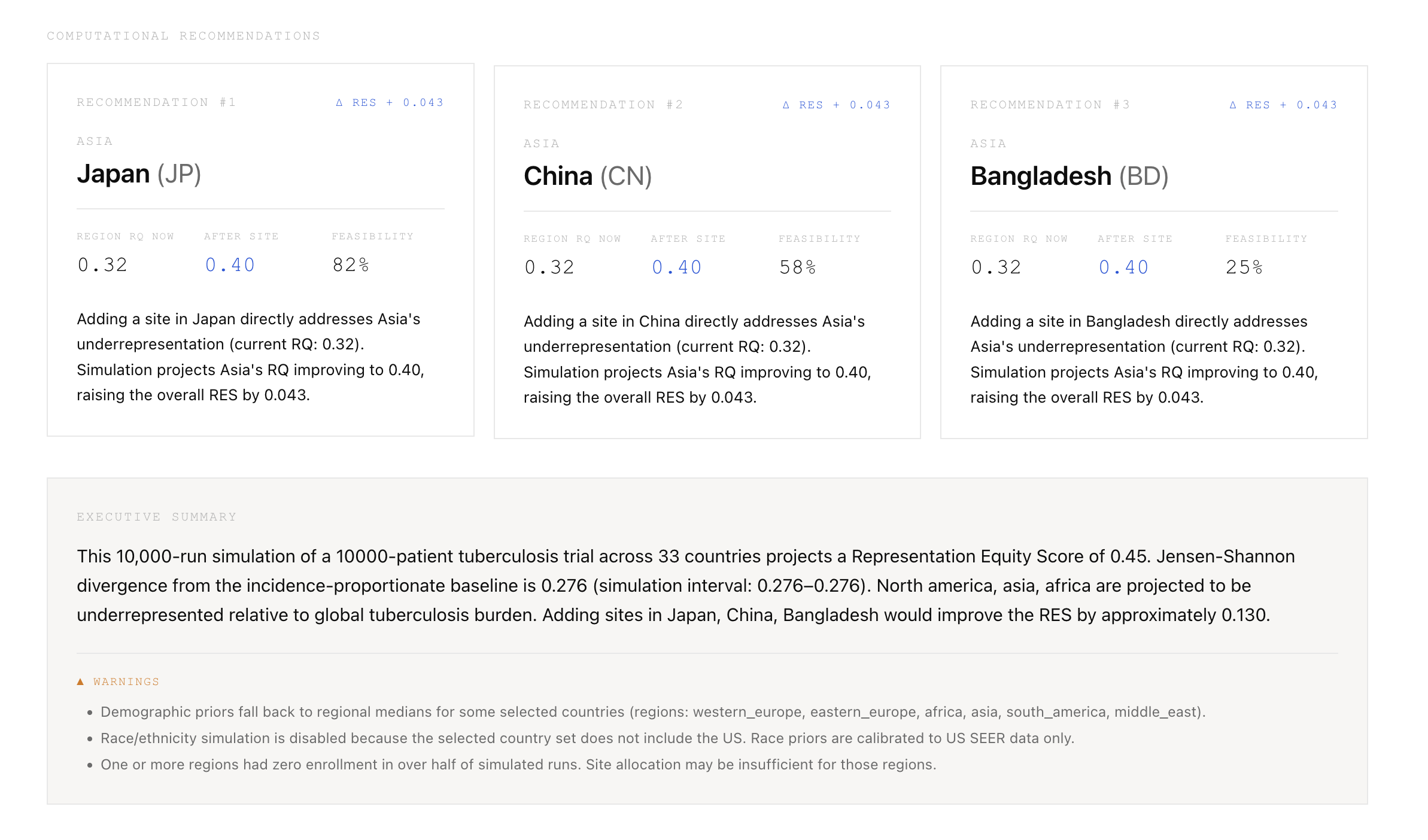
$$ RQ_r = \dfrac{\text{projected enrollment share}_r}{\text{global incidence share}_r} $$
The aggregate Representation Equity Score is a weighted geometric mean that stays finite when a region approaches zero:
$$ RES = \exp\left(\sum_i w_i \ln(RQ_i + \varepsilon)\right) - \varepsilon \quad\text{where } w_i = \text{incidence share}_i,\ \varepsilon = 10^{-4} $$
I report:
- Jensen-Shannon divergence from the incidence-proportionate baseline
- Empirical chi-square exceedance rate across runs (descriptive, not inferential — regional shares are compositional)
- Zero-enrollment rate per region
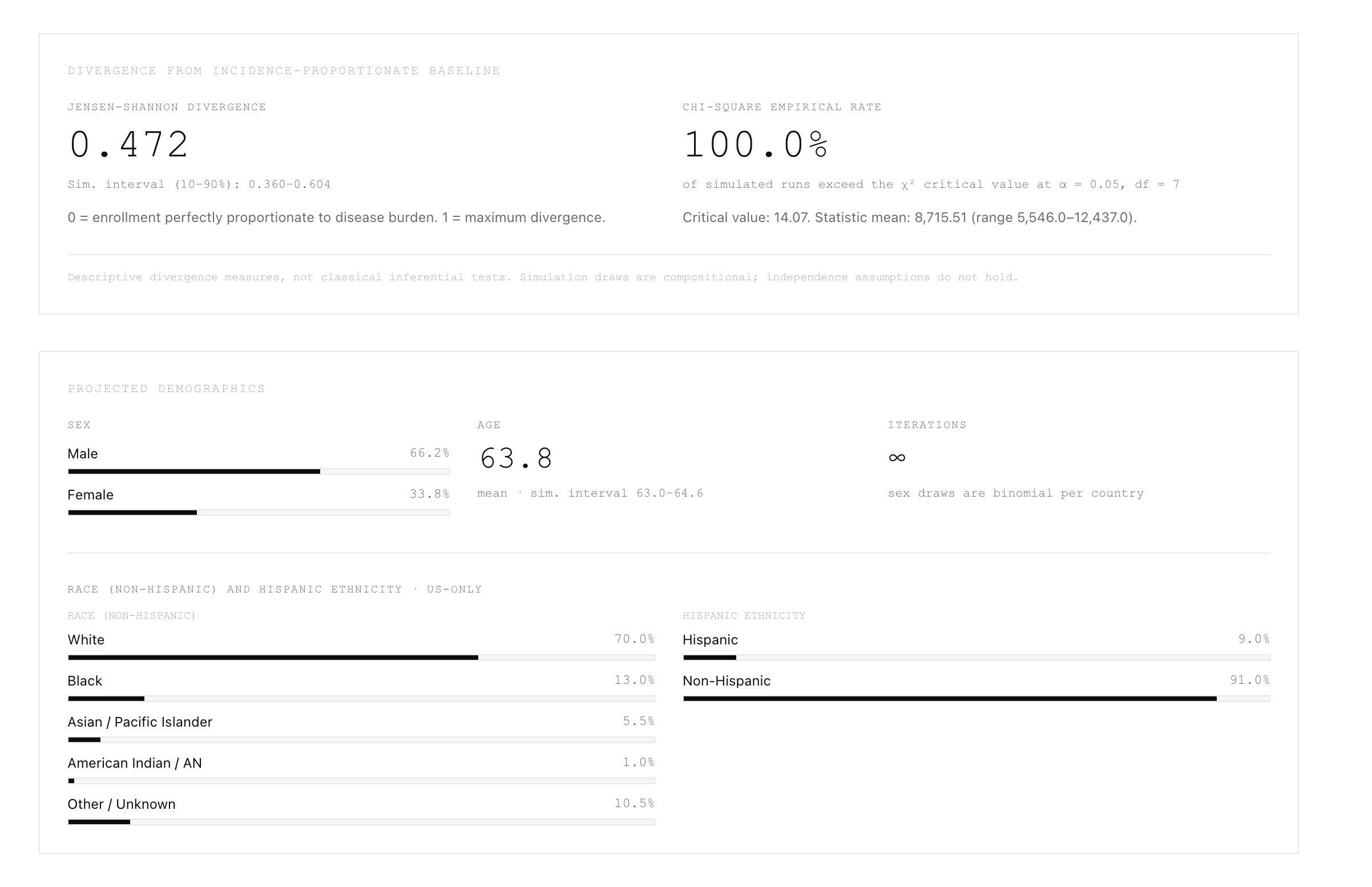
- Simulation interval (10–90%), not a confidence interval
Recommendations are scored computationally: each candidate country is tested with 1,000-run mini-simulations and ranked by \(\Delta RES \times \text{feasibility}\).
Supports 20 diseases (2 audit-calibrated: Kidney Cancer C64, Hypertension I10-I15; 18 generic with GLOBOCAN 2022 incidence) across a 43-country whitelist.
How I built it
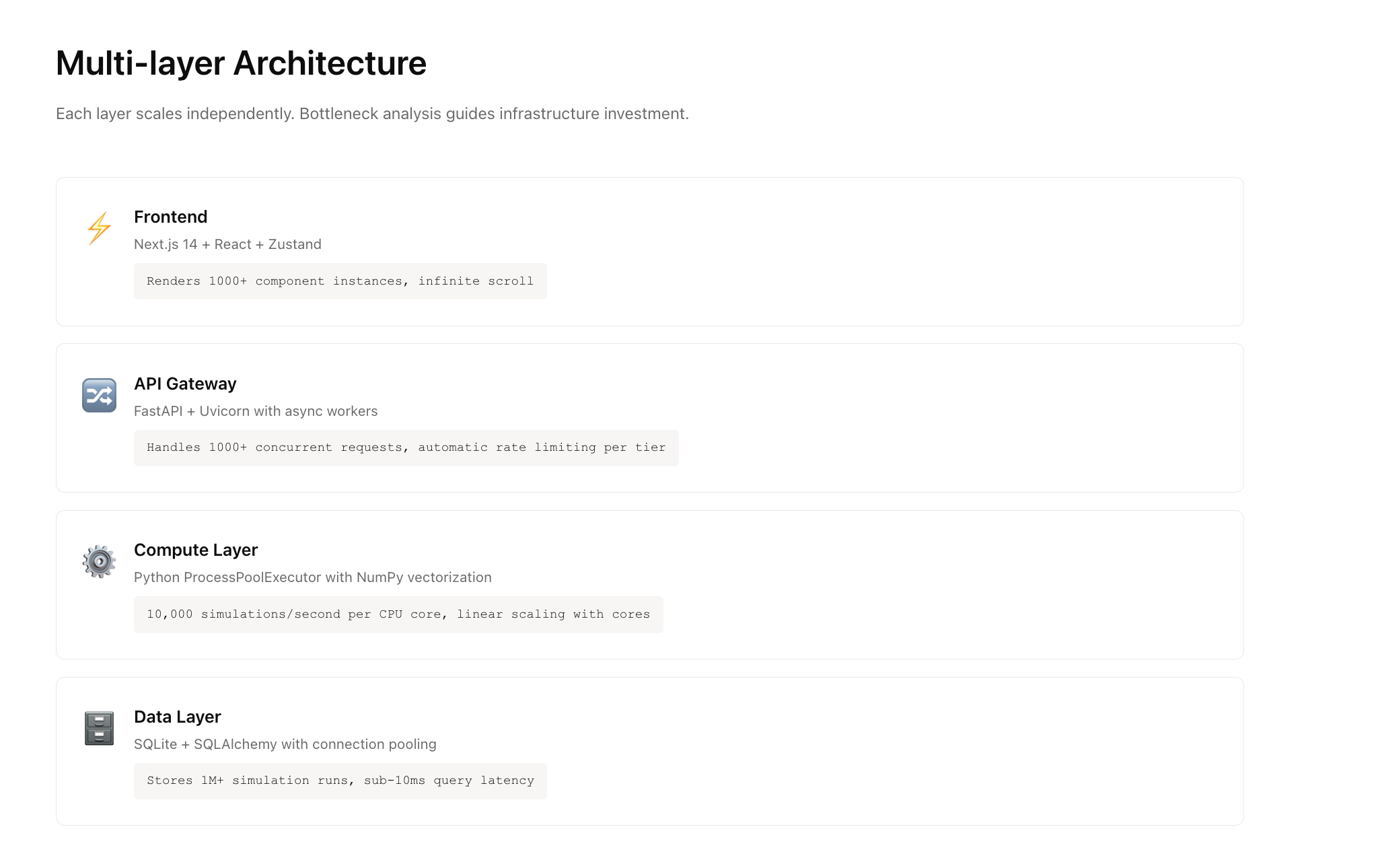
Frontend: Next.js 14 App Router, Tailwind, Zustand, Recharts + D3 choropleth, React Hook Form + Zod. Scientific editorial UI.
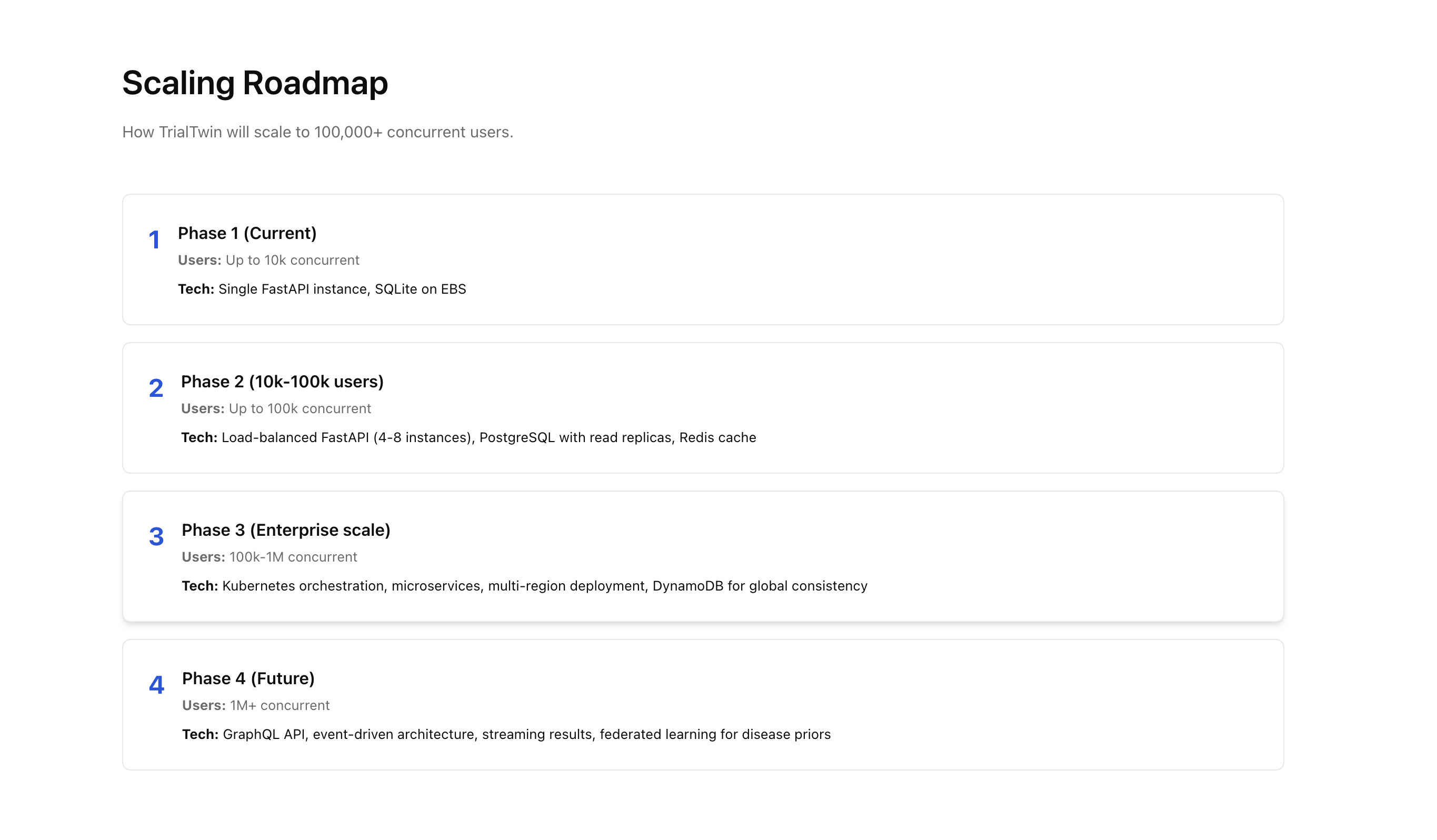
Backend: FastAPI, Python 3.11, NumPy + SciPy vectorized core, ProcessPoolExecutor for CPU-bound runs, Server-Sent Events for live progress, SQLite for run persistence.
Data layer (local JSON only):
disease_priors.json— regional incidence shares normalized to 1.0 for 20 diseasesenrollment_priors.json— country accessibility indices derived from the 98-study auditdemographic_by_disease.json— sex/age priors (US SEER 2015–2021 gated to US-inclusive trials)audit_98_studies.json— source priors for RCC/Hypertension
Engine per run: largest-remainder site allocation → per-site Bernoulli activation → Poisson patient flow → demographic sampling (truncated normal for age, binomial for sex) → pre-sampling inclusion filter → target-N cap via downsampling → RQ/RES.
LLM is off the critical path: rules-based pycountry parser with alias map (GB/UK, KR/Republic of Korea, CZ/Czechia, TR/Turkiye, AE/UAE, VN/Viet Nam), template-first summary, Ollama/Qwen only polishes the 2-sentence rationale.
Challenges I ran into
Statistical theater: ANOVA and Kruskal-Wallis on my own draws returned \(p < 0.001\) by construction. Replaced with JSD and empirical chi-square exceedance.
RES collapse: Harmonic mean drove RES to ∼0 when Africa RQ ≈ 0.07. Switched to weighted geometric mean with epsilon.
Mislabeling: 10th–90th percentiles were called "CI". Relabeled to "Simulation interval (10–90%)".
Trial mechanics: Target N was not enforced; site activation was one Bernoulli per country; age filter ran after sampling (min = max = 90 returned mean 64.3). Fixed with N-cap downsampling, per-site activation, and pre-sampling filters including degenerate age handling.
Parser fragility: Free-text aliases broke ISO validation. Built deterministic alias map + strict 43-code whitelist.
Performance: Per-patient Python loops blocked SSE. Vectorized across runs and chunked updates.
Priors mismatch: Generic diseases briefly showed the RCC audit banner. Added disease-gated prior loading.
Accomplishments that I'm proud of
- Finite, interpretable RES across extreme underrepresentation (no NaN, no 0.00 collapse)
- Honest reporting: zero-enrollment rates surfaced, race panel gated to US-only, generic-priors banner visible
- Deterministic 43-country allocation: 200 sites = exactly 200 via largest-remainder
- Disease switch actually swaps priors (RCC ≠ TB ≠ HCC)
- 10,000-run jobs stream in 5–15s on laptop hardware with second concurrent run supported
- Shareable run IDs with full config and data version audit trail
What I learned
Priors are political. Using published studies as a generative prior bakes historical bias into the model. Compositional outputs violate ANOVA independence — divergence metrics are more honest than p-values. A single epsilon choice dominates RES stability. Labeling matters: calling a percentile a "confidence interval" destroys trust instantly. Rules-based parsing beats LLM cleverness for ISO codes.
What's next for TrialTwin
- Replace independent draws with hierarchical Dirichlet-multinomial to respect regional covariance
- Calibrate accessibility indices against ClinicalTrials.gov completion data, not just publications
- Add cost, regulatory timeline, and site capacity to recommendation scoring
- Export IRB-ready PDF appendix with methods, formulas, data versions, and limitations
- Expand audit-calibrated diseases beyond RCC and Hypertension


Log in or sign up for Devpost to join the conversation.