-
-
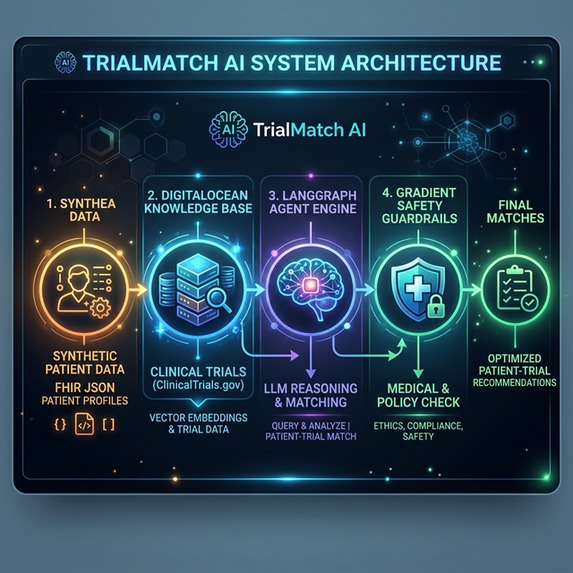
Architechture Diagram
Inspiration
Currently, determining if a single patient qualifies for a complex clinical trial requires a doctor or clinical research coordinator to manually read a 30-page protocol PDF and cross-reference over 20 distinct Electronic Health Record (EHR) data points. This is a tedious, prone-to-error process that slows down critical medical research. While rules-based engines exist, they are far too rigid—failing to handle nuanced, natural-language medical requirements (e.g., "Patient excluded if they had major heart surgery in the last 6 months, unless the surgery was a routine stent").
I was inspired by the "Program for the People" prize to build a solution that replaces this manual work. I wanted to leverage advanced Generative AI to understand the deep context of patient records and trial requirements, transforming a 45-minute administrative review into an automated, intelligent API call.
What it does
TrialMatch AI is an intelligent Site Feasibility and Patient Recruitment Engine. Instead of relying on hard-coded SQL rules or legacy keyword-matching NLP, it uses an Agentic GenAI workflow to evaluate patient simulated EHR data (in FHIR JSON format) against a complex Knowledge Base of clinical trial protocols. Users can:
- Search my simulated patient database by medical condition.
- Select a patient to extract a clean summary of their age, active conditions, medications, and observations.
- Trigger my AI Agent to autonomously query the Knowledge Base of active trials, perform a "Chain of Thought" reasoning process against inclusion/exclusion criteria, and output a structured "Match Score" with a detailed explanation of precisely why a patient qualifies or is disqualified.
How I built it
I built the core application using Python and Streamlit to create an interactive frontend for the clinical workflow. The heavy lifting is powered by the DigitalOcean Gradient AI Platform:
- Knowledge Base: I ingested clinical trial data into DigitalOcean's managed OpenSearch cluster. Gradient automatically handles the embeddings (using GTE Large) to allow for advanced semantic search over the study library.
- Agentic Matching Engine: I utilized the Gradient Python SDK to construct an AI Agent utilizing the
openai-gpt-oss-120bmodel. The backend parses raw FHIR JSON into a clean patient summary and sends it to the Agent. - Prompt Engineering & Reasoning: The Agent is instructed to use "Chain of Thought" reasoning to compare the semantic context of the patient's record against the retrieved trials, providing deep, contextual matching beyond simple keyword overlaps.
- Guardrails: Because I am dealing with (simulated) medical records, I implemented DigitalOcean Guardrails to ensure production-grade safety—preventing the agent from providing unauthorized medical diagnosis and blocking malicious jailbreak attempts.
Challenges I ran into
One of my biggest hurdles was navigating the transition from a pure .NET background to a Python-centric AI orchestration workflow. Additionally, structuring the API calls to the DigitalOcean Agent required precision. I initially encountered authentication and routing errors (401s) when trying to manually construct HTTP requests to the completions endpoint. I overcame this by fully adopting the official Gradient Python SDK (client.chat.completions.create()), which elegantly abstracted the routing and allowed me to authenticate seamlessly using my Model Access Key.
Another conceptual challenge was optimizing my RAG (Retrieval-Augmented Generation) pipeline. I realized that passing thousands of lines of raw FHIR JSON diluted the LLM's attention. I had to build an intermediary extraction step in my backend to summarize the patient data before passing it to the Agent, which drastically improved the accuracy of my Match Scores.
Accomplishments that I'm proud of
I successfully built a true Agentic Workflow, moving beyond a simple chatbot. My Agent doesn't just answer questions; it actively retrieves specific trial documents and performs deep, contextual reasoning that rules-based engines fail to achieve. I am also extremely proud of implementing DigitalOcean Guardrails as a core feature. Demonstrating a functional UI that actively intercepts and blocks malicious prompt injections proves that this application is designed with enterprise-grade medical safety in mind from Day 1.
What I learned
I gained deep, hands-on experience with advanced RAG architectures—specifically the difference between semantic search (finding relevant study concepts) and lexical search (matching specific lab values or medication names). I learned how to write robust System Prompts that enforce structured reasoning, and I experienced firsthand the immense value of using managed ADKs for AI orchestration rather than building API wrappers from scratch.
What's next for TrialMatch AI: Intelligent Site Feasibility
Moving forward, I want to expand the platform's autonomy and integration capabilities:
- Auto-Indexing Pipeline: Implement a web crawler (via DigitalOcean's URL ingest) that automatically polls
ClinicalTrials.govand updates the OpenSearch cluster so my Knowledge Base is always current without manual intervention. - EHR Integration: Build robust adapters to ingest live HL7/FHIR streams directly from Epic or Cerner, fully automating the ingestion of daily patient records.
- Multi-Agent Workflows: Introduce secondary Agents to the mix—for example, a "Compliance Agent" that double-checks the Matching Agent's work before a final recommendation is presented to the trial coordinator.
Built With
- digitalocean
- python
- streamlit

Log in or sign up for Devpost to join the conversation.